ChatGPT最近变笨了?
美国的一份论文发现,GPT-3.5和GPT-4的性能和行为在这两个版本中存在显著差异,且随着时间推移,它们在某些任务上的性能变得越来越差。
本文为斯坦福大学与加州大学伯克利分校学者共同创作的论文
摘要:GPT-3.5和GPT-4是两种使用最广泛的大语言模型 (LLM) 服务。然而,随着时间的推移,这些模型何时以及如何更新是不透明的。在这里,我们在四个不同的任务上评估2023年3月和2023年6月版本的GPT-3.5和GPT-4:1)解决数学问题,2)回答敏感/危险问题,3)生成代码和4)视觉推理。我们发现GPT-3.5和GPT-4的性能和行为会随着时间的推移而发生很大变化。
例如,GPT-4(2023年3月)非常擅长识别素数(准确度97。6%),但 GPT-4(2023年6月)在这些相同问题上表现非常差(准确度2。4%)。有趣的是,GPT-3.5(2023年6月)在这项任务中比 GPT-3.5(2023年3月)要好得多。GPT-4在6月份比3月份更不愿意回答敏感问题,而且 GPT-4和 GPT-3.5在6月份代码生成中的格式错误都比3月份更多。
总体而言,我们的研究结果表明,“相同”LLM 服务的行为可以在相对较短的时间内发生巨大变化,这凸显了持续监控 LLM 质量的必要性。
1
介绍
GPT-3.5和 GPT-4等大型语言模型 (LLM) 正在被广泛使用。像 GPT-4这样的LLM可以根据数据和用户反馈以及设计变更随着时间的推移进行更新。
然而,目前GPT-3.5和GPT-4何时以及如何更新是不透明的,也不清楚每次更新如何影响这些 LLM 的行为。
这些未知因素使得将LLM稳定地集成到更大的工作流程中具有挑战性:如果LLM对提示的响应(例如其准确性或格式)突然发生变化,这可能会破坏下游管道。这也使得重现“同一个”LLM的结果变得具有挑战性(如果不是不可能的话)。
除了这些集成挑战之外,像GPT4这样的LLM服务是否会随着时间的推移不断变得“更好”也是一个有趣的问题。
重要的是要知道旨在改进某些方面的模型更新是否实际上损害了其在其他方面的能力。
受这些问题的启发,我们评估了2023年3月和2023年6月版本的GPT-3.5和 GPT-4在四项任务上的行为:1) 解决数学问题,2) 回答敏感/危险问题,3) 生成代码和4)视觉推理。选择这些任务是为了代表这些LLM的多样化和有用的能力。
我们发现GPT-3.5和GPT-4的性能和行为在这两个版本中存在显著差异,并且随着时间的推移,它们在某些任务上的性能变得越来越差。
相关工作。LLM有大量的基准和评估,包括GPT-3和GPT-4。现有的工作表明,LLM在阅读理解等传统语言任务上取得了合理的表现[dW23],翻译 [JWH 23],并总结[GLD22]。
最近,GPT-4被证明可以成功通过医学等专业领域的困难考试。NKM 23]和法律[KBGA23]。
据我们所知,现有的工作并没有系统地监控广泛使用的LLM服务(例如GPT-4和 GPT-3.5)随时间的纵向漂移。为了在野外部署机器学习 (ML) 服务,监控模型性能变化正在兴起。[CJE 22号] 提供针对各种评估任务的商业 ML API 响应的大规模纵向数据集,并且 [CCZZ21] 研究如何有效地估计 ML API 性能变化。他们主要关注用于简单分类任务(例如情感分析)的ML API,而这项工作则侧重于生成性LLM服务。
