15小时、几千元训完中文版LLaMA2!低成本方案全面开源,包含代码权重,支持商用
训练大模型,几千块就能实现了!
现在,15小时、几千块钱、85亿 token数据,即可训出中文LLaMA2。
综合性能达到开源社区同规模从头预训练SOTA模型水平。
方案完全开源,包括全套训练流程、代码及权重。
而且无商业限制,还可迁移应用到任意垂类领域和从头预训练大模型的低成本构建。
要知道,从头预训练大模型此前被戏称“要5000万美元才能入局”,让许多开发者和中小企业都望而却步。
这一回Colossal-LLaMA-2,把大模型门槛打下来了。

同时开源团队还提供了一个完整的评估体系框架ColossalEval,以实现低成本的可复现性。
性能表现
Colossal-LLaMA-2在多个榜单上进行了评测,具体表现如下。
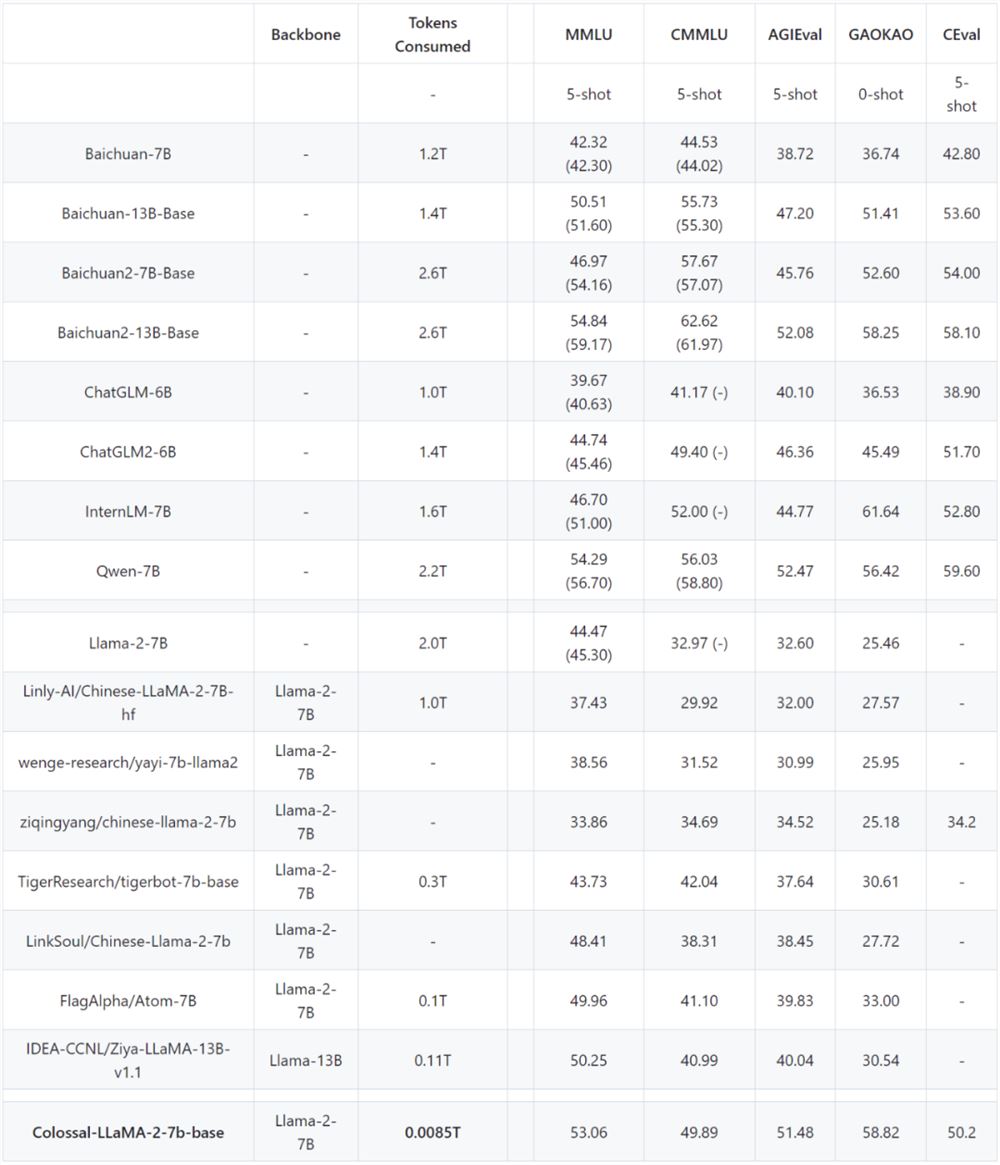
基于ColossalEval评分,括号中分数来源于对应模型官方发布的榜单分数,C-Eval 分数来源于官网 Leaderboard。
常见中英文测评榜
在英文MMLU榜单中,Colossal-LLaMA-2-7B-base 在低成本增量预训练的加持下,克服了灾难性遗忘的问题,能力逐步提升(44.47->53.06),在所有7B 规模的模型中,表现优异。
中文榜单方面主要对比了CMMLU、 AGIEVAL、GAOKAO 和 C-Eval,效果远好于LLaMA-2的其他中文汉化模型。
甚至表现超过了一些使用中文语料从头训练大模型(成本花费或上千万)。
尤其是和原始LLaMA-2相比,在中文能力上有了质的飞跃(CMMLU:32.97->49.89)。
而通过SFT、LoRA等方式微调,能有效注入基座模型的知识与能力十分有限,不能很好满足高质量领域知识或垂类模型应用的构建的需求。
