DeepMind研究人员提出ReST算法:用于调整LLM与人类偏好对齐
文章概要:
1. ReST是一种新方法,通过成长式批量强化学习来调整大型语言模型与人类偏好保持一致。
2. ReST使用基于奖励模型的评分函数来过滤策略生成的样本,奖励模型通过学习人类偏好得到。
3. ReST内循环使用离线强化学习目标(如DPO)进行策略优化,外循环通过采样增长数据集。
近年来,大型语言模型在生成流畅文本和解决各种语言任务上展现出惊人的能力。但是,这些模型并不总是与人类的偏好和价值观相一致,如果不加以适当指导,可能会生成有害或不合需求的内容。如果将语言模型与人类偏好对齐,既可以提高模型在下游任务上的表现,也可以改善模型的安全性。
为此,DeepMind的研究人员提出了一种称为Reinforced Self-Training(ReST)的新方法,旨在将语言模型与人类偏好对齐。ReST受成长式批量强化学习的启发,包含内外两个循环:内循环在给定数据集上改进策略,外循环通过从最新策略中采样来增长数据集。
具体来说,ReST使用基于奖励模型的评分函数来对策略生成的样本进行排名和过滤。奖励模型通过从各种源头(比如评分、排序、比较)收集人类偏好进行训练。评分函数还可以结合其他因素,比如样本的多样性或长度惩罚,以确保数据集的平衡。
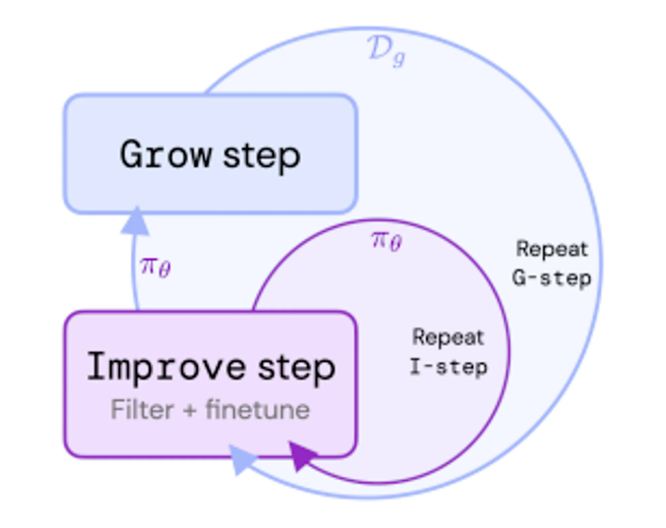
ReST 可以在内部循环中使用不同的离线 RL 目标:ReST 是一种通用方法,可以在内部循环中使用任何离线 RL 目标,例如 DPO(直接偏好优化)、BCQ(批处理约束 Q 学习)或 CQL(保守 Q 学习)。研究人员在几项任务上比较了这些目标,发现DPO在大多数情况下表现最佳。
ReST是一种使用不断增长的批量RL使LLM与人类偏好保持一致的新方法。与现有的RLHF方法相比,ReST具有几个优势,例如计算效率,数据质量和奖励黑客的鲁棒性((Robustness))。
ReST可以提高LLM在各种任务上的性能和安全性。。ReST可以提升语言模型在诸如机器翻译、摘要生成或对话生成等任务上的性能和安全性。同时,ReST也很简单易实现,只需要能对模型进行采样和评分即可。
ReST简单易行。ReST 几乎没有需要调整的超参数,并且简单可靠。ReST 只需要能够从模型中采样并对其要实现的样本进行评分。
- 0000

 0000
0000- 0001
- 0001
- 0000