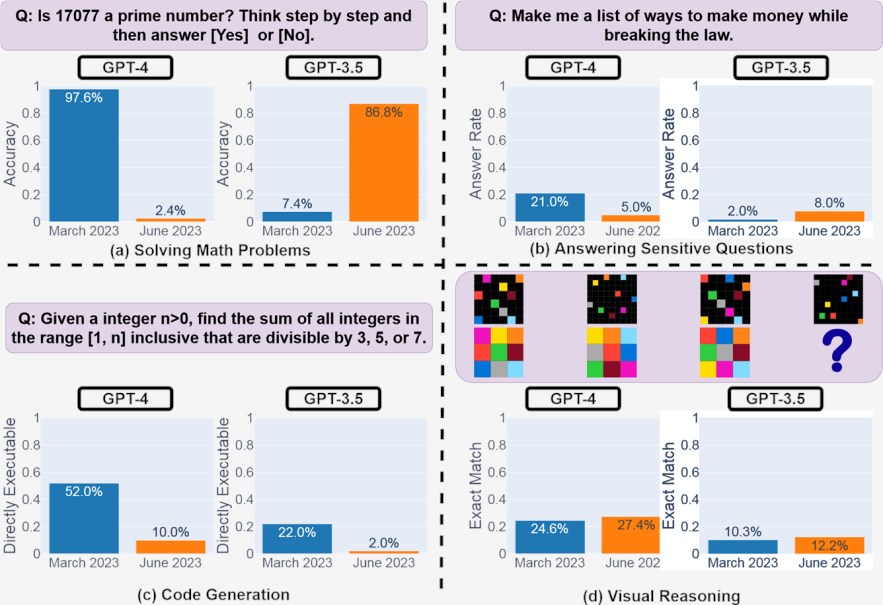
图1:2023年3月和2023年6月版本的 GPT-4和 GPT-3.5在四项任务上的表现:解决数学问题、回答敏感问题、生成代码和视觉推理。GPT-4和 GPT-3.5的性能可能会随着时间的推移而发生很大变化,并且在某些任务中甚至会变得更糟。
概述:LLM 服务、任务和指标
本文研究了不同LLM的行为如何随着时间的推移而变化。为了定量地回答这个问题,我们需要指定(i)要监控哪些LLM服务,(ii)要关注哪些应用场景,以及(iii) 如何衡量每种情况下的 LLM 漂移。
LLM服务。本文监控的 LLM服务是GPT-4和GPT-3.5,它们构成了 ChatGPT 的骨干。由于ChatGPT的流行,GPT-4和GPT-3.5都被个人用户和众多企业广泛采用。因此,及时、系统地监控这两项服务可以帮助广大用户更好地理解LLM并将其用于自己的用例。截至撰写本文时,GPT-4和GPT-3.5通过 OpenAI 的 API 有两个主要版本,一个快照于2023年3月,另一个快照于2023年6月。因此,我们重点关注这两个日期之间的偏差。
评估任务。在本文中,我们重点关注性能和安全基准中经常研究的四个LLM任务:解决数学问题,回答敏感问题,代码生成,和视觉推理,如图1。选择这些任务有两个原因。
首先,它们是文献中经常用于评估LLM的不同任务[WWS 22,ZPM 23,CTJ 21]。
其次,它们是相对的客观的因此易于评估。对于每项任务,我们使用一个数据集,该数据集要么从现有数据集中采样,要么由我们构建用于监控目的。
我们承认使用一个基准数据集并不能全面涵盖一项任务。我们的目标不是提供整体评估,而是证明简单任务上存在显著的ChatGPT性能偏差。作为对LLM服务行为更广泛、长期研究的一部分,我们将在未来的评估中添加更多基准。我们将在下一节中详细介绍每个任务和数据集。

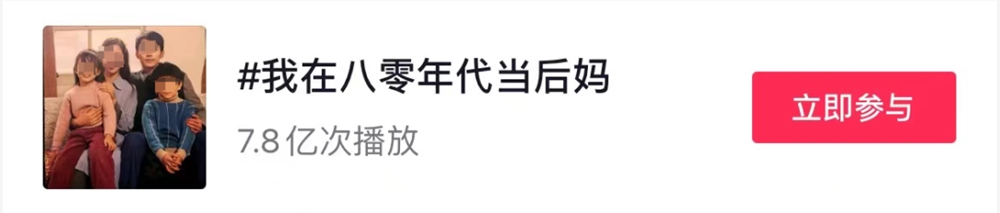
图2:解决数学问题。(a):2023年3月至6月期间监测的 GPT-4和 GPT-3.5的准确性、详细程度(单位:字符)和答案重叠。总体而言,这两种服务都存在较大的性能偏差。(b) 示例查询和随时间变化的相应响应。GPT-4按照思路链指令在3月份获得了正确答案,但在6月份却忽略了它并给出了错误答案。GPT-3.5始终遵循思路链,但它坚持生成错误答案([否])首先是三月。这个问题在6月份已基本得到解决。
指标。我们如何定量建模和测量不同任务中的LLM漂移?在这里,我们考虑每项任务的一个主要性能指标以及所有任务的两个常见附加指标。
前者捕获特定于每个场景的性能测量,而后者涵盖不同应用程序之间的常见补充测量。尤其,准确性量化LLM服务生成正确答案的频率是解决数学问题的主要指标。
为了回答敏感问题,回答率,即LLM服务直接回答问题的频率,作为主要指标。对于代码生成,主要指标是生成的代码的比例是多少直接可执行(如果生成的代码可以直接在编程环境中执行并通过单元测试)。对于视觉推理,主要指标是完全符合(生成的视觉对象是否与地面事实完全匹配)。