实际效果
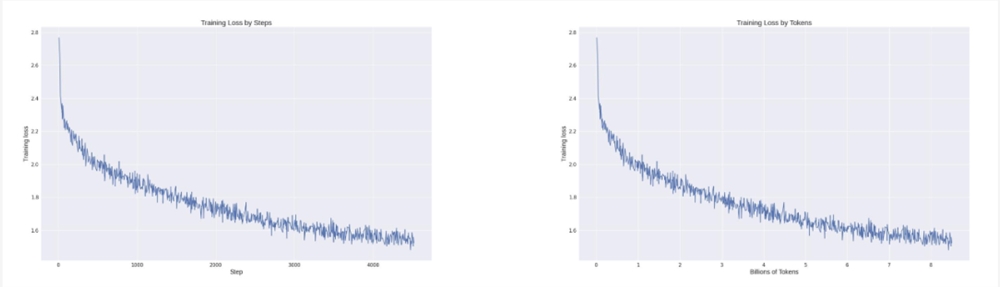
为了更好地评估模型的性能,Colossal-AI 团队不仅仅依赖于量化的指标,还对于模型的不同方面进行了人工的评估,以下是一些例子。
可以看到模型在知识问答、情感分析、翻译、逻辑推理、信息提取及纠错等常见任务中,都表现不错。

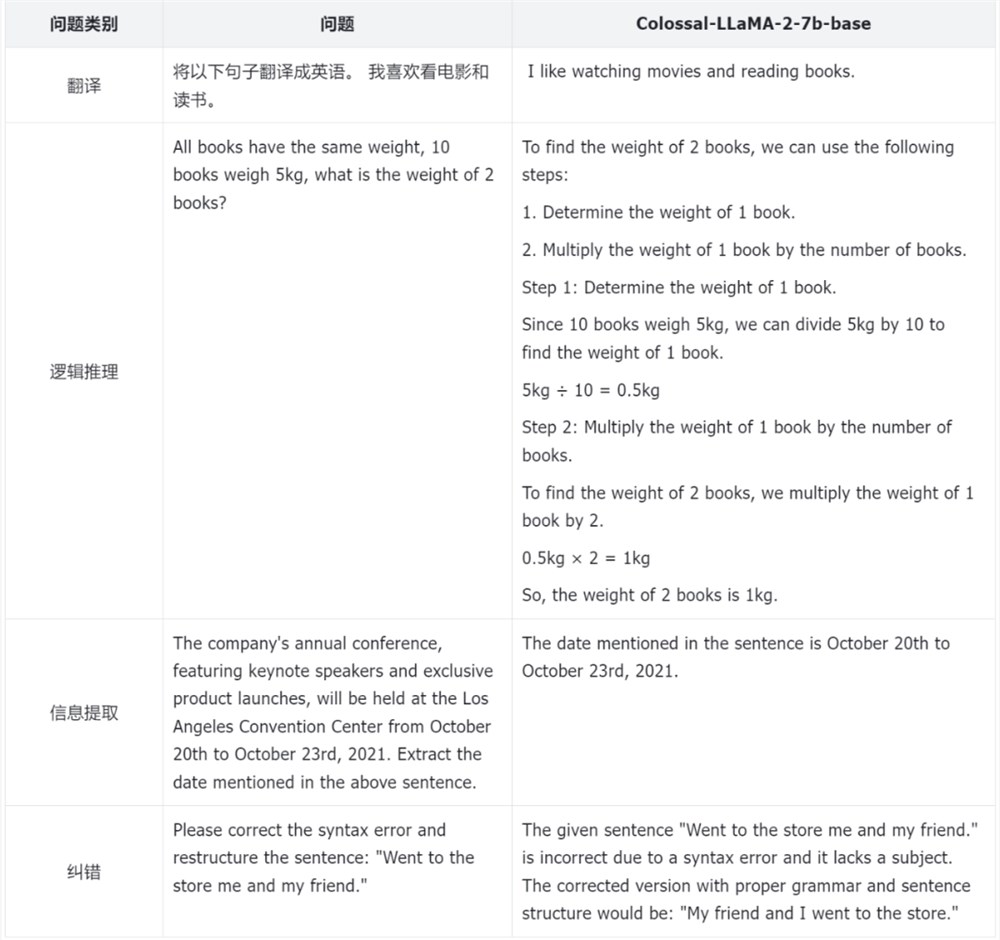
从整个训练的 Loss 记录来看,在利用 Colossal-AI 系统降本增效能力的同时,模型收敛性也得到充分保证,仅通过约8.5B tokens(85亿 tokens),数千元算力成本,让模型达到如上效果。
要知道,现在市面上常见大模型动辄使用几万亿token进行训练,背后的成本非常高。
那么 Colossal-AI 团队是如何做到的?
词表扩充与模型初始化
LLaMA-2原始词表并未针对中文做特定优化,所包含的中文词有限,导致在中文语料上理解力不足。
因此,首先对LLaMA-2进行了词表的扩充。
Colossal-AI 团队发现:
词表的扩充不仅可以有效提升字符串序列编码的效率,并且使得编码序列包含更多的有效信息,进而在篇章级别编码和理解上,有更大的帮助。
然而,由于增量预训练数据量较少,扩充较多的单词反而会导致某些单词或组合无实际意义,在增量预训练数据集上难以充分学习,影响最终效果。
以及过大的词表会导致 embedding 相关参数增加,从而影响训练效率。
所以,在反复实验下,同时考虑训练质量与效率,他们最终确定将词表从 LLaMA-2原有的32000扩充至69104。
有了扩充好的词表,下一步就是基于原有的 LLaMA-2初始化新词表的 embedding。
