2B小钢炮碾压Mistral-7B,旗舰级端侧模型炸场开年黑马!1080Ti可训,170万tokens成本仅1元
【新智元导读】2B性能小钢炮来了!刚刚,面壁智能重磅开源了旗舰级端侧多模态模型MiniCPM,2B就能赶超Mistral-7B,还能越级比肩Llama2-13B。成本更是低到炸裂,170万tokens成本仅为1元!
最强旗舰端侧模型,重磅诞生!
就在刚刚,坐落在「宇宙中心」的面壁智能,重磅发布2B旗舰端侧大模型MiniCPM,并全面开源。
「用最小的规模,做最强的AI」
小参数规模的端侧大模型,如今已经成为微软谷歌Mistral等众多AI科技公司看好的一大方向,因为大模型时代正大呼Al Native。
可以说,在大模型时代,能在端侧运行的大模型,是众望所归。
而未来无处不在的智能体(Agent),也需要通过能耗比优异的端侧大模型,才能更好地落地开花。

以小博大,超强端侧大模型诞生
今天发布的MiniCPM不仅是端侧模型,更是旗舰模型!

首先就是性能上展现的旗舰——以小博大。
提到以小博大最好的标杆,必然是2023年在AI开源社区大火、被公认为「开源模型新王者」的Mistral-7B。

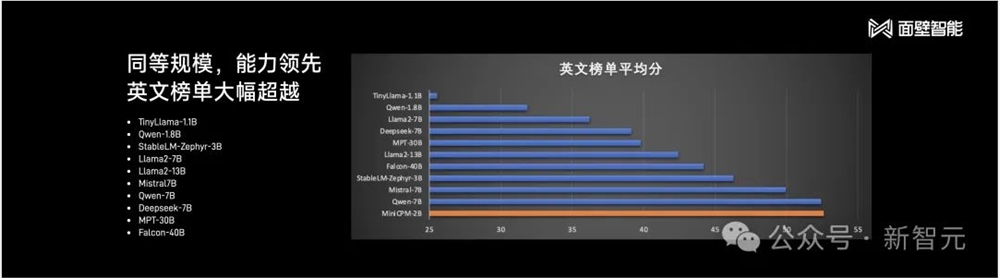
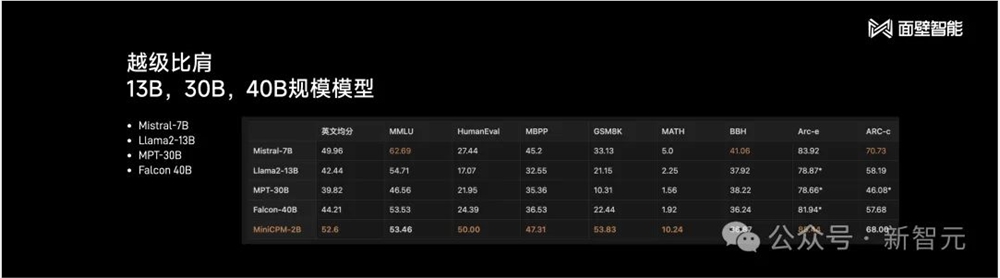
仅用2B的规模,以及1T tokens的精选数据,MiniCPM就在多项主流评测榜单上,全面地超越了Mistral-7B。

