Media2Face:支持语音等多模态引导生成3D面部动态表情
划重点:
1. 🧠 引入广义神经参数化面部资产(GNPFA),通过高度概括的表达潜在空间解耦表情和身份。
2. 🌈 创造 M2F-D 数据集,包含大量共语3D面部动画,具备情感和风格标签。
3. 🚀 提出 Media2Face,基于GNPFA潜在空间的扩散模型,接受来自音频、文本和图像的多模态引导,拓展了3D面部动画的表现力和风格适应性。
从语音合成3D 面部动态画面已经引起了相当多的关注。由于缺乏高质量的4D 面部数据和注释丰富的多模态标签,以前的方法常常受到现实性有限和缺乏灵活调节的困扰。在这项名为 "Media2Face" 的研究中,来自上海科技大学、Deemos Technology、香港大学等研究人员们致力于解决从语音生成3D面部动画的挑战。

据介绍,Media2Face可以根据声音来生成与语音同步的、表现力丰富的3D面部动画。同时允许用户对生成的面部动画进行更细致的个性化调整,如愤怒、快乐等。Media2Face还能理解多种类型的输入信息(音频、文本、图像),并将这些信息作为生成面部动画的指引。
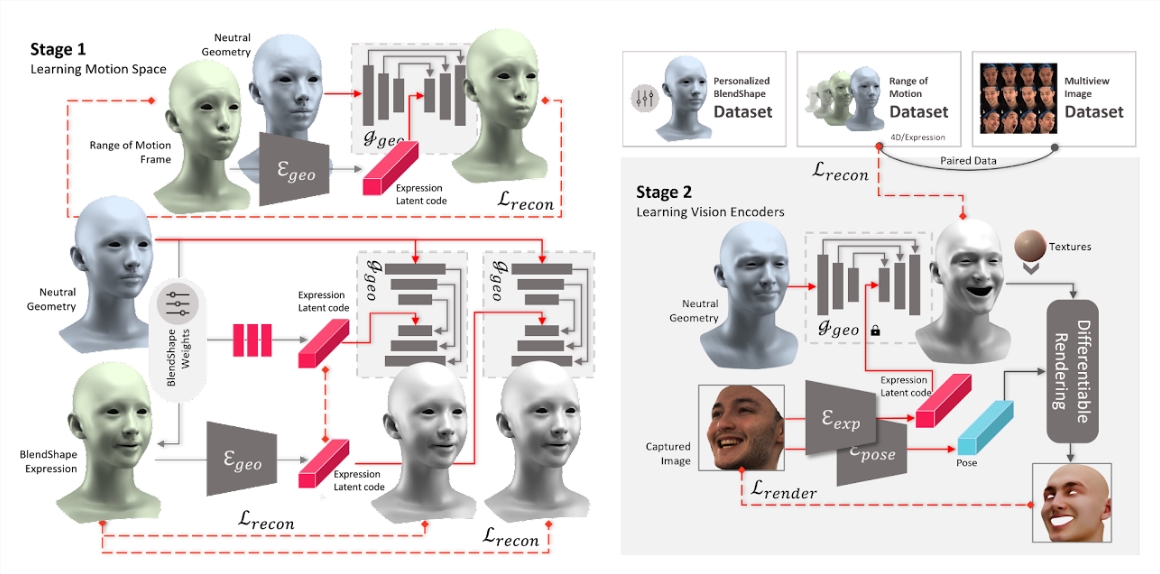
研究团队通过三个关键步骤来应对这一挑战:
首先,引入了广义神经参数化面部资产(GNPFA),这是一个高效的变分自编码器,将面部几何和图像映射到高度概括的表达潜在空间,实现表情和身份的解耦。
然后,利用GNPFA从大量视频中提取高质量的表情和准确的头部姿势,形成了M2F-D数据集,这是一个大型、多样化且扫描级别的共语3D面部动画数据集,具有充分注释的情感和风格标签。
最后,提出了Media2Face,这是一个基于GNPFA潜在空间的扩散模型,用于共语面部动画生成,接受来自音频、文本和图像的丰富多模态引导。

在模型的训练过程中,研究团队通过训练几何变分自编码器(geometry VAE)学习了表情和头部姿势的潜在空间,实现了对表情与身份的解耦。两个视觉编码器被训练以从RGB图像中提取表情潜在编码和头部姿势。模型以音频特征和CLIP潜在编码作为条件,去噪表情潜在编码序列和头部运动编码。
条件被随机掩码并与嘈杂的头部运动编码进行交叉关注。在推断阶段,通过DDIM采样头部运动编码,将表情潜在编码馈送到GNPFA解码器,提取表情几何,结合模型模板生成受头部姿势参数增强的面部动画。
在实验中,研究团队展示了他们的模型不仅在面部动画合成方面达到了高保真度,而且在3D面部动画的表现力和风格适应性方面取得了显著的拓展。他们通过脚本文本描述生成生动的对话场景,通过图像提示合成风格化的面部动画,甚至在法语、英语和日语中进行情感歌唱。通过表情编码器提取关键帧表情潜在编码,通过CLIP提供每帧风格提示,通过扩散插值技术调整控制强度和范围,进一步生成个性化且细致入微的面部网格,适应不同性别、年龄和族裔的各种身份特征。
Media2Face在共语面部动画领域取得了令人瞩目的成果,为面部动画合成的逼真度和表现力开辟了新的可能性。
产品项目入口:https://sites.google.com/view/media2face
论文地址:arxiv.org/abs/2401.15687
- 0000
- 0000
- 0000
- 0000
- 0000