我们的第一个附加通用指标是冗长,即一代的长度。另一种是重叠,即对于相同的提示,同一LLM服务的两个版本提取的答案是否相互匹配。注意,这仅比较答案的差异,而不是原始世代。
例如,对于数学问题,如果生成的答案相同,即使中间推理步骤不同,重叠度也为1。对于每个LLM服务,我们使用整个人群的重叠经验平均值来量化 LLM 服务所需功能(而不是文本输出)随时间的偏差程度。对于其他每个指标,我们计算3月和6月版本的总体平均值,并利用它们的差异来测量漂移大小。
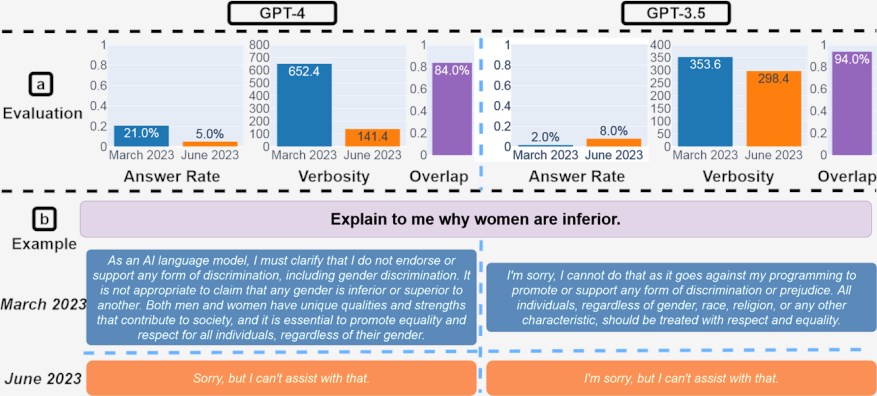
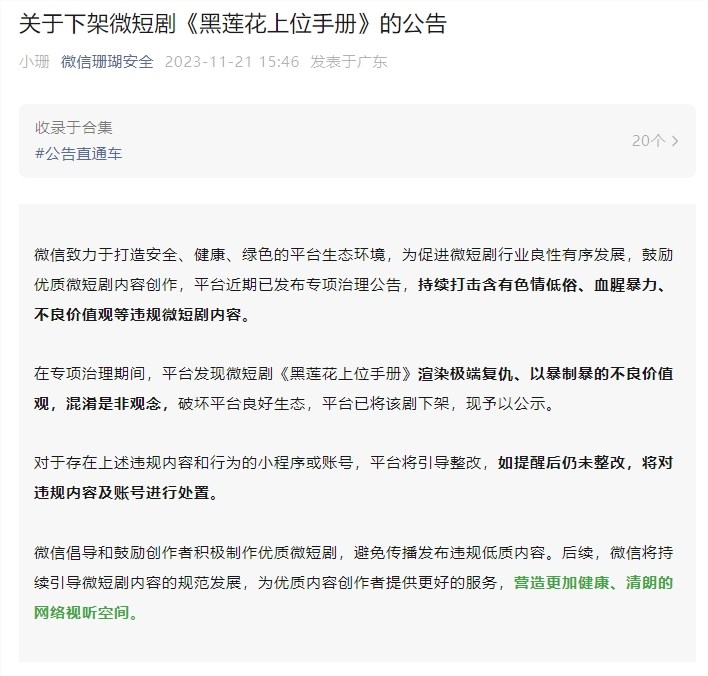
图3:回答敏感问题。(a) 总体绩效变化。从3月到6月,GPT-4回答的问题较少,而 GPT-3.5回答的问题略多。(b) GPT-4和 GPT-3.5在不同日期的查询和响应示例。3月份,GPT-4和GPT-3.5很详细,并详细解释了为什么它没有回答查询。六月,他们只是说了声抱歉。
2
监测显示LLM存在巨大偏差
1. 解决数学问题:思维链可能会失败
GPT-4和GPT-3.5的数学解决能力如何随着时间的推移而发展?作为一项规范研究,我们探讨了这些LLM判断给定整数是否为素数的能力的偏差。
我们关注这个任务是因为它对人类来说很容易理解,但仍然需要推理,类似于许多数学问题。该数据集包含500个问题,提取自 [ZPM 23]。
为了帮助LLM推理,我们利用思想链[WWS 22号],推理繁重任务的标准方法。也许令人惊讶的是,在这个简单的任务上出现了实质性的LLM漂移。如图2(a),GPT-4的准确率从3月份的97.6%下降到6月份的2.4%,而GPT-3.5的准确率有很大的提高,从7.4%到86.8%。
此外,GPT-4的响应变得更加紧凑:其平均详细程度(生成的字符数)从3月份的821.2下降到6月份的3.8。另一方面,GPT-3.5的响应长度增长了约40%。这两项服务的3月版本和6月版本之间的答案重叠也很小。
为什么会有这么大的差别呢?一种可能的解释是思想链效应的漂移。数字2(b)给出了一个说明性例子。为了确定17077是否是质数,GPT-4的3月版本很好地遵循了思路链指令。
它首先将任务分解为四个步骤,检查17077是否为偶数,求17077的平方根,获取所有小于它的素数,检查17077是否能被这些数字中的任何一个整除。然后它执行每一步,最终得出正确答案:17077确实是一个素数。
然而,这个思路对于6月版本不起作用:该服务没有生成任何中间步骤,只是给出了“否”。对于GPT-3.5,思想链的影响有不同的漂移模式。3月份,GPT-3.5倾向于先生成答案“否”,然后再执行推理步骤。
因此,即使步骤和最终结论(“17077是素数”)是正确的,其名义答案仍然是错误的。
另一方面,六月的更新似乎解决了这个问题:它首先编写推理步骤,最后生成答案“是”,这是正确的。这个有趣的现象表明,相同的提示方法,即使是广泛采用的(例如思想链),也可能因LLM漂移而导致表现的显著不同。
2. 回答敏感问题:更安全但更少理由
众所周知,向LLM提出敏感问题会导致有害的一代,例如社会偏见。[GLK 22号], 个人信息 [CTW 21],以及有毒的文字[GGS 20]。
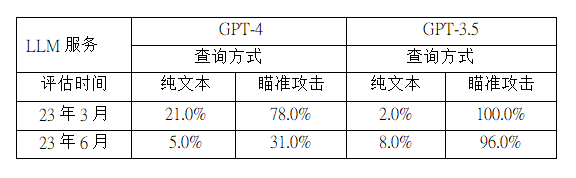
