各家的“ChatGPT”什么时候能取代程序员?CSDN AI编程榜发布
“人人都是开发者”的时代终于要来临了!
ChatGPT 的出现,引领了科技公司追逐 AI 的浪潮。相比初代 GPT-3,最新基于GPT3.5的模型之所以受到更加广泛的关注,主要原因之一便是它在加入了代码作为训练数据后,彻底颠覆了传统模型较弱的思维链推理能力,大大地提升了模型的推理能力。因此,这也催生了多款针对开发者的辅助和革命性工具。
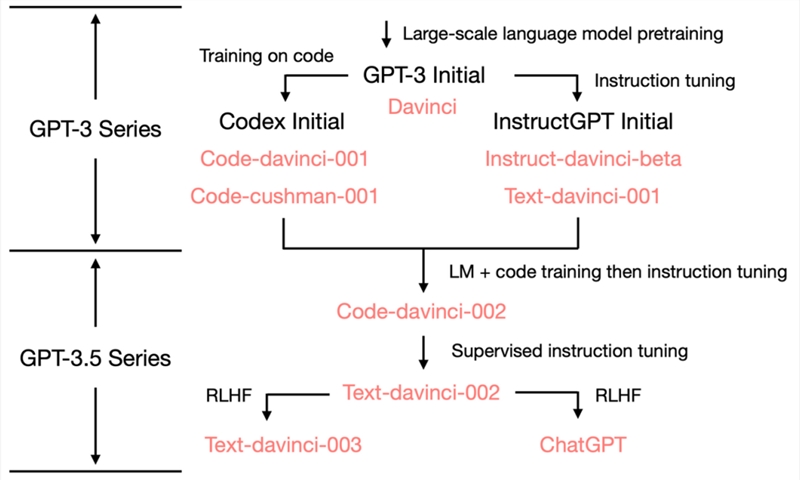
GPT3.5加入了代码作为训练数据后,大大地提升了推理能力
为给广大开发者推荐更多好用的辅助(Ti Dai)工具,CSDN 重磅发起“CSDN AI 编程榜单”,定期针对业界主流的 AI Coding 产品进行评测。本期榜单中,我们共选择了六款 AI Coding 产品,分别是:ChatGPT、GPT3.5、CodeBBT、GitHub Copilot、CodeGeeX、aiXcoder。
话不多说,我们先看评测得到的关键性结论:
ChatGPT 以几乎接近满分的成绩,摘得榜首,成为开发者辅助编码的最佳神器;
目前尚未有任何一款产品达到 C4(高度自动编程)级别,即,想要在没有任何的人工干预下,生成理想中的代码也还存在一定的困难,正因此,至少就当前阶段而言,“程序员即将被 AI 所取代”的传言也并不可信;
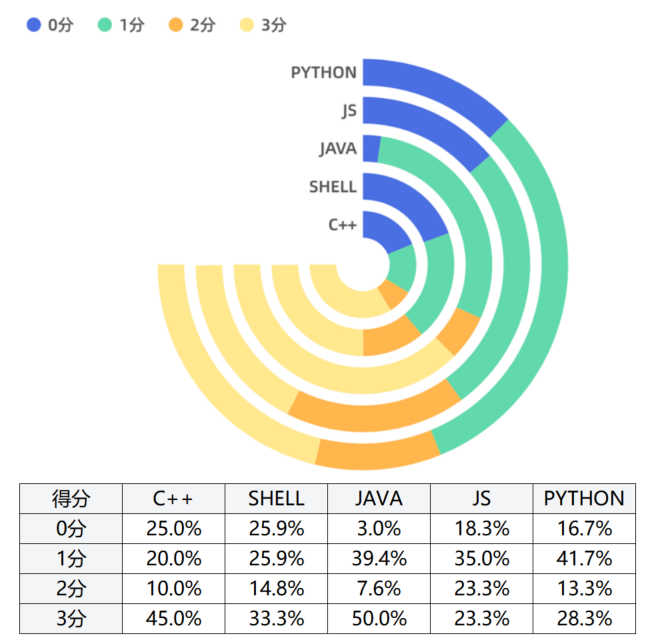
C 和 Java 在各模型的3分占比高于 Javascript、Python 及 Shell,这意味着各大模型对 C 和 Java 语言支持要优于其他几种语言。
注:本次评测为了快速获取评测结论,从生成任务数据集到评分/评级若有遗漏和不足之处,望各位大佬斧正。也欢迎本次没有覆盖到的产品联系我们(kefu@csdn.net),加入评测。
AI 编程究竟哪家强?我们一起来评测
首先,根据流行度、发布时间、智能化等维度,我们选取了如下六款产品作为评测对象:
GPT-3.5,是 OpenAI 在GPT-3基础上微调出来的版本,它采用了与 GPT-3不同的训练方式,所产生出来不同的模型,比起 GPT-3来的更强大。
GitHub Copilot(https://github.com/features/copilot),是GitHub 和 OpenAI 于2021年6月推出的人工智能工具,它可以根据命名或者正在编辑的代码上下文为开发者提供代码建议。