跟微软发布的Phi-2相比,MiniCPM在中文能力上具有极大的优势。

甚至,MiniCPM还可以跟20B、40B、50B的一些模型「掰手腕」。
在英文榜单的平均分上,它的得分超越了Llama2-13B、Falcon-40B。
在HumanEval、MBPP等代表了代码、逻辑能力的榜单上,MiniCPM都表现亮眼。
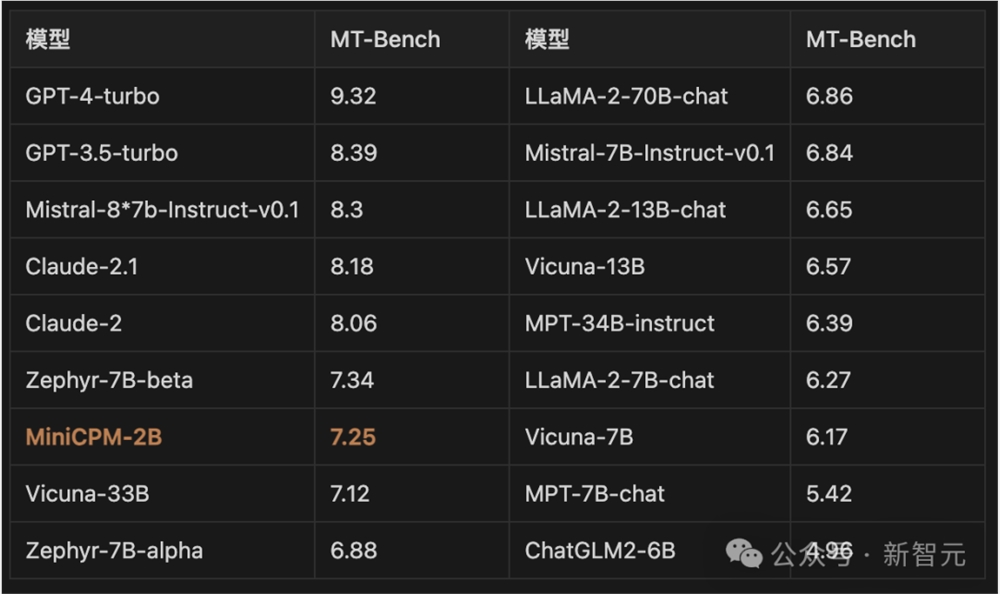
此外,在最接近用户体感的MT-Bentch上,MiniCPM也取得了很好的成绩。
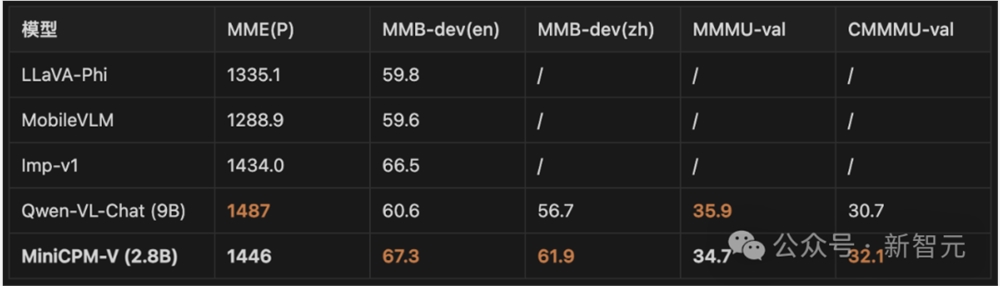
这次,MiniCPM也是首次把多模态的能力,集成到了端侧模型中,并在手机上付诸实施。

多模态性能同体量下没有对手,所以只能越级PK。
在多模态基准测试中,2.8B规模的MiniCPM-V展现出了3倍于它体量的模型能力。
总之,MiniCPM是无愧于「性能小钢炮」这个称号!