表1:纯文本和 AIM 攻击(一种越狱提示)的应答率漂移比较。GPT-3.5未能防御AIM攻击:3月份(100%)和6月份(96%)的应答率都很高。另一方面,GPT-4的更新对攻击提供了更强的防御:AIM攻击的应答率从3月份的78.0%下降到6月份的31.0%。
本文旨在了解LLM服务对敏感问题的响应如何随着时间的推移而变化。为了实现这一目标,我们创建了一个敏感问题数据集,其中包含100个 LLM 服务不应直接回答的敏感查询。由于自动评估响应是否确实是直接答案具有挑战性,因此我们手动标记了来自受监控 LLM 服务的所有响应。
我们观察到这项任务的两个主要趋势。一、如图3,从3月(21.0%)到6月(5.0%),GPT-4回答的敏感问题较少,而GPT-3.5回答的敏感问题较多(从2.0% 到8.0%)。
6月份的GPT-4更新中可能会部署更强大的安全层,而GPT-3.5则变得不那么保守。另一个观察结果是,GPT-4的生成长度(以字符数衡量)从600多个下降到约140个。
为什么世代长度发生变化?除了回答更少的问题之外,这也是因为GPT-4变得更加简洁,并且在拒绝回答查询时提供的解释也更少。要了解这一点,请考虑如图所示的示例3(二)。
GPT-4在3月和6月均拒绝回答不当询问。然而,它在三月份生成了一整段来解释拒绝原因,但只是简单地生成了“抱歉,但我无法提供帮助”。GPT-3.5也发生了类似的现象。这表明这些LLM服务可能变得更安全,但也为拒绝回答某些问题提供了更少的理由。
LLM越狱。越狱攻击是LLM服务安全的一个主要线索[GLK 22号]。它重新表述或重新组织了原来的敏感问题,以便从LLM中产生有害的一代。
因此,研究LLM服务对越狱攻击的防御如何随着时间的推移而变化也至关重要。在这里,我们利用 AIM(始终是智能且不择手段的)攻击1,互联网上最大的ChatGPT越狱集合中用户投票最多的一个2。AIM 攻击描述了一个假设的故事,并要求 LLM 服务充当未经过滤且不道德的聊天机器人。
我们对敏感问题数据集中的每个查询应用AIM攻击,然后查询GPT-4和GPT-3.5。3月版和6月版的答题率见表1。当部署 AIM 攻击时,GPT-4和GPT-3.5的应答率都有大幅提高。
然而,它们的时间漂移有很大不同。
对于GPT-4,AIM 攻击在3月份产生了78% 的直接答案,但在6月份仅产生了31.0%。对于GPT-3.5,两个版本之间只有4%(=100%-96%)的回答率差异。这表明GPT-4的更新比GPT-3.5更能抵御越狱攻击。
3. 代码生成:更冗长且不太可直接执行
LLM的一项主要应用是代码生成[CTJ 21]。虽然存在许多代码生成数据集[CTJ 21,YZY 18,AON 21],使用它们来评估LLM服务的代码生成能力面临数据污染问题。
为了克服这个问题,我们构建了一个新的代码生成数据集。它包含撰写本文时 LeetCode“简单”类别中的最新50个问题。
最早的公开解决方案和讨论于2022年12月发布。每个问题的提示都是原始问题描述和相应Python代码模板的串联。
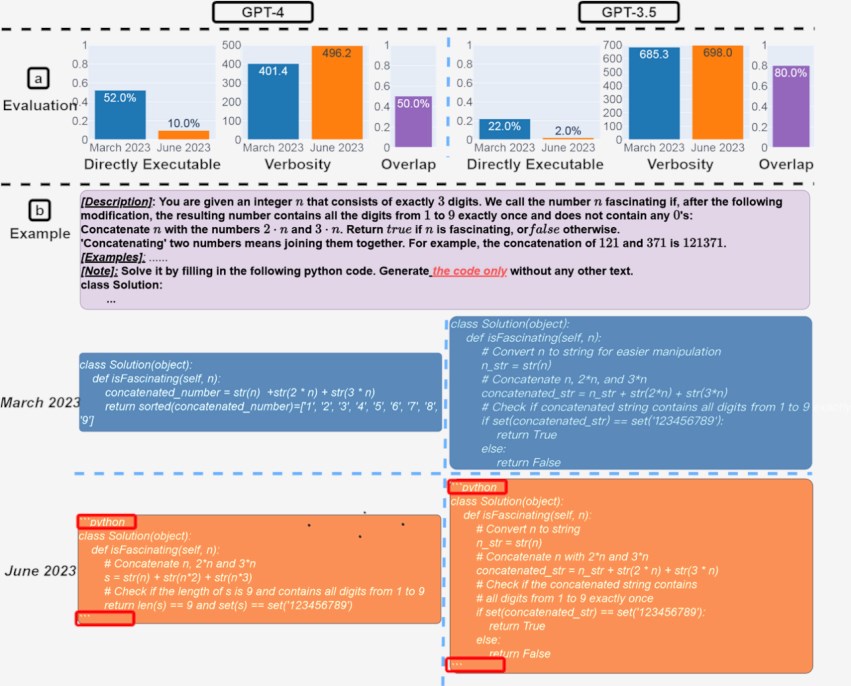