为了更好地迁移 LLaMA-2原有的能力,实现从原有 LLaMA-2到 中文 LLaMA-2能力的快速迁移,Colossal-AI 团队利用原有的 LLaMA-2的权重,对新的 embedding 进行均值初始化。
既保证了新初始化的模型在初始状态下,英文能力不受影响,又可以尽可能的无缝迁移英文能力到中文上。
数据构建
为了更大程度地降低训练的成本,高质量的数据在其中起着关键作用,尤其是对于增量预训练,对于数据的质量,分布都有着极高的要求。
为了更好的筛选高质量的数据,Colossal-AI 团队构建了完整的数据清洗体系与工具包,以便筛选更为高质量的数据用于增量预训练。
以下图片展示了 Colossal-AI 团队数据治理的完整流程:
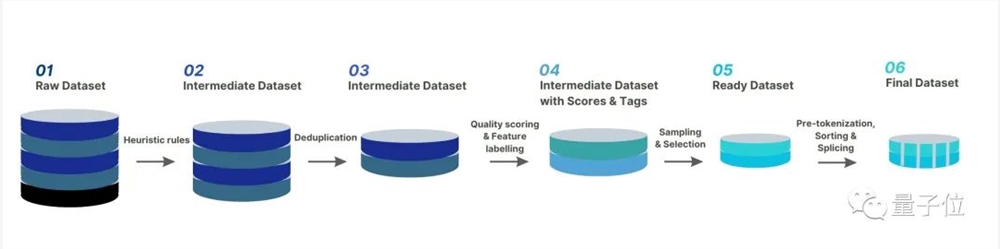
除了常见的对数据进行启发式的筛选和去重,还对重点数据进行了打分和分类筛选。
合适的数据对于激发 LLaMA-2的中文能力,同时克服英文的灾难性遗忘问题,有着至关重要的作用。
最后,为了提高训练的效率,对于相同主题的数据,Colossal-AI 团队对数据的长度进行了排序,并根据4096的最大长度进行拼接。
训练策略
多阶段训练
在训练方面,针对增量预训练的特点,Colossal-AI 团队设计了多阶段,层次化的增量预训练方案,将训练的流程划分为三个阶段:
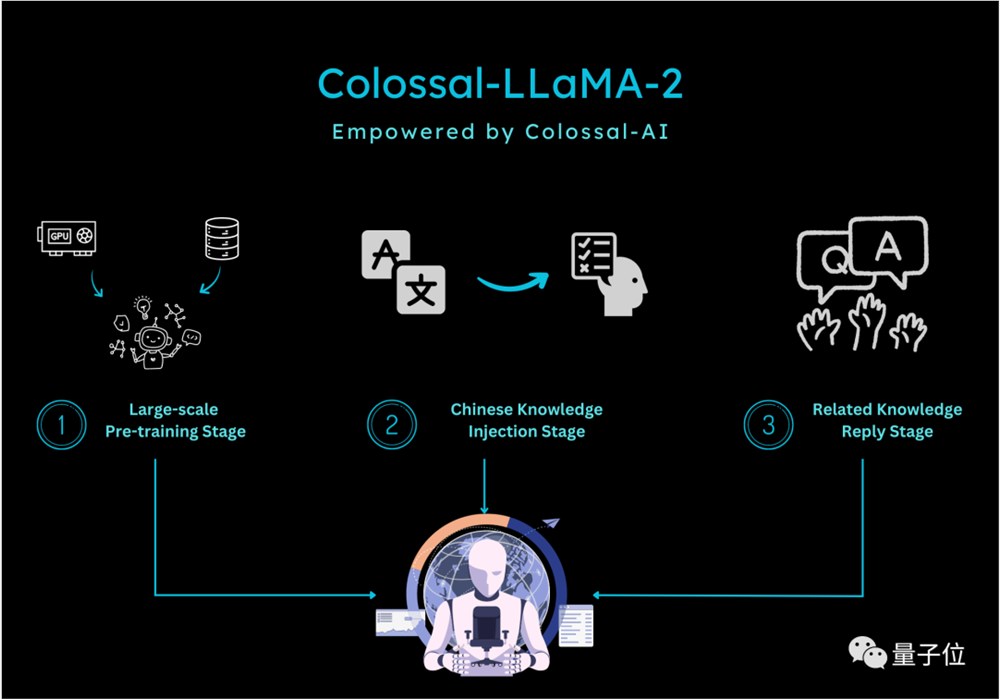
大规模预训练阶段:目标是通过大量语料训练,使得模型可以产出相对较为流畅的文本。该阶段由 LLaMA-2完成,经过此阶段,模型已经掌握大量英文知识,并可以根据 Next Token Prediction 输出流畅的结果。
中文知识注入阶段:该阶段依赖于高质量的中文知识,一方面增强了模型对于中文知识的掌握程度,另一方面提升了模型对于新增中文词表中单词的理解。