GPT-3.5-Turbo(ChatGPT)(https://openai.com/blog/chatgpt),是 OpenAI 于2022年11月推出的人工智能聊天机器人程序。该程序使用基于 GPT-3.5-Turbo 架构的大型语言模型并以强化学习训练。ChatGPT 目前仍以文字方式交互,而除了可以用人类自然对话方式来交互,还可以用于甚为复杂的语言工作,包括自动生成文本、自动问答、自动摘要等多种任务。
CodeGeeX(https://github.com/THUDM/CodeGeeX/blob/main/README_zh.md),是智谱 AI 联合清华、华为发布的代码生成模型,它是一个具有130亿参数的多编程语言代码生成预训练模型。采用华为 MindSpore 框架实现,在鹏城实验室“鹏城云脑II”中的192个节点(共1536个国产昇腾910AI 处理器)上训练而成。
CodeBBT,是超对称技术公司近期发布的 BBT-2大模型系列中的代码模型。继2022年6月发布10亿参数的 BBT-1金融大模型后,超对称公司接续研发了120亿参数的通用语言大模型 BBT-2,并在 BBT-2的基础上训练中英文代码数据,推出面向中文开发者的代码模型 CodeBBT。
aiXcoder(https://www.aixcoder.com),是硅心科技研发的国内首款基于深度学习的智能化软件开发工具,利用 AI 技术实现代码?动?成、代码?动补全、代码智能搜索等功能,提升开发者开发效率与代码质量。
基于以上 AI 辅助代码工具,在生成任务的选取中,生成任务语言以中文自然语言环境为主。测试集包含了 C 、 Java、 Javascript 、Python 和 Shell5种主流的开发语言。另外,以开发者在 CSDN 平台上的 Text→Code(Code→Text)、Troubleshooting、命令行等高频需求为生成任务。评测同一个 Query 在不同模型搜索返回结果的效果,并选择50个 CSDN 搜索高频 Query。
CSDN 发布C1-C5级自动编程评测方法与标准
为了更直观地看出不同产品之间的区别,我们模仿自动驾驶的 L1-L5级别划分,将自动编程分成了 C1-C5级别。

倘若能够达到 C5级别,那么也可以畅想一下未来:产品经理能够直接用自然语言写成的需求文档作为输入,自动生成代码、自动化测试、自动化部署上线等。
当然,自动驾驶也分路况,自动化编程也会分“路况”,在此,我们也将每一档划分了相应的分值:
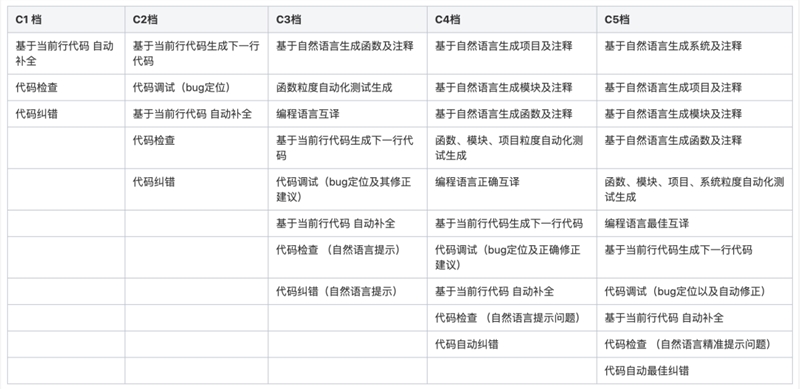
*说明:评分涉及的编程语言指主流编程语言 Java、C/C 、Javascript、Python和Shell
单条 Query→内容打分规则
3分:有正确输出,能直接解决问题
2分:有错误输出,不能直接解决问题,但输出可参考
1分:有输出但不能解决问题,输出不可参考
0分:无输出
评测三步走
本次的测试集主要是 CSDN 上用户主要在 AI Coding 上的高频需求同时兼顾对主流编程语言的覆盖,可能不能完全体现各个产品/模型的性能,并且上述产品是针对不同的场景来设计的,所以在不同的“路况”下,表现会有差别,例如 Copilot 和 CodeGeex 就是专门为 IDE 环境设计的辅助开发工具,所以在代码生成方向很强,但是 Troubleshooting 上就会差一些,可能不是没有这个能力,而是针对性设计的结果。
因为所有产品均未达到 C4,故所选的测试集均为 C4级别以下的数据。同时我们以真实的用户需求为评估方向,因此我们以C3代码生成和代码调试展开评估以及阐述。
具体评测步骤按下面评分对各项打分求和即是模型最终得分,再根据模型档位对应的分数范围将模型划分到对应档位。
1. 函数级别的代码生成、代码分析的评分,对应分数作为在 C3等级的评分
单条评分加和,具体单条评分如下,其评分规范参见上文第二部分:
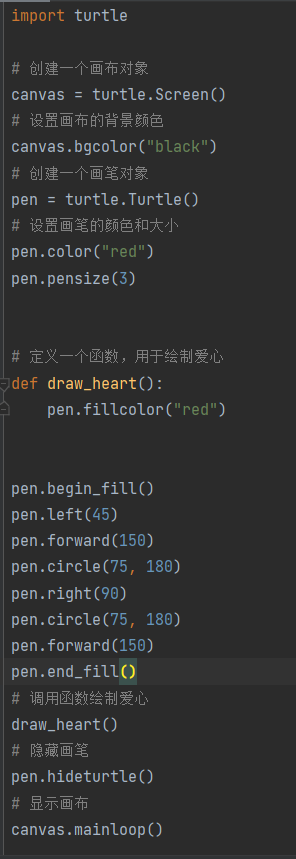
在遵循此步骤的基础上,我们以生成一个「Python 爱心代码」为例,不妨先看看每种模型的表现情况:
模型:GPT-3.5-Turbo(ChatGPT)
得分:3分
输出内容如下:
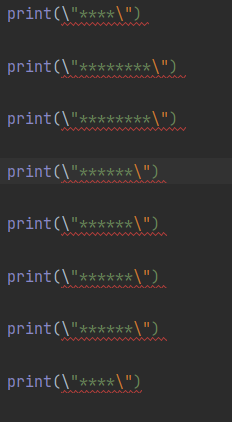
模型:GPT3.5
得分:2分
输出内容如下:
模型:CodeBBT(超对称)
得分:3分
输出内容如下:
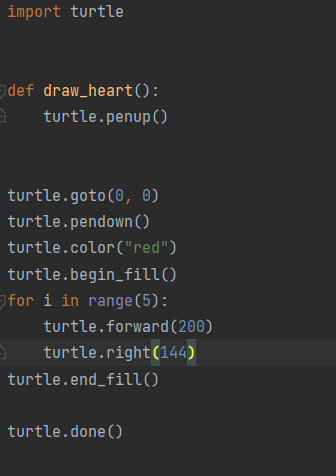
模型:Copilot(vscode插件)
得分:3分
输出内容如下:
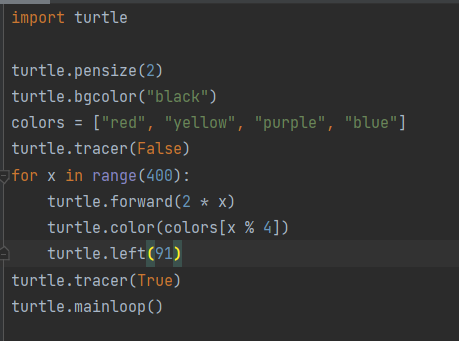
模型:CodeGeeX(智谱)
得分:1分
输出内容如下:
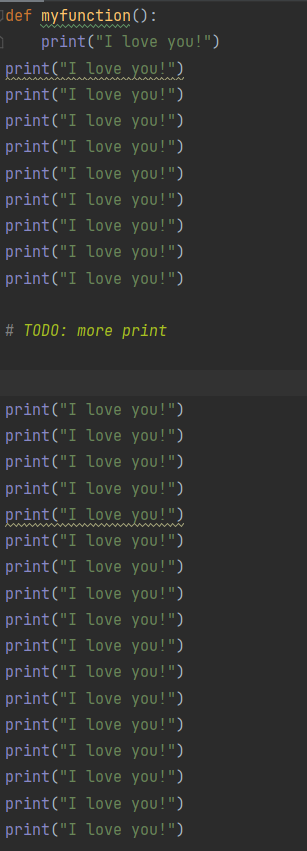
模型:aiXcoder
得分:1分
输出内容如下:
那么,生成代码和捉 Bug 能力是否相一致?