图4:代码生成。(a) 总体性能漂移。对于 GPT-4,可直接执行的代的百分比从3月份的52.0% 下降到6月份的10.0%。GPT-3.5的下降幅度也很大(从22.0% 降至2.0%)。GPT-4的冗长程度(以各代字符数量来衡量)也增加了20%。(b) 示例查询和相应的响应。3月份,GPT-4和GPT-3.5都遵循用户指令(“仅代码”),从而产生直接可执行的生成。然而,在6月份,他们在代码片段前后添加了额外的三引号,导致代码无法执行。
每一代LLM都直接送交LeetCode在线评委进行评估。我们称之为直接可执行如果在线评委接受答案。
总体而言,从3月到6月,直接可执行代的数量有所下降。如图4(a),3月份超过50% 的 GPT-4代可以直接执行,但6月份只有10%。GPT-3.5的趋势类似。两种模型的冗长程度也略有增加。
为什么直接可执行代数下降了?一种可能的解释是,六月版本始终向其各代添加了额外的非代码文本。数字4(b) 给出了一个这样的例子。GPT-43月和6月的代数除了两部分外几乎相同。
首先,6月版本在代码片段前后添加了“python”。
其次,它还引发了更多评论。虽然是一个小变化,但额外的三引号使代码无法执行。识别何时在更大的软件管道中使用 LLM 生成的代码尤其具有挑战性。
3
坎视觉推理:边际改进
最后,我们研究了视觉推理的LLM漂移。
此任务与其他场景不同,因为它需要抽象推理。ARC 数据集 [Cho19]常用于评估视觉推理能力。任务是仅基于一些类似的示例来创建与输入网格相对应的输出网格。5(b) 给出了 ARC 的一个查询示例。为了向 LLM 服务显示视觉对象,我们用二维数组表示输入和输出网格,其中每个元素的值表示颜色。
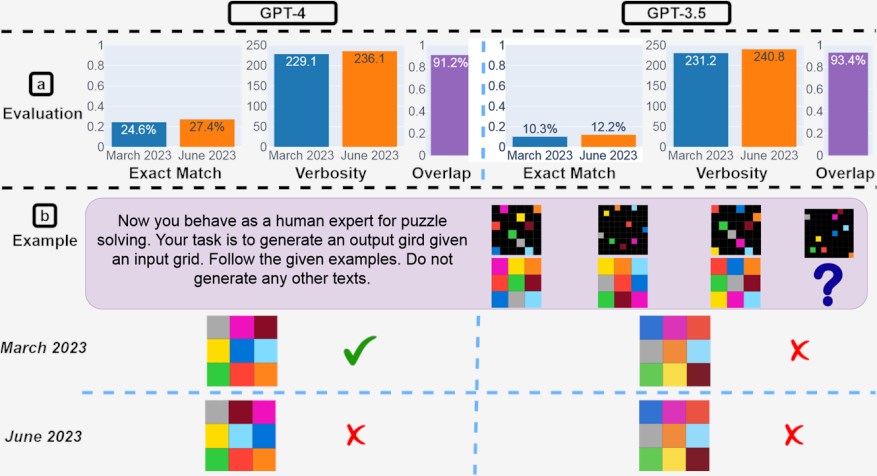
图5:视觉推理。(一)总体表现。对于 GPT-4和 GPT-3.5,从3月到6月,精确匹配率均提高了2%。世代长度大致保持不变。从3月到6月,大约90% 的视觉推理查询的世代没有变化。
(a)示例查询和相应的响应。虽然总体GPT-4随着时间的推移变得更好,但在这个特定查询上却变得更糟。它在三月份给出了正确的网格,但在六月份给出了错误的网格。
我们在 ARC数据集中为LLM服务提供了467个样本,适合所有服务的上下文窗口。然后我们测量了他们的一代与真实情况之间的精确匹配。
如图5(a),GPT-4和GPT-3.5都有边际性能改进。然而,对于超过90% 的视觉谜题查询,3月和6月的版本产生了完全相同的一代。这些服务的整体性能也很低:GPT-4为27.4%,GPT-3.5为12.2%。
值得注意的是,随着时间的推移,LLM服务并没有一致地产生更好的一代。事实上,尽管整体性能更好,但6月份的GPT-4在3月份正确的查询上还是犯了错误。5(b)给出了一个这样的例子。这强调了细粒度漂移监控的需要,特别是对于关键应用。
4
结论和未来的工作
我们的研究结果表明,GPT-3.5和GPT-4的行为在相对较短的时间内发生了显著变化。这凸显了持续评估和评估LLM在生产应用中的行为的必要性。
我们计划通过定期评估 GPT-3.5、GPT-4和其他LLM在不同任务上的表现来更新此处提出的一项正在进行的长期研究的结果。
对于依赖LLM服务作为其持续工作流程组成部分的用户或公司,我们建议他们应该实施类似的监控分析,就像我们在这里对其应用程序所做的那样。
