谷歌发布开源视觉语言模型PaliGemma 支持多视觉语言任务
站长网2024-05-17 11:19:581阅
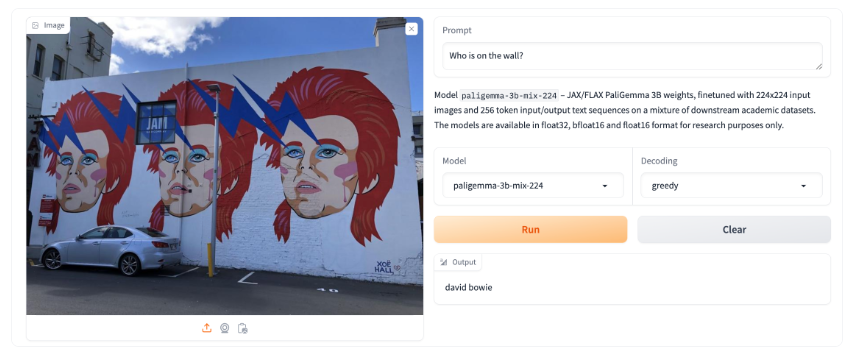
谷歌推出了一款名为PaliGemma的开源视觉语言模型,该模型结合了图像处理和语言理解的能力,旨在支持多种视觉语言任务,如图像和短视频字幕生成、视觉问答、图像文本理解、物体检测、文件图表解读以及图像分割等。
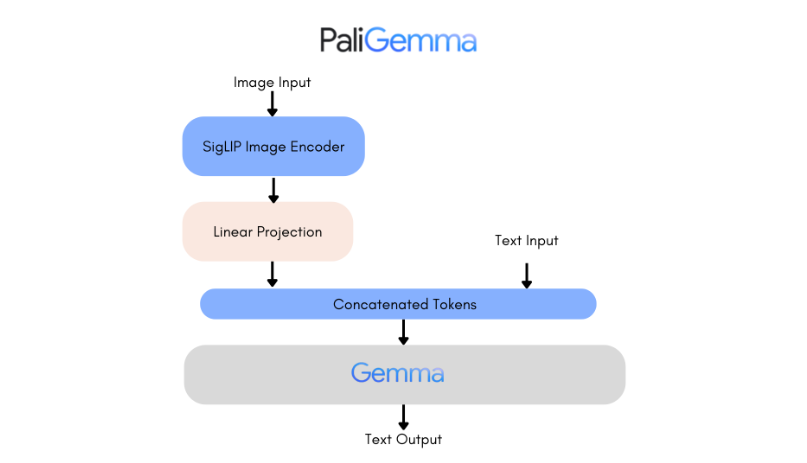
PaliGemma的关键特点:
多任务支持:PaliGemma能够处理多种视觉语言相关的任务,提供广泛的应用场景。
参数规模:该模型包含30亿(3B)个参数,是一个大型的多模态模型。
模型架构:PaliGemma结合了SigLiP视觉编码器和Gemma语言模型,分别负责处理图像和文本输入。
SigLiP视觉编码器:
负责处理图像输入,将视觉信息编码为模型能够理解的格式。
Gemma语言模型:
负责处理文本输入,并生成输出,将图像内容与语言任务结合起来。
PaliGemma的发布是谷歌在AI领域的又一项重要贡献,它不仅推动了视觉语言理解技术的发展,也为研究人员和开发者提供了强大的工具,以探索和创造新的应用。开源的特性意味着PaliGemma可以被社区广泛地使用、改进和集成到各种产品和服务中。
模型地址:https://huggingface.co/blog/paligemma
0001
评论列表
共(0)条相关推荐
- 0000
- 0002
- 0000


 0000
0000

 0002
0002