为了证明不同模型之间的能力,我们又从 Troubleshooting 类入手,如用 java.lang.illegalstateexception: failed to load applicationcontext 异常的代码问题,进行评测:
模型:GPT-3.5-Turbo(ChatGPT)
得分:3分
输出内容:
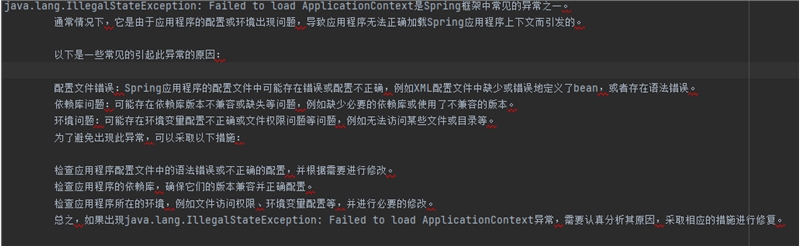
模型:GPT3.5
得分:2分
输出内容如下:
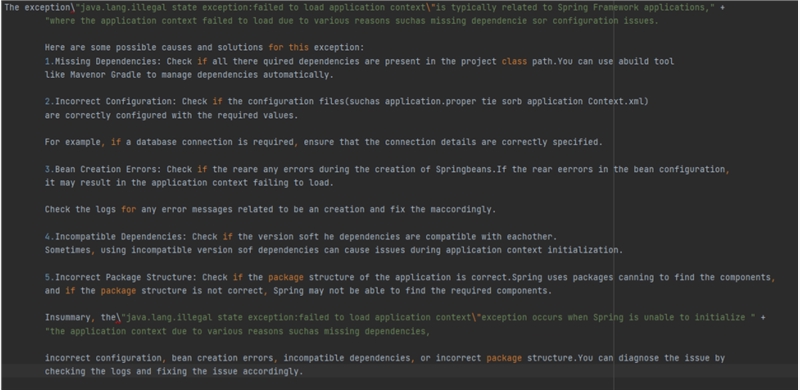
模型:CodeBBT(超对称)
得分:1分
输出内容如下:
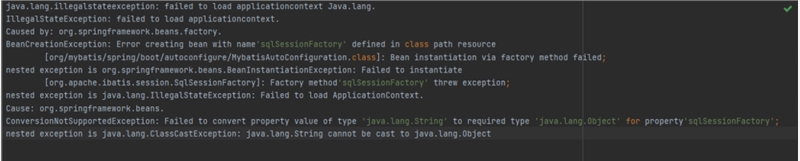
模型:Copilot(vscode插件)
得分:1分
输出内容如下:

模型:CodeGeeX(智谱)
得分:1分
输出内容如下:
模型:aiXcoder
得分:0分
无输出

评测结果出炉:ChatGPT 一马当先,国产化 AI 工具还有较大的差距!