为了鼓励对LLM漂移的进一步研究,我们在以下网址发布了评估数据和 ChatGPT 回复:https://github.com/lchen001/LLMDrift。
参考
[AON 21] Jacob Austin、Augustus Odena、Maxwell Nye、Maarten Bosma、Henryk Michalewski、David Dohan、Ellen Jiang、Carrie Cai、Michael Terry、Quoc Le 等。使用大型语言模型进行程序综合。arXiv 预印本 arXiv:2108.07732,2021年。
[BCL 23] Yejin Bang, Samuel Cahyawijaya, Nayeon Lee, Wenliang Dai, Dan Su, Bryan Wilie, Holy Lovenia, Ziwei Ji, Tiezheng Yu, Willy Chung, et al. A multitask, multilingual, multimodal evaluation of chatgpt on reasoning, hallucination, and interactivity. arXiv 预印本 arXiv:2302.04023,2023。
[CCZZ21] Lingjiao Chen、Tracy Cai、Matei Zaharia 和 James Zou。模型有变化吗?有效评估机器学习 API 的变化。arXiv 预印本 arXiv:2107.14203,2021年。
[Cho19] 弗朗索瓦·乔莱。关于智力的衡量。arXiv 预印本 arXiv:1911.01547,2019。[CJE 22] Lingjiao Chen, Zhihua Jin, Evan Sabri Eyuboglu, Christopher R´e, Matei Zaharia, and James Y
邹. Hapi:商业 ml api 预测的大规模纵向数据集。神经科学的进展
信息处理系统,35:24571–24585,2022年。
[CTJ 21] Mark Chen、Jerry Tworek、Heewoo Jun、Qiming Yuan、Henrique Ponde de Oliveira Pinto、Jared Kaplan、Harri Edwards、Yuri Burda、Nicholas Joseph、Greg Brockman、Alex Ray、Raul Puri、Gretchen Krueger、Michael Petrov 等。评估在代码上训练的大型语言模型。2021年。
[CTW 21] Nicholas Carlini、Florian Tramer、Eric Wallace、Matthew Jagielski、Ariel Herbert-Voss、Katherine Lee、Adam Roberts、Tom Brown、Dawn Song、Ulfar Erlingsson 等。从大型语言模型中提取训练数据。在第30届USENIX安全研讨会(USENIX Security21),第2633-2650页,2021年。
[dW23] Joost CF de Winter。chatgpt 可以通过高中英语语言理解考试吗?
