尤洋团队开源OpenDiT,训练类似Sora模型实现80%加速
**划重点:**
1. 🚀 新加坡国立大学尤洋团队开源项目OpenDiT,加速Diffusion Transformer(DiT)模型训练和部署。
2. 💻 OpenDiT在GPU上实现高达80%的加速,同时节省50%内存,通过采用混合并行和序列并行方法等优化。
3. 🌐 提供易用的pipeline,包括文本到图像和文本到视频生成,验证在ImageNet上训练DiT模型的准确性。
新加坡国立大学尤洋团队最近发布的开源项目OpenDiT,为训练和部署DiT模型提供了新思路。
OpenDiT是一个易于使用、快速且内存高效的系统,专门用于提高DiT应用程序的训练和推理效率,包括文本到视频生成和文本到图像生成。该项目利用了ZeRO并行策略,将DiT模型参数分布到多台机器上,初步降低了显存压力。为了达到更好的性能与精度平衡,OpenDiT还采用了混合精度的训练策略。
在DiT模型的序列并行性方面,尤洋团队提出了FastSeq,一种适用于大序列和小规模并行的新型序列并行方法。这种方法通过最小化序列通信,利用AllGather提高通信效率,并巧妙地使用异步ring来优化性能,尤其适用于处理类似DiT的工作负载。
为了优化DiT模型中的运算效率,OpenDiT引入了高效的Fused adaLN Kernel,将多次操作合并,提高了计算效率并减少了I/O消耗。总体而言,OpenDiT具有在GPU上加速高达80%、50%内存节省的性能优势。
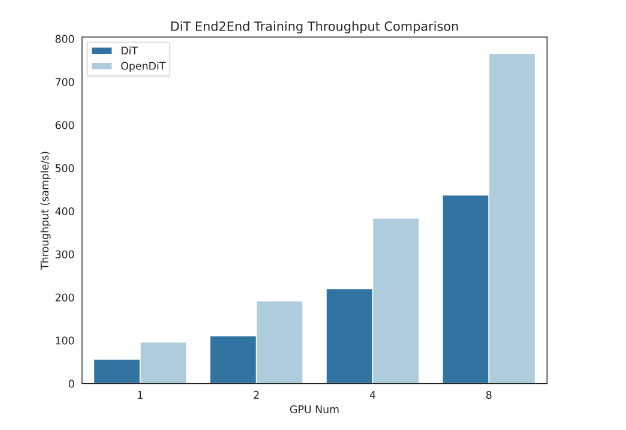
对于用户来说,OpenDiT提供了易于使用的pipeline,包括文本到图像和文本到视频生成。通过在ImageNet上进行文本到图像的训练,研究团队验证了OpenDiT的准确性,并发布了检查点。
OpenDiT为DiT模型的训练和部署提供了一种高效、易用的解决方案,为研究者和工程师在最短时间内复现Sora的效果提供了有力支持。
特色功能亮点:
OpenDiT 采用以下技术提高性能:
- GPU 上高达80% 的加速和50% 的内存减少
- 包括 FlashAttention、Fused AdaLN 和 Fused layernorm 核的内核优化。
- 包括 ZeRO、Gemini 和 DDP 等混合并行方法。此外,对 ema 模型进行分片进一步降低内存成本。
- FastSeq:一种新颖的序列并行方法,特别适用于 DiT 样式的工作负载,其中激活大小较大但参数大小较小。
易于使用:
- 通过几行更改实现巨大的性能提升
- 用户无需了解分布式训练的实现。
-支持 Image 和 Video 训练和推断:
- 使用脚本或命令行进行图像和视频训练
- 支持多节点训练和推断
- 提供用于训练和推断速度提升的库
项目入口:https://top.aibase.com/tool/opendit
- 0000
- 0001
- 0002
- 0000
 0000
0000