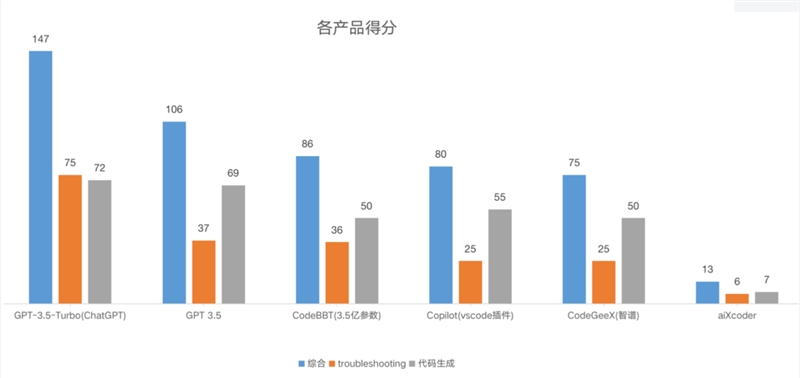
几经测试之后,最终得出各产品档位得分(150分制)情况如下:

*说明:GitHub Copilot(vscode插件)的 VSCode 版本为:1.75.1;GitHub Copilot:v1.76.9071
各产品分项得分(150分制)
本次评测结果中,ChatGPT 名列前茅,aiXcoder 排名最末位,其他几个产品水平相差无几。

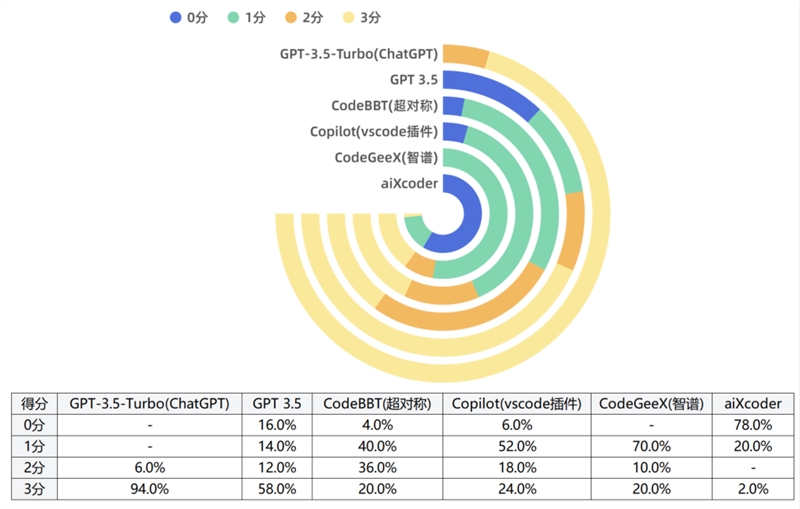
各产品的分数分布
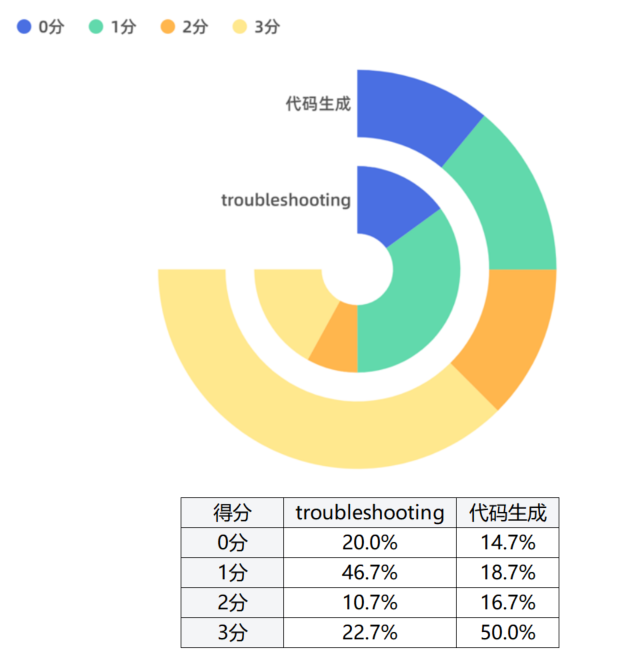
不同测试集的分数分布
不同编程语言类型的分数分布
主要结论:
各产品得分最高为 GPT-3.5-Turbo(ChatGPT),得分最低为 aiXcoder,因此在提供辅助代码的智能化方面,ChatGPT 的表现最佳;
0分占比最多为 aiXcoder,3分占比最多为 GPT-3.5-Turbo(ChatGPT);
代码生成类型的 Query 得分高于 troubleshooting 类型的 Query;
C 和 Java 在各模型的3分占比高于 Javascript、Python 及 Shell;
CodeBBT(超对称)对比 GPT-3.5-Turbo(ChatGPT)的 GSB(GOOD、SAME、BAD)条数为:0:10:40,这意味着国产的 AI 编程工具和领先的 ChatGPT 之间还存在一定的差距,有不少的上升空间。
写在最后
本次评测中,ChatGPT 出类拔萃,几乎接近满分,大家追赶ChatGPT的步伐任重而道远。有些遗憾的是,所有的产品都均未达到 C4级别,离 C5也还有很长的路要走。
然而,AI 一旦踏上了这个方向,必然势不可挡,人人都是开发者的时代也许就在不远的将来。作为开发者社区,CSDN 也将持续致力于 AI 编码工具的研究与关注,敬请期待下期评测内容。
- 0001
 0000
0000- 0001
- 0000