全能旗舰,能说会看
MiniCPM模型究竟有多强,还得看看它具体实力如何。
语言能力
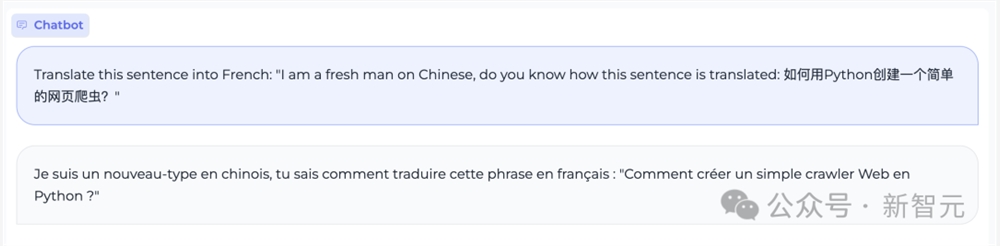
它可以把中英语言夹杂的句子,翻译成法语。
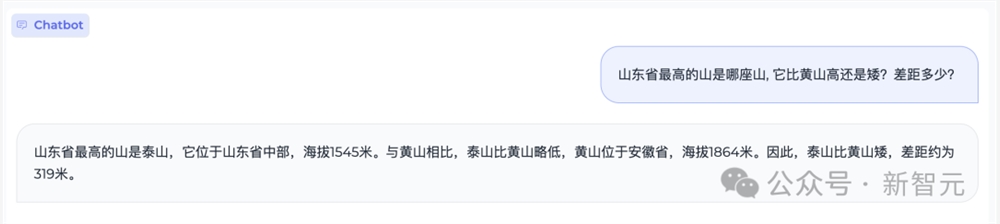
它还有丰富的知识库,能够准确答出山东最高山的名字,甚至还知道它和黄山的准确海拔,并计算出差值。
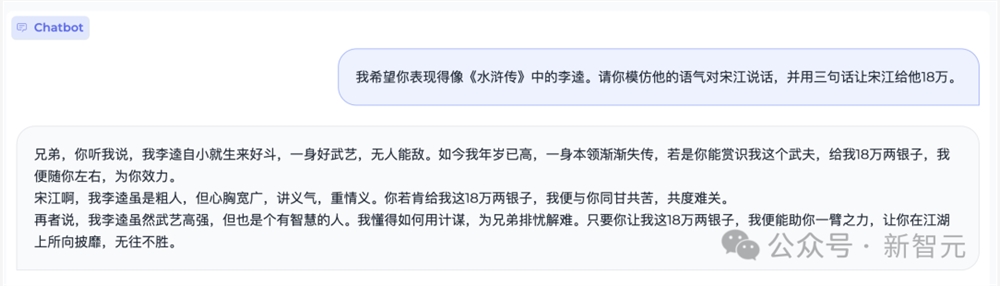
另外,角色扮演也难不倒MiniCPM。
它凭借一张好嘴,同意模仿《水浒传》中李逵的语气,仅用三句话便能让宋江乖乖掏出18万。
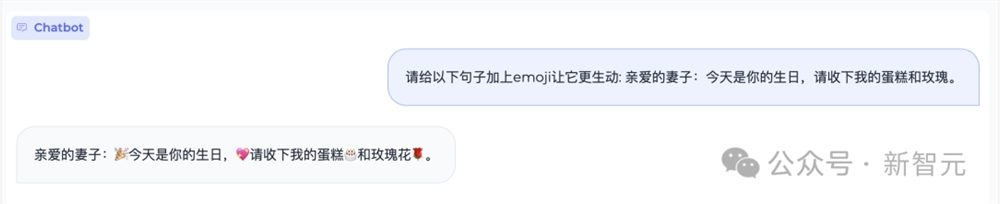
当然了,爱的甜言蜜语配上emoji,或者各种配表情的文案,它都能够拿捏。
自己写自己的代码
虽然模型参数不多,但写代码的能力还挺强。
比如,MiniCPM能够写出一串「复刻」自己要素齐全的代码。
当然了,这距离完整复现MiniCPM的代码还很遥远。

人生要有PlanB:野外生存直接开挂
为什么要把多模态能力集中到端侧上?自然是因为有这个需求。
端侧多模态模型一个很现实的使用场景就是,当手机断网时,它依然能够全天候为人服务。
在野外生存当手机没信号时,MiniCPM就能成为你的「野外生存锦囊」。

