微软新工具LLMLingua-2:可将 AI 提示压缩高达80%,节省时间和成本
划重点:
🔍 微软研究发布了 LLMLingua-2,一种用于任务不可知压缩提示的模型,可以将原始长度减少高达20%,从而降低成本和延迟。
📊 LLMLingua-2通过智能压缩长提示,去除不必要的词语或标记,同时保留关键信息,使得提示长度可减少至原长度的20%。
🚀 LLMLingua-2在多个数据集上进行了评估,显示出与强基线相比的显著性能改进,并在不同 LLM 之间展现了稳健的泛化能力。
微软研究发布了名为 LLMLingua-2的模型,用于任务不可知的提示压缩。该模型通过智能地去除长提示中的不必要词语或标记,同时保留关键信息,使得提示长度可减少至原长度的20%,从而降低成本和延迟。研究团队写道:“自然语言存在冗余,信息量不尽相同。”
LLMLingua-2比其前身 LLMLingua 和类似方法快3到6倍。LLMLingua-2使用了 MeetingBank 中的示例进行训练,该数据集包含会议记录及其摘要。要对文本进行压缩,首先将原始文本输入训练好的模型。模型对每个词语进行评分,根据周围语境为其分配保留或移除的点数。然后选择具有最高保留值的词语,以创建缩短的提示。
微软研究团队在多个数据集上对 LLMLingua-2进行了评估,包括 MeetingBank、LongBench、ZeroScrolls、GSM8K 和 BBH。尽管模型规模较小,但在各种语言任务(如问答、摘要和逻辑推理)中,它始终优于原始的 LLMLingua 和选择性上下文策略。同样,相同的压缩策略对不同 LLM(从 GPT-3.5到 Mistral-7B)和语言(从英语到中文)都有效。
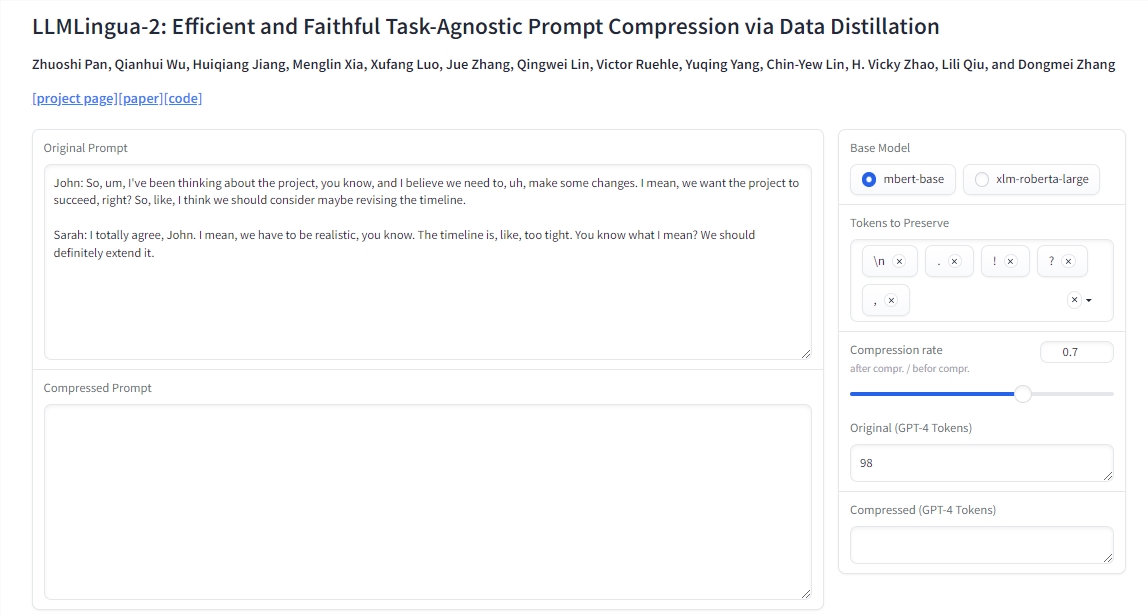
LLMLingua-2只需两行代码就可以实现。该模型还已集成到广泛使用的 RAG 框架 LangChain 和 LlamaIndex 中。微软提供了演示、实际应用示例以及说明提示压缩的好处和成本节省的脚本。该公司认为这是一个有前途的方法,可以通过压缩提示实现更好的泛化能力和效率。
论文地址:https://arxiv.org/abs/2403.12968
项目入口:https://top.aibase.com/tool/llmlingua-2
- 0000
- 0000
- 0000
- 0000
 0000
0000