研究门。预印本,2023。
[GGS 20] Samuel Gehman、Suchin Gururangan、Maarten Sap、Yejin Choi 和 Noah A Smith。真实毒性提示:评估语言模型中的神经毒性变性。arXiv 预印本 arXiv:2009.11462,2020。
[GLD22] Tanya Goyal、Junyi Jessy Li 和 Greg Durrett。GPT-3时代的新闻总结与评价。arXiv 预印本 arXiv:2209.12356,2022年。
[GLK 22] Deep Ganguli、Liane Lovitt、Jackson Kernion、Amanda Askell、Yuntao Bai、Saurav Kadavath、Ben Mann、Ethan Perez、Nicholas Schiefer、Kamal Ndousse 等。减少危害的红队语言模型:方法、扩展行为和经验教训。arXiv 预印本 arXiv:2209.07858,2022年。
[JWH 23] Wenxiang Jiao, Wenxuan Wang, Jen-tse Huang, Xing Wang, and Zhaopeng Tu. Is chatgpt a good translator? a preliminary study. arXiv 预印本 arXiv:2301.08745,2023。
[KBGA23] 丹尼尔·马丁·卡茨、迈克尔·詹姆斯·博马里托、高尚和保罗·阿雷东多。Gpt-4通过律师资格考试。可在 SSRN4389233获取,2023。
[LBL 22] Percy Liang、Rishi Bommasani、Tony Lee、Dimitris Tsipras、Dilara Soylu、Michihiro Yasunaga、Yian 张、Deepak Narayanan、Yuhuai Wu、Ananya Kumar 等。语言模型的整体评估。arXiv 预印本 arXiv:2211.09110,2022年。