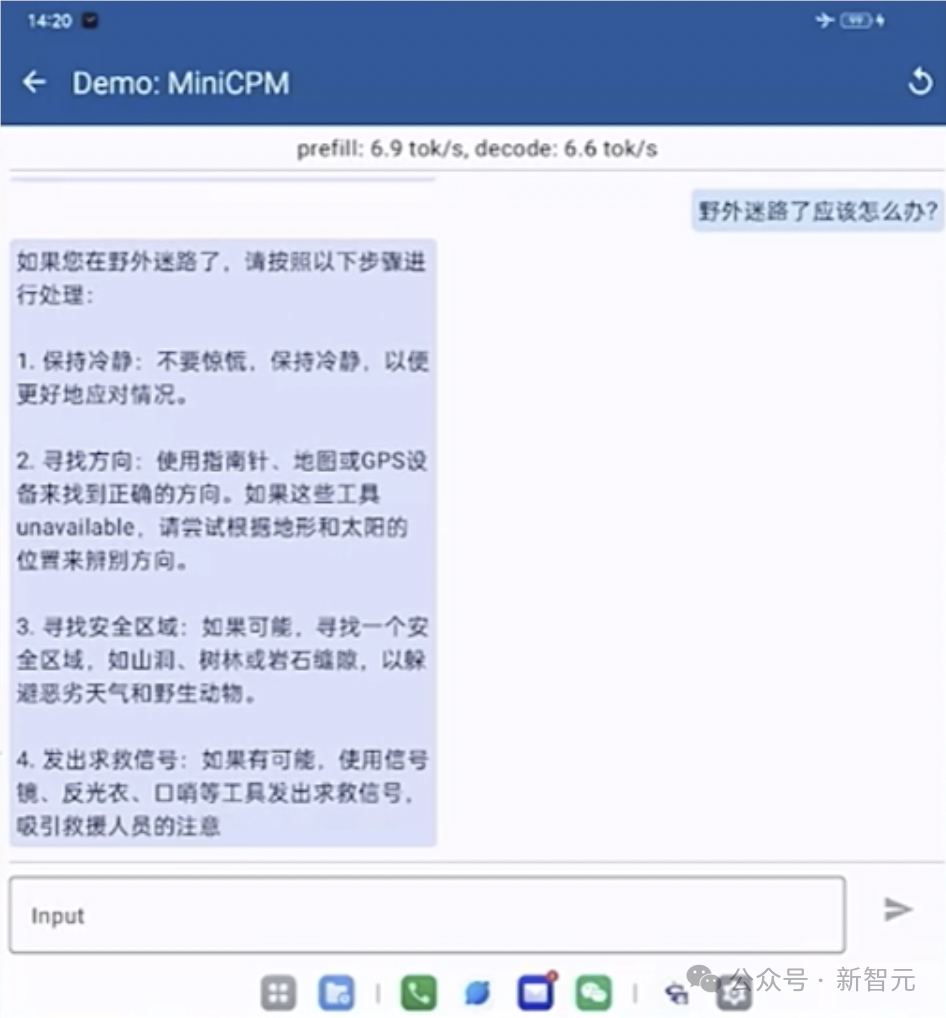
在发布会现场,团队也进行了一波端侧模型的性能演示。
首先把手机调飞行模式,然后向MiniCPM求助:野外迷路了怎么办?
当你看到一个奇怪的蘑菇时,便可求助MiniCPM,它也许就能救你一命。

打开帐篷,突然看到一条蛇怎么办?MiniCPM告诉你:有毒,走为上计!
如果不小心被咬了,必须尽快就医!

