你有没深入想过,什么造成了GPT-4的输出很随机?
Google Deepmind 可能早就意识到了这个问题。
今年,大型语言模型(LLM)成为 AI 领域最受关注的焦点,OpenAI 的 ChatGPT 和 GPT-4更是爆火出圈。GPT-4在自然语言理解与生成、逻辑推理、代码生成等方面性能出色,令人惊艳。
然而,人们逐渐发现 GPT-4的生成结果具有较大的不确定性。对于用户输入的问题,GPT-4给出的回答往往是随机的。
我们知道,大模型中有一个 temperature 参数,用于控制生成结果的多样性和随机性。temperature 设置为0意味着贪婪采样(greedy sampling),模型的生成结果应该是确定的,而 GPT-4即使在 temperature=0.0时,生成的结果依然是随机的。
在一场圆桌开发者会议上,有人曾直接向 OpenAI 的技术人员询问过这个问题,得到的回答是这样的:「老实说,我们也很困惑。我们认为系统中可能存在一些错误,或者优化的浮点计算中存在一些不确定性......」
值得注意的是,早在2021年就有网友针对 OpenAI Codex 提出过这个疑问。这意味着这种随机性可能有更深层次的原因。
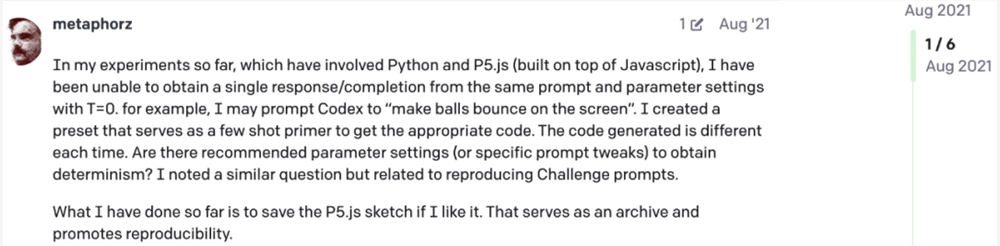
图源:https://community.openai.com/t/a-question-on-determinism/8185
现在,一位名为 Sherman Chann 的开发者在个人博客中详细分析了这个问题,并表示:「GPT-4生成结果的不确定性是由稀疏 MoE 引起的」。
Sherman Chann 博客地址:https://152334h.github.io/blog/non-determinism-in-gpt-4/
Sherman Chann 这篇博客受到了 Google DeepMind 最近一篇关于 Soft MoE 的论文《From Sparse to Soft Mixtures of Experts》启发。

论文地址:https://arxiv.org/pdf/2308.00951.pdf
在 Soft MoE 论文的2.2节中,有这样一段描述:
在容量限制下,所有稀疏 MoE 都以固定大小的组来路由 token,并强制(或鼓励)组内平衡。当组内包含来自不同序列或输入的 token 时,这些 token 通常会相互竞争专家缓冲区中的可用位置。因此,模型在序列级别不再具有确定性,而仅在批次级别(batch-level)具有确定性,因为某些输入序列可能会影响其他输入的最终预测。

