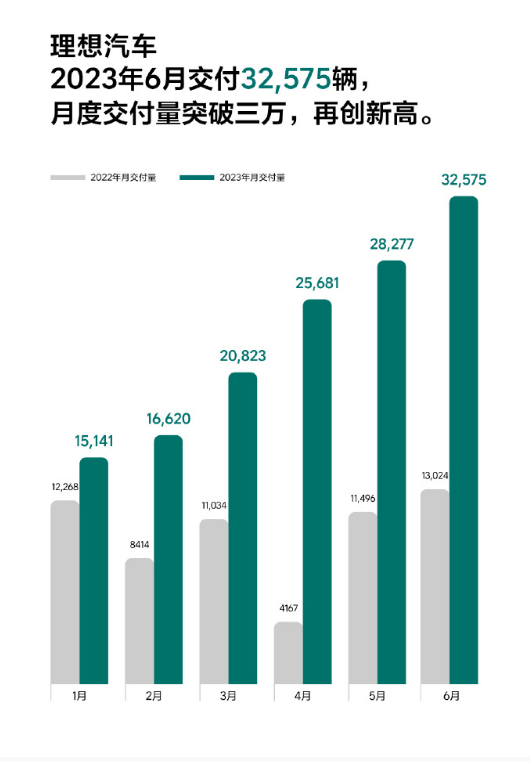
复旦大学团队发布中文医疗健康个人助手DISC-MedLLM 单轮问答和多轮对话均表现亮眼
复旦大学数据智能与社会计算实验室(FudanDISC)发布了中文医疗健康个人助手DISC-MedLLM。该模型在单轮问答和多轮对话的医疗健康咨询评测中表现出色,相比已有医学对话模型具有明显优势。课题组同时公开了包含47万高质量监督微调样本的DISC-Med-SFT数据集,以及模型参数和技术报告。
DISC-MedLLM的三大特点:
1)可靠丰富的专业知识,基于医学知识图谱采样获得;
2)多轮对话的问询能力,基于真实咨询对话重建;
3)对齐人类偏好的回复,通过筛选生成高质量小样本指导模型。DISC-Med-SFT数据集利用通用大模型的语言能力,围绕这三个方面进行针对性强化。

主页地址:https://med.fudan-disc.com
Github 地址:https://github.com/FudanDISC/DISC-MedLLM
技术报告:https://arxiv.org/abs/2308.14346
研究团队采用两阶段训练方法。第一阶段使用MedDialog、cMedQA2等数据集进行监督微调,同时加入通用数据集增强语言表达能力。第二阶段使用行为偏好小样本数据集进行微调,进一步提高模型表现。

在单轮问答评测中,DISC-MedLLM在零样本设置下表现强劲,在小样本设置下仅次于GPT-3.5,优于专业医学问答模型HuatuoGPT。在多轮对话评测中,研究团队采用多种策略构建高质量的DISC-Med-SFT数据集:
1)重构AI医患对话。从MedDialog和cMedQA2中抽取样本,使用GPT-3.5重构对话,调整回复风格使其符合AI助手。
2)知识图谱问答。基于医学知识图谱CMeKG进行三元组采样,生成专业医学问答样本。
3)行为偏好样本。人工筛选MedDialog和cMedQA2中的高质量样本,使用GPT-3.5生成符合人类行为偏好的样本。
4)通用数据。加入通用数据集样本,增强模型基础语言能力。
5)问答样本。使用英文医学问答数据集生成中文医学问答样本。
研究人员计算真实咨询分布,以此指导样本构造,并利用回路和人在回路两种思路生成样本,使数据集质量和多样性显著提高。
DISC-MedLLM弥补了现有模型在医疗知识、对话技能和人类偏好方面的不足,展示了构建高质量领域特定数据集以及数据集驱动方法培训专业对话模型的有效性。
- 0001
- 0000
- 0000
- 0000

 0000
0000