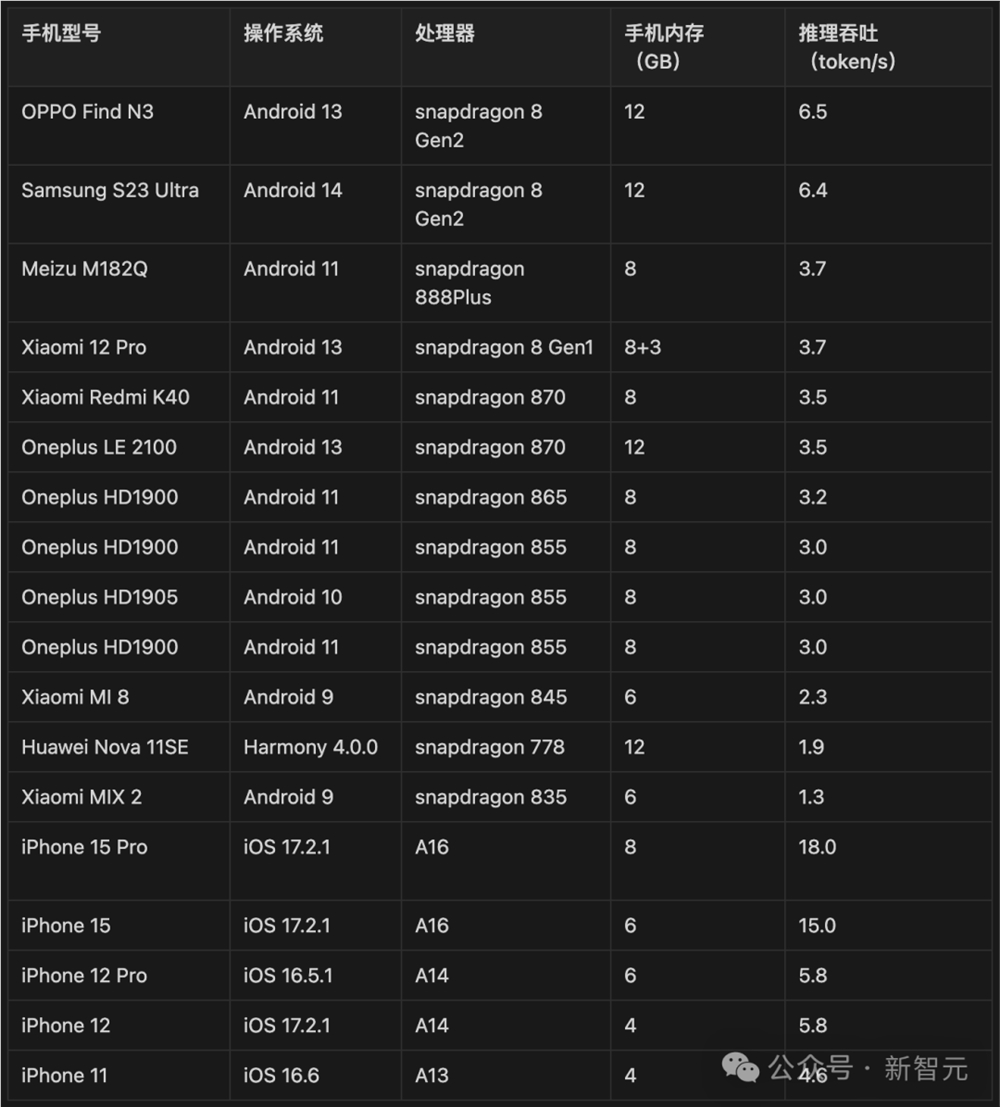
CPU搞定推理,1080Ti玩转训练微调
成本,就是大模型的隐形竞争力。
面壁智能在做商业化实践的时候,发现客户都十分关注应用模型的成本。
虽然千亿模型效果很好,但真正大规模去部署时,成本会是一个绕不开的巨大障碍。
而MiniCPM很好地解决了这个障碍,让模型的推理成本实现断崖式的下降。
在提供非常强劲的模型的同时,还能支持CPU推理,是实打实的「省钱大模型」。
其中,MiniCPM的int4量化版本,在性能几乎无损的情况下压缩了75%的尺寸,大大降低了模型对于内存和闪存的需求。