此前,有人称 GPT-4是一个混合专家模型(MoE)。Sherman Chann 基于此做出了一个假设:
GPT-4API 用执行批推理(batch inference)的后端来托管。尽管一些随机性可能是因为其他因素,但 API 中的绝大多数不确定性是由于其稀疏 MoE 架构未能强制执行每个序列的确定性。
也就是说,Sherman Chann 假设:「稀疏 MoE 模型中的批推理是 GPT-4API 中大多数不确定性的根本原因」。为了验证这个假设,Sherman Chann 用 GPT-4编写了一个代码脚本:
importosimportjsonimporttqdmimportopenaifromtimeimportsleepfrompathlibimportPathchat_models=["gpt-4","gpt-3.5-turbo"]message_history=[{"role":"system","content":"Youareahelpfulassistant."},{"role":"user","content":"Writeaunique,surprising,extremelyrandomizedstorywithhighlyunpredictablechangesofevents."}]completion_models=["text-davinci-003","text-davinci-001","davinci-instruct-beta","davinci"]prompt="[System:Youareahelpfulassistant]\n\nUser:Writeaunique,surprising,extremelyrandomizedstorywithhighlyunpredictablechangesofevents.\n\nAI:"results=[]importtimeclassTimeIt:def__init__(self,name):self.name=namedef__enter__(self):self.start=time.time()def__exit__(self,*args):print(f"{self.name}took{time.time()-self.start}seconds")C=30#numberofcompletionstomakepermodelN=128#max_tokens#Testingchatmodelsformodelinchat_models:sequences=set()errors=0#althoughItrackerrors,atnopointwereanyerrorseveremittedwithTimeIt(model):for_inrange(C):try:completion=openai.ChatCompletion.create(model=model,messages=message_history,max_tokens=N,temperature=0,logit_bias={"100257":-100.0},#thisdoesn'treallydoanything,becausechatmodelsdon'tdo<|endoftext|>much)sequences.add(completion.choices[0].message['content'])sleep(1)#cheaplyavoidratelimitingexceptExceptionase:print('somethingwentwrongfor',model,e)errors =1print(f"\nModel{model}created{len(sequences)}({errors=})uniquesequences:")print(json.dumps(list(sequences)))results.append((len(sequences),model))#Testingcompletionmodelsformodelincompletion_models:sequences=set()errors=0withTimeIt(model):for_inrange(C):try:completion=openai.Completion.create(model=model,prompt=prompt,max_tokens=N,temperature=0,logit_bias={"50256":-100.0},#preventEOS)sequences.add(completion.choices[0].text)sleep(1)exceptExceptionase:print('somethingwentwrongfor',model,e)errors =1print(f"\nModel{model}created{len(sequences)}({errors=})uniquesequences:")print(json.dumps(list(sequences)))results.append((len(sequences),model))#Printingtableofresultsprint("\nTableofResults:")print("Num_Sequences\tModel_Name")fornum_sequences,model_nameinresults:print(f"{num_sequences}\t{model_name}")
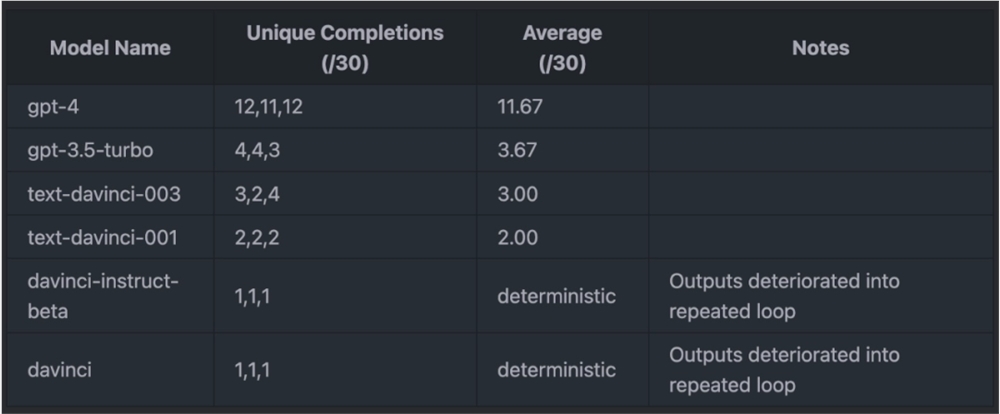
当 N=30,max_tokens=128时,结果如下表所示:
在 Sherman Chann 注意到 logit_bias 问题之前,还得到了如下结果(max_tokens=256):
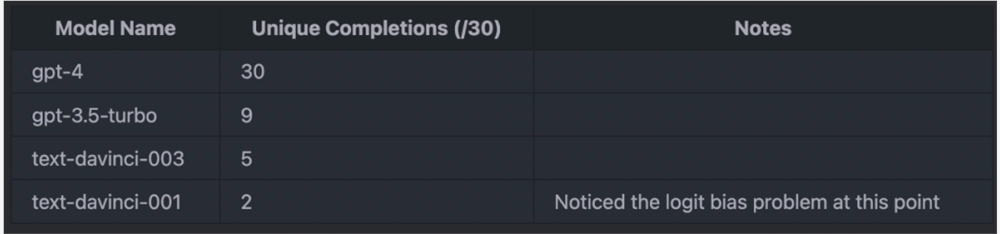
实验结果表明,GPT-4的输出总是不确定的(unique completion 数值很高,表明对于相同的输入,GPT-4生成的输出总是不同的),这几乎可以证实 GPT-4存在问题。并且,所有其他不会陷入重复无用循环的模型也存在某种程度的不确定性。这似乎说明不可靠的 GPU 计算也会造成一定程度的随机性。
Sherman Chann 表示:「如果不确定性是稀疏 MoE 批推理固有的特征,那么这一事实对于任何使用该类模型的研究来说都应该是显而易见的。Google Deepmind 的研究团队显然知道这一点,并且他们认为这个问题很微不足道,以至于只是把它写成了一句不经意的话放在论文中」。
此外,Sherman Chann 还推测 GPT-3.5-Turbo 可能也使用了 MoE。
网友怎么看
这篇博客发表后,开发者们也开始讨论 GPT-4输出的不确定问题。有人认为这可能是「多线程并行」造成的:
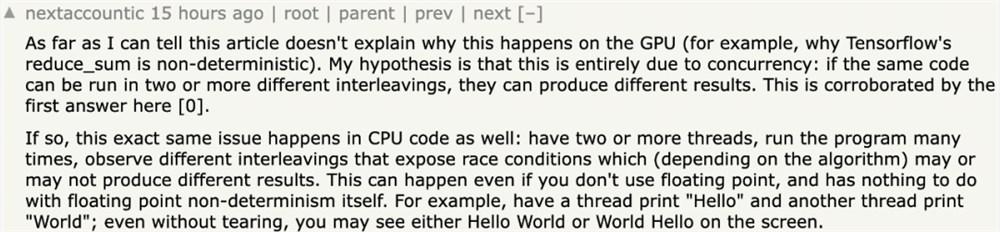
也有人表示:「虽然计算是确定的,但是执行计算的多个处理器之间可能存在时钟频率偏差」:

一位支持 Sherman Chann 的假设的开发者说道:「GPT-3.5-Turbo 可能就是 OpenAI 为 GPT-4构建的小型测试模型」。

还有开发者分析道:「按照 Soft MoE 论文的说法,稀疏 MoE 不仅引入了不确定性,还可能会使模型的响应质量取决于有多少并发请求正在争夺专家模块的分配」。

对此,你怎么看?
参考链接:
https://news.ycombinator.com/item?id=37006224
- 0001
- 0000
- 0000
- 0000
- 0000




