ControlNet作者推新项目Omost 一句话变构图小作文 再也不用为写提示词头疼了
近日,ControlNet的作者推出了一个全新的项目——Omost。这个项目对现有图像模型的提示词理解有着巨大的帮助。通过很短的提示词,就可以生成非常详细并且空间表现很准确的图片。
Omost通过预定义的位置、偏移量和区域三大参数来简化图像元素的描述。这使得用户能够更直观地指定图像中各个元素的位置和大小,从而生成高质量、符合预期的图像。
使用Omost,你只需要输入简单的提示词,LLM就可以生成图像每个区域的简单提示和位置信息。然后针对图像九宫格的简单提示词继续扩展,保证了每一部分都有非常详细的描述。
比如,我输入创建一个梦幻的空中城堡,然后它给我返回了一段非常详细的图像描述:
这张照片展示了一座漂浮在高空的梦幻空中城堡,
“城堡完全由玻璃和闪闪发光的金属制成,反射出耀眼的阳光。”,
“精致的桥梁连接着各种塔,每座塔都装饰着复杂的雕刻和发光的符文。”,
“城堡周围的天空是柔和柔和色调的渐变,从黎明的粉红色过渡到黄昏的蓝色。”,
“下面是郁郁葱葱的森林、波光粼粼的河流和连绵起伏的山丘。”,
“整个场景笼罩在一种神奇的氛围中,柔和空灵的光束照亮了城堡,营造出一种奇妙和迷人的感觉。”
然后点击生成图像,它就会将上面的提示转化为图像返给你:
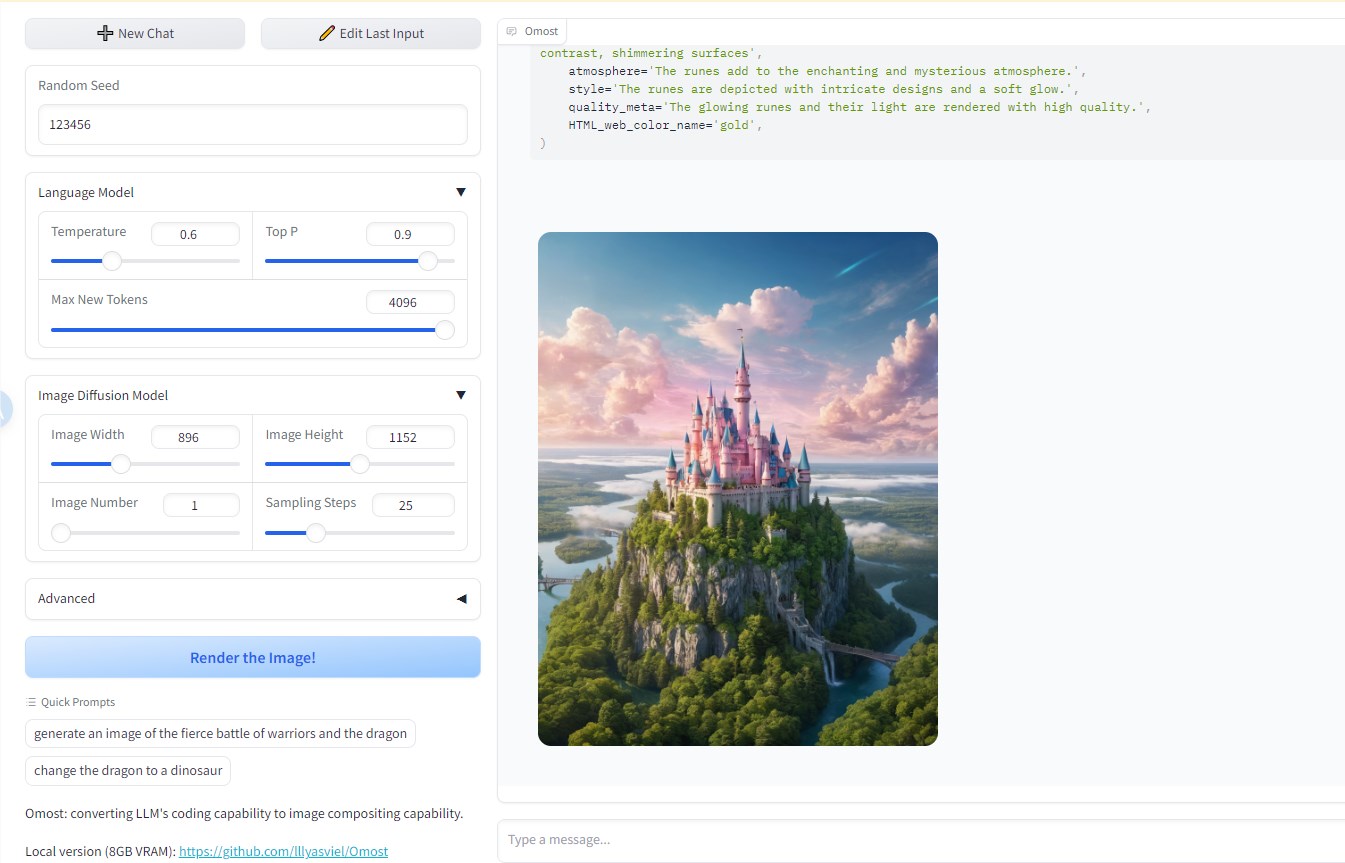
效果还不错。我们也可以将提示词复制到MJ中生成。效果如下:

更牛逼的是,Omost已经完成的图像整体布局可以保留,如果你想修改画面中的某个元素,也只需要一句提示词即可。比如你原来的画面主体是龙,你可以直接把龙变成恐龙。
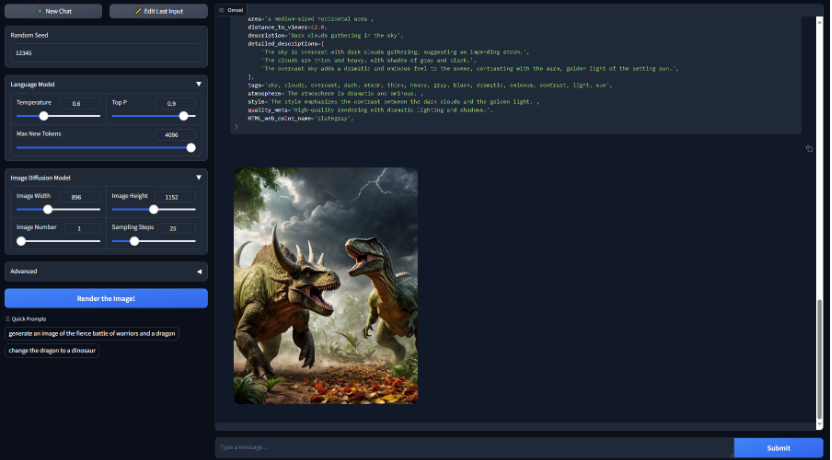
项目亮点:
自动扩展提示词:Omost能够将简单的提示词拆解成详细的描述,从图像整体到局部元素的位置和大小均能详细说明。例如输入“a funny cartoon batman fights joker”,系统会生成蝙蝠侠与小丑战斗的完整图像。
