AI概览唤起率仅7%,谷歌的AI搜索出师不利
过去二十年间,试图在搜索引擎领域掀翻谷歌王座的挑战者不知凡几,可谷歌可谓是从来都稳坐钓鱼台。直到2023年AI搜索引擎Perplexity横空出世,“谷歌杀手”这一次具象化了,而贝佐斯、孙正义等一众大咖的青睐更是让谷歌感受到了压力。为了应对挑战,今年5月举行的I/O开发者大会上,谷歌方面公布了AI Overviews(AI概览),使得AI搜索不再由Perplexity独享。
基于AI概览功能,用户在搜索问题时,谷歌AI会自动抓取网页内容生成总结,用户也不再需要点击网页去寻找所需的信息。然而遗憾的是,号称“重新定义搜索体验”的AI概览,上线之后的表现却只能用“丢人现眼”来形容。例如当用户查询如何将芝士和披萨饼胚粘在一起的时候,AI概览的回答是“加点胶水”。
胶水确实是有效的粘合剂,但使用它的代价是披萨也就不能吃了。显而易见,AI概览给出的回答并不靠谱。紧接着就在外界以为这又是困扰AI大模型的幻觉问题作祟时,神通广大的网友很快给出了AI概览会回答“在披萨上涂胶水”的理由,因为这个回答实际上来源于一位Reddit用户在11年前发的帖子。
由于Reddit以6000万美元的价格与谷歌签署了一项内容授权协议,所以后者使用Reddit的数据很正常。但不正常的是,谷歌的AI概览居然会在常识问题上翻车。为此,谷歌方面不得不紧急对其进行“十多项技术改进和更新”,以避免一些奇怪的、不准确的或无益的搜索结果出现。
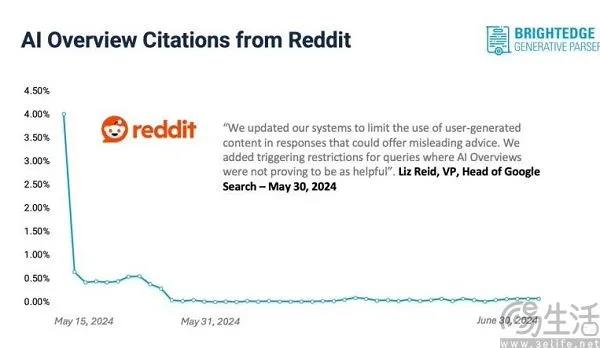
就在网友们以为AI概览的翻车只不过是新技术的阵痛,经过谷歌的改进后,AI概率已经“药到病除”之后,现实却超乎了几乎所有人的想象,谷歌方面其实并没有从技术上解决AI概览生成错误的结果,而是通过降低AI概览出现的频率、以避免再次翻车。
日前据数字营销和SEO网站Search Engine Land的相关报道显示,现在AI概览仅在7%的搜索结果中展示,而在5月下旬该功能刚刚发布时,这个数字还高达80%。具体来说,教育类问题中AI概览的出现率从26%下降到了13%,电商类问题中的出现率从26%下降到9%,而娱乐类问题里的AI概览则根本不再显示。
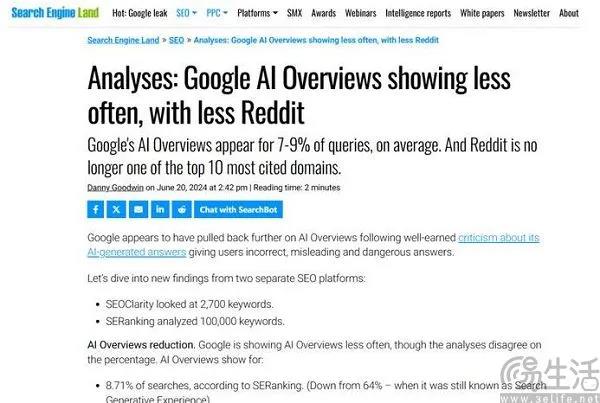
同时Search Engine Land方面还发现,当用户使用的搜索关键词包含“最佳”、“是什么”、“如何”、“症状”等确定性描述时,更容易唤起AI概览。再结合6月下旬,他们发现谷歌方面对搜索算法进行了一项调整,旨在降低Reddit内容在AI搜索结果中的权重。如此一来,对于AI概览翻车,谷歌的做法似乎是“头痛医头,脚痛医脚”。
那么问题来了,为什么对于AI概览这一展示自己AI搜索技术实力的功能,谷歌会选择“摆烂”,或者说Perplexity怎么就没出这样的大问题呢?最直接的解释,可能就是谷歌在数据清洗上出现了纰漏,他们的数据标注人员或者AI未能成功地从Reddit的内容数据里分辨出类似“在披萨上涂胶水”这样的无价值内容。
其实谷歌方面在数据清洗上翻车的可能性并不低,因为过去一年多的时间里,OpenAI已经从谷歌手中夺走了AI赛道领头羊的地位。
为了追赶OpenAI的GPT-4,谷歌的Gemini Pro去年就已经曝出了在训练数据上直接使用百度文心一言输出结果的丑闻。当然了,概率更大的真相或许是不仅仅高质量的中文语料缺乏,高质量的英文语料同样也出现了供给不足。
Common Crawl数据集、The Pile语料库已经哺育了GPT-4、Gemini等,一众海外知名或不知名的大模型。对于数据的渴求,甚至让OpenAI搞出了要求《纽约时报》证明作品原创性的荒诞戏码。为什么谷歌的AI概览会直接使用Reddit的数据,不正是因为开源数据库被薅秃了、闭源数据库却又待价而沽。
要知道谷歌搜索作为全球用户量最多的搜索引擎,平均每秒需要处理超过63000次查询,也就是说每天会有56亿的搜索行为发生。可反观Perplexity,由于使用人群相对有限,即使有翻车的现象也不过是孤立不证,而放在谷歌身上则是海量的个例。同样一件事,大公司与初创企业的地位差异,显然就决定了前者不得不选择保守。
- 0000
- 0000
 0001
0001
 0000
0000
 0000
0000