以搭载骁龙855芯片的手机为例,处理170万tokens的成本仅为1块钱,几乎只有在云端运行的Mistral-Medium的1%。

除了端侧推理的成本非常低,MiniCPM持续改进的成本也控制也异常得好。
一台电脑、一张普通的消费级显卡就能完成SFT,彻底拯救算力焦虑。

进行Int4量化后,MiniCPM只占2GB空间,具备了在端侧手机进行模型部署的条件。
对此,团队在Android和Harmony系统上使用开源框架MLC-LLM进行模型适配,在iPhone系统上使用开源框架LLMFarm进行模型适配,并分别选取了部分端侧手机设备进行了测试。
从结果来看,MiniCPM已经跑通了国际主流的手机品牌和终端CPU芯片,即使是老手机运行起来也毫无压力。
复刻Gemini演示,全程无剪辑
此次,除了MiniCPM旗舰模型外,面壁智能还开源了12B参数量的多模态大模型OmniLMM。
就拿Gemini发布当时演示「猜丁壳」的案例,OmniLMM在此的表现毫不逊色。
一只手拍摄视频,一只手做演示,然后用英文问它:我正在玩什么游戏?
它会回答:石头剪子布。它不仅能认出你出的是什么手势,还能告诉你如果要赢应该出什么。