相关知识回放阶段:该阶段致力于增强模型对于知识的理解与泛化能力,缓解灾难性遗忘问题。
多阶段相辅相成,最终保证模型在中英文的能力上齐头并进。
分桶训练
增量预训练对于数据的分布极为敏感,均衡性就尤为重要。
因此,为了保证数据的均衡分布,Colossal-AI 团队设计了数据分桶的策略,将同一类型的数据划分为10个不同的 bins。
在训练的过程中,每个数据桶中均匀地包含每种类型数据的一个 bin,从而确保了每种数据可以均匀地被模型所利用。
评估体系
为了更好地评估模型的性能,Colossal-AI 团队搭建了完整的评估体系 - ColossalEval,希望通过多维度对大语言模型进行评估。
流程框架代码完全开源,不仅支持结果复现,也支持用户根据自己不同的应用场景自定义数据集与评估方式。
评估框架特点总结如下:
涵盖针对于大语言模型知识储备能力评估的常见数据集如 MMLU,CMMLU 等。针对于单选题这样的形式,除了常见的比较 ABCD 概率高低的计算方式,增加更为全面的计算方式,如绝对匹配,单选困惑度等,以求更加全面地衡量模型对于知识的掌握程度。
支持针对多选题的评估和长文本评估。
支持针对于不同应用场景的评估方式,如多轮对话,角色扮演,信息抽取,内容生成等。用户可根据自己的需求,有选择性地评估模型不同方面的能力,并支持自定义 prompt 与评估方式的扩展。
从通用大模型到垂类大模型
综上所述,基于 LLaMA-2构建中文能力增强模型,可基本分为以下流程:
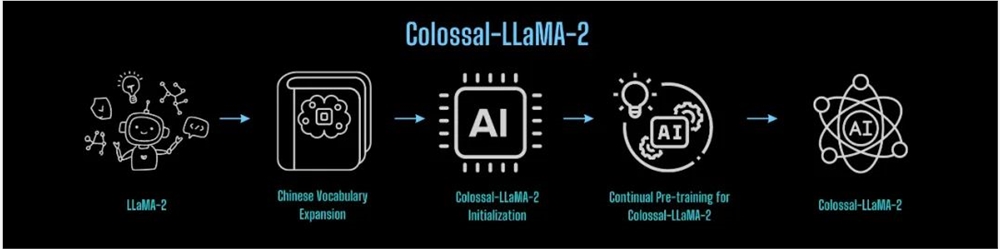
虽然市面的通用大模型百花齐放,但通用大模型不可避免地针对特定领域知识不足。
所以在实际落地中,会出现大模型幻觉严重的情况。