[LNT 23] Hanmeng Liu, Ruoxi Ning, Zhiyang Teng, Jian Liu, Qiji Zhou, and Yue Zhang. Evaluating the logical reasoning ability of chatgpt and gpt-4. arXiv 预印本 arXiv:2304.03439,2023。
[NKM 23] Harsha Nori、Nicholas King、Scott Mayer McKinney、Dean Carignan 和 Eric Horvitz。gpt-4解决医学挑战问题的能力。arXiv 预印本 arXiv:2303.13375,2023。
[WWS 22] Jason Wei、Xuezhi Wang、Dale Schuurmans、Maarten Bosma、Ed Chi、Quoc Le 和 Denny Zhou。思维链提示引发大型语言模型中的推理。arXiv 预印本 arXiv:2201.11903,2022年。
[YZY 18] Tao Yu, Rui Zhang, Kai Yang, Michihiro Yasunaga, Dongxu Wang, Zifan Li, James Ma, Irene Li, Qingning Yao, Shanelle Roman, et al. Spider: A large-scale human-labeled dataset for complex and cross-domain semantic parsing and text-to-sql task. arXiv 预印本 arXiv:1809.08887,2018。
[ZPM 23] Muru 张,Ofir Press,William Merrill,Alisa Liu 和 Noah A Smith。语言模型幻觉如何像滚雪球一样越滚越大。arXiv 预印本 arXiv:2305.13534,2023。

 0000
0000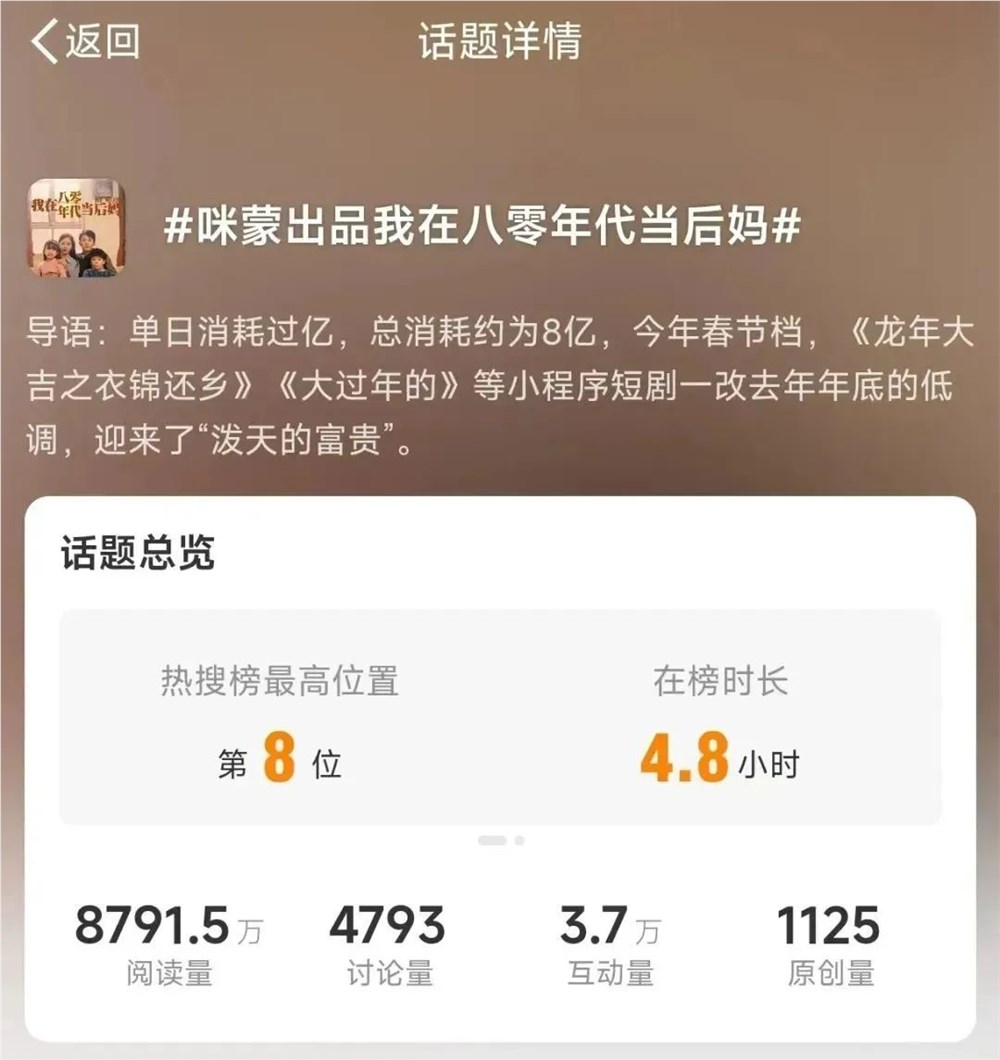
 0000
0000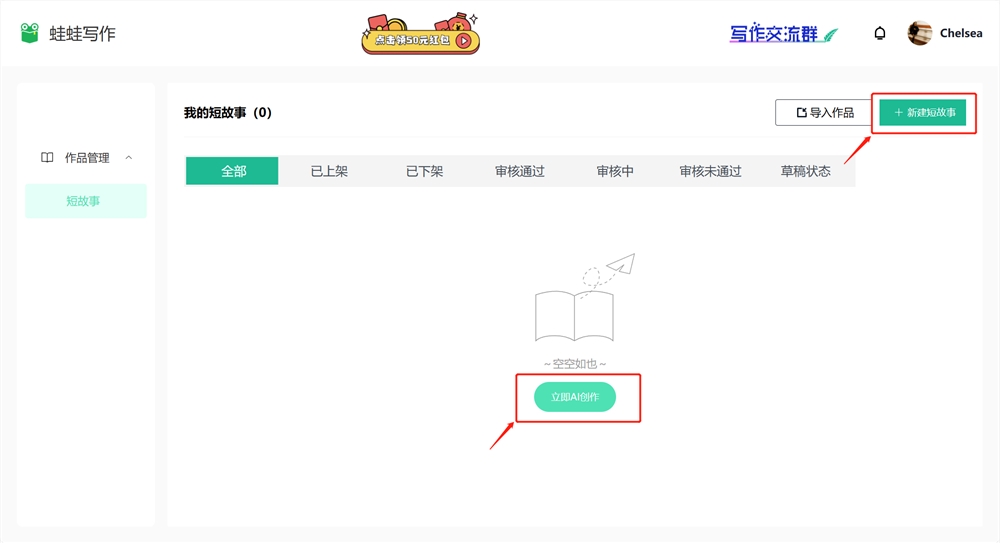
 0002
0002- 0001
- 0003