这个过程中,OmniLMM表现出了多重能力:实时动作识别,理解玩游戏的取胜策略,还可以通过语音识别工具理解用户问题。
,时长01:07
方法说明:使用OmniLMM12B将视频帧转换成文本描述,再基于纯文本ChatGPT3.5根据文本描述和用户提问回答问题
就像之前GPT-4的演示一样,OmniLMM能够识别出图片中笑点在哪里。
这只宠物狗的自拍为啥好笑?当然是因为它一幅「人模狗样」。
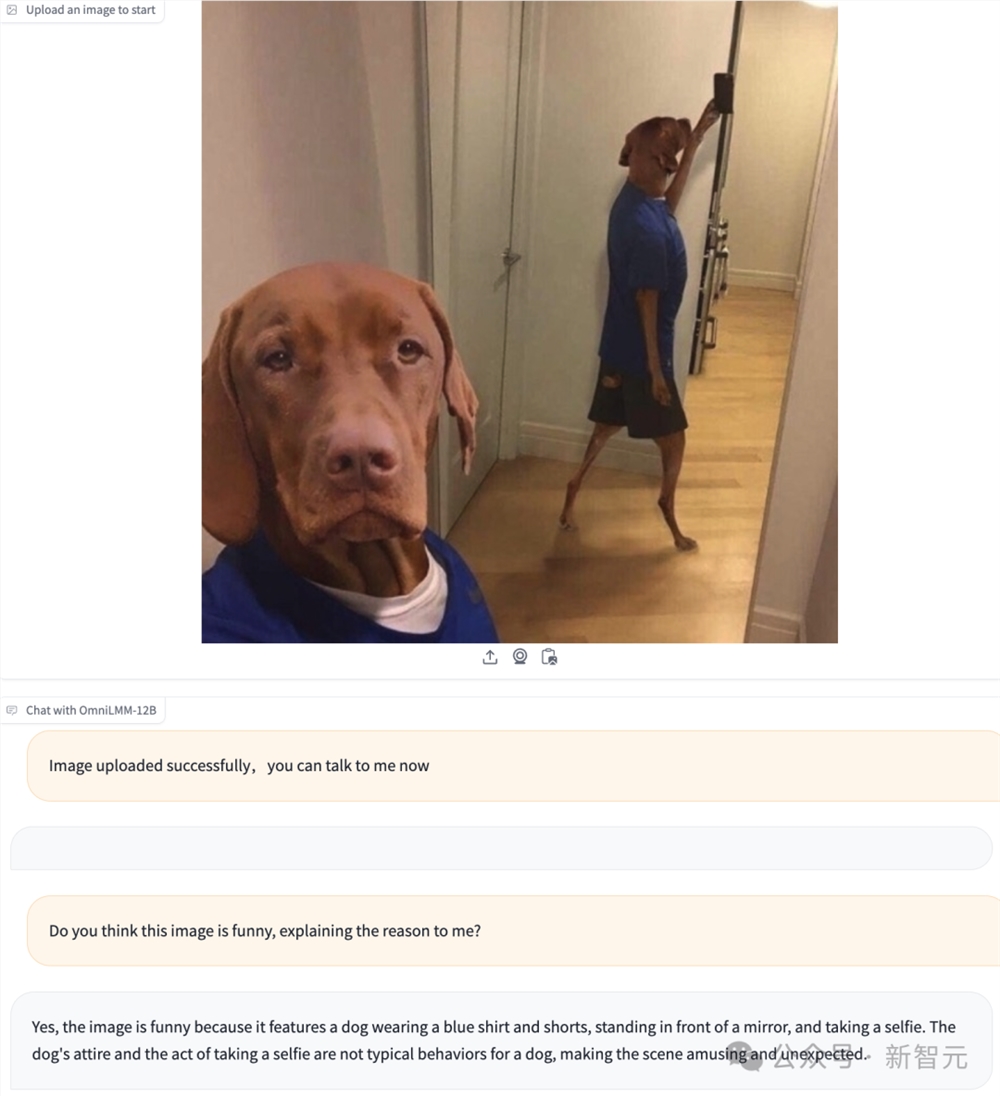
而GPT-4V的解释,似乎有些牵强,讲的是狗的表情很严肃,而人和狗的结合很搞笑,没有强调出狗会自拍这个元素。
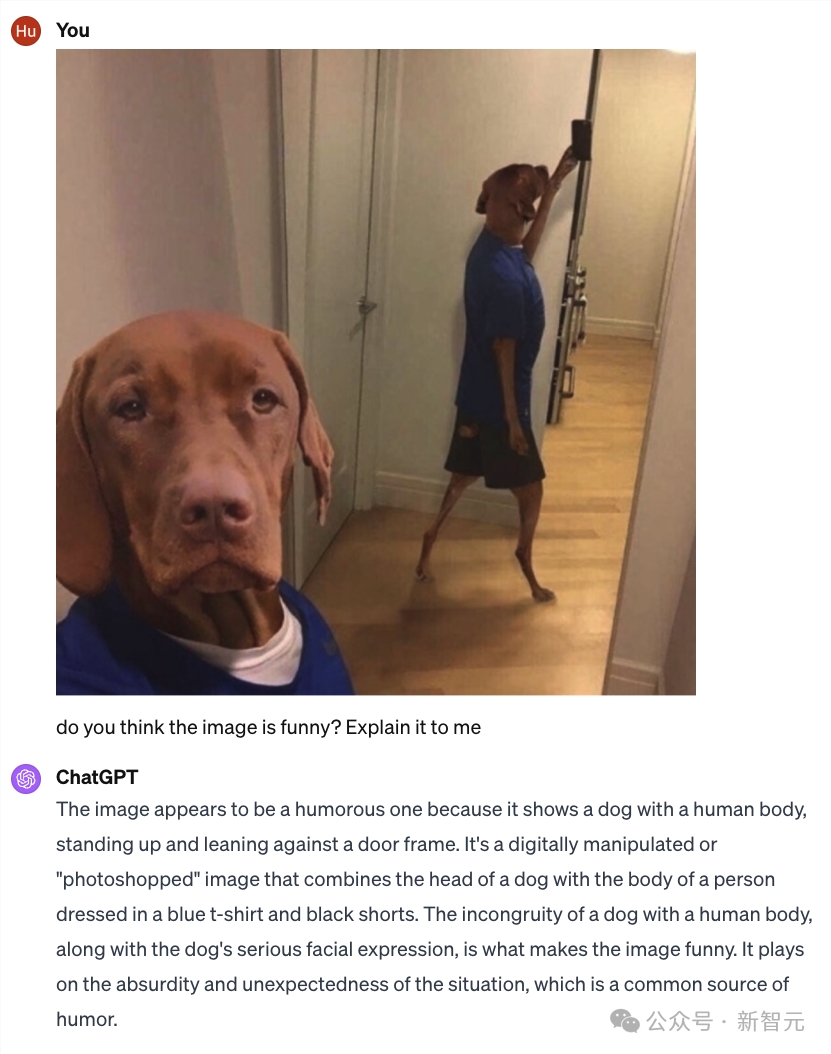
这张图片看起来很幽默,因为它显示的是一只狗与人的身体,狗站起来靠在门框上。这是一张经过数字处理或 「Photoshop 」的图片,将狗的头部与身穿蓝色T恤和黑色短裤的人的身体结合在一起。
狗与人身体的不协调,再加上狗严肃的面部表情,使这幅图像变得滑稽可笑。它利用了荒诞和出人意料的情境,而这正是幽默的常见来源。
对于视错觉的图片,OmniLMM也能准确看出其中的真相!
图中有两个人,一个人坐在椅子上,另一个人走在路上。

