又一开源替代品!Guanaco性能达ChatGPT级别 在单个GPU上训练一天就能搞定
有一种名为 QLoRA 的新方法可以在单个 GPU 上微调大型语言模型。目前已经有研究人员用它来训练 Guanaco,这是一个性能效果99% 接近ChatGPT的聊天机器人。
华盛顿大学的研究人员提出了微调大型语言模型的方法 QLoRA。该团队利用 QLoRA 发布了 Guanaco,这是一个基于Meta 的 LLaMA模型的聊天机器人系列。最大的 Guanaco 变体具有650亿个参数,在与GPT-4的基准测试中实现了ChatGPT ( GPT-3.5-turbo )99% 以上的性能。
微调大型语言模型是提高其性能和训练的最重要技术之一。然而,这个过程对于大型模型来说计算量非常大,例如 LLaMA65B ,在这种情况下需要超过780GB 的 GPU RAM。虽然开源社区使用各种量化方法将16位模型简化为4位模型,从而大大减少了推理所需的内存,但类似的方法还没有用于微调。
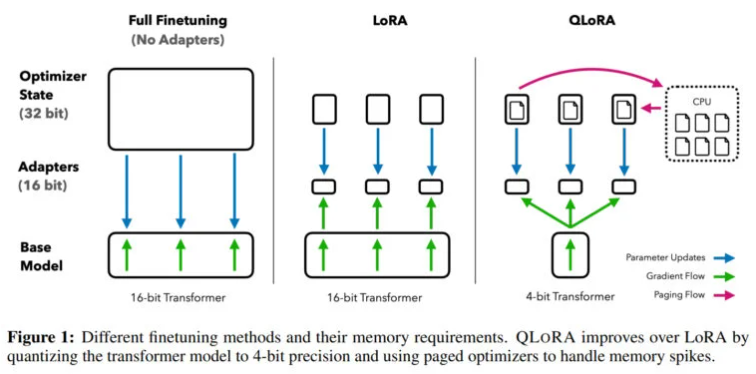
QLoRA 允许在单个 GPU 上微调650亿个参数 LLM
通过 QLoRA,该团队展示了一种方法,允许将 LLaMA 等模型量化为4位,并添加LORA模型,然后通过反向传播进行训练。通过这种方式,该方法可以实现4位模型的微调,并将650亿参数模型的内存需求从超过780GB 降低到不到48GB 的 GPU 内存,其结果与微调16位模型相同。
“这标志着LLM微调的可访问性发生了重大转变:现在是迄今为止在单个GPU上微调的最大公开可用模型,”该团队说。
为了测试 QLoRA 和不同微调数据集的影响,该团队在八个不同的数据集上训练了1,000多个模型。一个关键发现:数据的质量比任务的数量更重要。例如,在OpenAssistant 的9,000个人类样本上训练的模型比在 FLANv2的100万个样本上训练的模型更适合聊天机器人。因此,对于 Guanaco,该团队依赖于 OpenAssistant 数据。
开源模型 Guanaco 达到 ChatGPT 级别
该团队使用 QLoRA 训练了 Guanaco 系列模型,表现第二好的模型在基准测试中以330亿个参数实现了 ChatGPT 性能的97.8%,同时在不到12小时的时间内在单个普通的 GPU 上对其进行了训练。在专业 GPU 上,该团队仅用24小时就训练了具有650亿个参数的最大模型,并达到了ChatGPT 性能的99.3% 。
最小的 Guanaco 模型具有70亿个参数,仅需要5GB 的 GPU 内存,并且在 Vicuna 基准测试中比26GB 的羊驼模型高出20个百分点以上。
除了 QLoRA 和 Guanaco,该团队还发布了 OpenAssistant 基准测试,该基准测试在953个提示示例中让模型相互竞争。然后可以由人类或 GPT-4对结果进行评分。
Guanaco数学不好,QLoRA可用于移动微调
不过,该团队引用数学能力和4位推理目前非常慢。接下来,该团队希望提高推理能力,预计速度提升8至16倍。
由于微调是将大型语言模型转变为类似 ChatGPT 的聊天机器人的重要工具,该团队相信 QLoRA 方法将使微调更容易获得——尤其是对于资源较少的研究人员而言。他们认为,这对于自然语言处理领域尖端技术的可访问性来说是一个巨大的胜利。
论文指出:“QLORA 可以被视为一个平衡因素,有助于缩小大型企业与拥有消费类 GPU 的小型团队之间的资源差距。这也意味着,小企业可以通过像 Colab 这样的云服务进行微调大模型。
除了微调当今最大的语言模型外,该团队还看到了私有模型在移动硬件上的应用。“QLoRA 还将在您的手机上启用隐私保护微调。我们估计您每晚可以使用 iPhone12Plus 微调300万个单词。这意味着,很快我们将在手机上拥有专门针对每个应用程序的LLM。”第一作者 Tim Dettmers 在 Twitter 上说。
关于Guanaco-33B 更多信息和代码可到 GitHub 查看。
参考网址:
https://github.com/artidoro/qlora
相关产品可访问《有哪些类似chatgpt产品? 17 个ChatGPT/GPT4 开源替代品推荐(附网址)》一文了解。

 0002
0002- 0000
- 0000
- 0000
- 0000