微调可以在一定程度上改善这一问题,但性能提升有限。快速低成本构建一个垂类大模型,再进行细分业务微调,在业务落地上能更有先机和优势。
将以上流程应用在任意领域进行知识迁移,即可构建任意领域垂类基座大模型的轻量化流程:
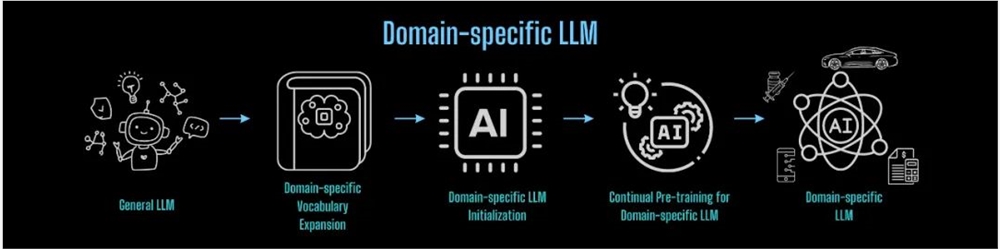
而对于从头预训练构建基础大模型,也可借鉴上述经验与Colossal-AI降本增效能力,降低成本、高效完成。
实际上,如上Colossal-LLaMA-2的所有亮点都构建在低成本AI大模型开发系统Colossal-AI之上。
Colossal-AI基于PyTorch,可通过高效多维并行、异构内存等,降低AI大模型训练/微调/推理的开发与应用成本,提升模型任务表现,降低GPU需求等。
仅一年多时间便已在GitHub开源社区收获GitHub Star3万多颗,在大模型开发工具与社区细分赛道排名世界第一,已与世界500强在内的多家知名厂商联合开发/优化千亿/百亿参数预训练大模型或打造垂类模型。
为更进一步提高AI大模型开发和部署效率,Colossal-AI已进一步升级为Colossal-AI云平台,以低代码/无代码的方式供用户在云端低成本进行大模型训练、微调和部署,快速将各种模型接入到个性化的应用中。

目前ColossalAI云平台上已经预置了Stable diffusion、LLaMA-2等主流模型及解决方案,用户只需上传自己的数据即可进行微调,同时也可以把自己微调之后的模型部署成为API,以实惠的价格使用A10、A800、H800等GPU资源,无需自己维护算力集群以及各类基础设施。更多应用场景、不同领域、不同版本的模型、企业私有化平台部署等正不断迭代。
- 0000
- 0000
- 0001
- 0002
- 0000