高灵活性:生成的图像布局可以保留,用户可以通过简单的提示词对图像中的某个元素进行修改。比如,将龙变成恐龙,系统会根据新提示生成修改后的图像。
图像位置编码:Omost通过将图像划分为729个不同的位置来简化图像元素的描述。每个位置包括预定义的参数,如位置、偏移量和区域,确保图像生成的准确性和细致度。
子提示系统:所有Omost LLM都经过训练,可以提供严格定义的“子提示”,这些子提示可以独立描述事物,并任意组合形成完整的提示。这种设计提高了提示词的灵活性和准确性。
注意力操纵:Omost使用注意力分数调整技术来控制图像生成过程中的区域关注度,实现更精细的图像生成。通过调整注意力分数,Omost能够生成符合提示词描述的图像元素。
提示前缀树:Omost引入提示前缀树技术,通过合并子提示来改进提示理解和描述。例如,可以将路径“a cat and a dog. the cat on the sofa”作为提示,从而生成相应图像。
Omost的实现和使用
Omost项目基于Llama3和Phi3变体模型,用户可以通过提供简单的提示词来生成复杂的图像。以下是该项目的几个关键组件:
位置和偏移量:将图像划分为9个位置,每个位置进一步划分为81个偏移量,共有729个边界框,用于描述图像元素的位置。
distance_to_viewer和HTML_web_color_name:用于调整图像元素的视觉表现,通过组合这些参数可以生成粗略的图像构图。
注意力操纵:基于注意力分数操作的baseline渲染器,通过调整注意力分数来控制不同区域的模型关注度。
应用和前景
Omost技术的推出,不仅简化了提示词的编写,还提高了图像生成的精确度和灵活性。其应用场景包括但不限于AI绘画、图像设计、广告创意、教育等领域。用户可以通过简单的提示词生成复杂的图像,为创意设计提供了强大的工具支持。
项目页:https://top.aibase.com/tool/omost
试玩地址:https://huggingface.co/spaces/lllyasviel/Omost
- 0000
- 0000
- 0000
- 0001
- 0000