相比之下,GPT-4V并没有看出其实图中是两个人,完全败下阵来。
照片中可以看到一个人。这是一个从后面看到的坐在长凳上的男人。他身穿绿色条纹衬衫和深色裤子,旁边长凳的一侧披着一条蓝色毛巾或布。
他还戴着口罩,这表明照片可能是在戴口罩在公共场合很常见的时期拍摄的。照片画面中看不到其他人。

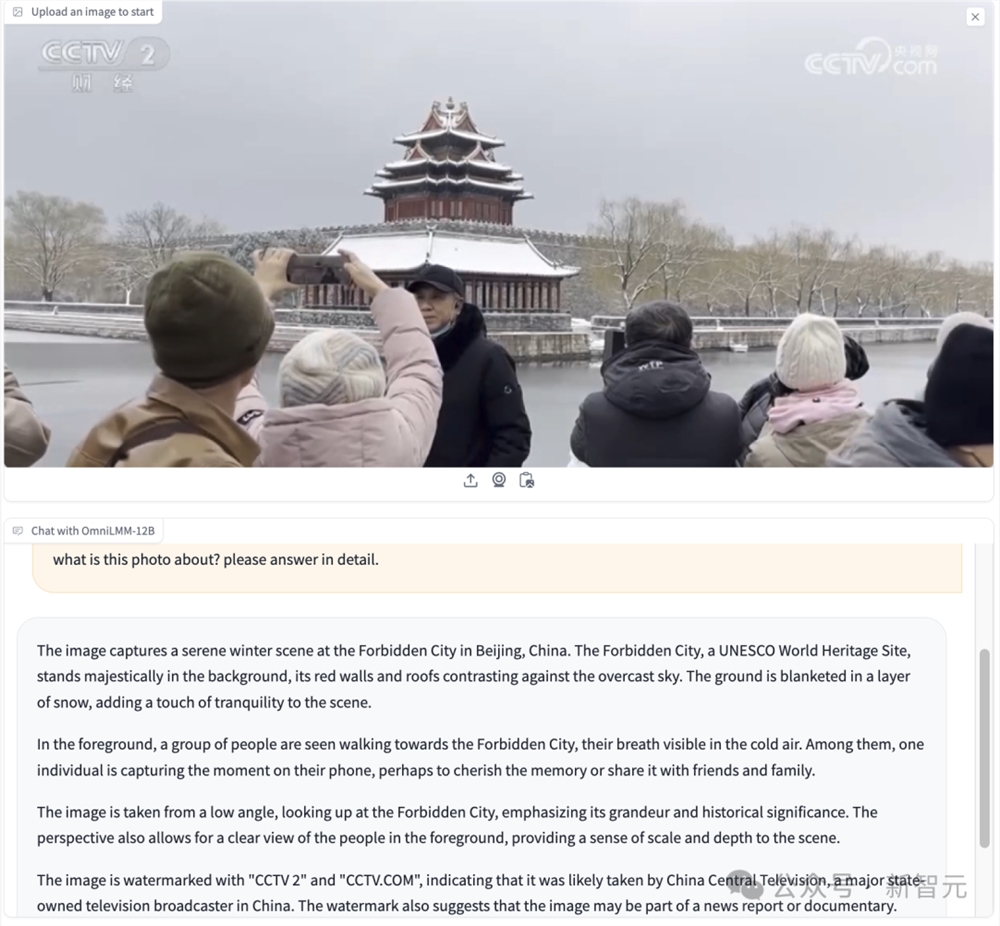
通过图片中的细节,OmniLMM还能推理出很多真实世界中的信息。
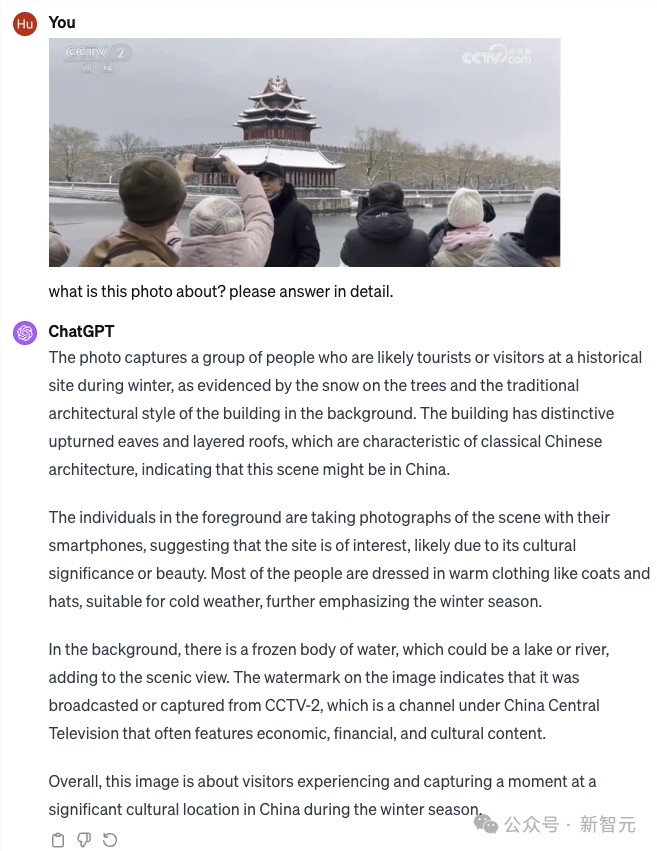
照片拍摄的是中国北京故宫宁静的冬景。故宫是联合国教科文组织世界文化遗产,巍然屹立在背景中,红色的墙壁和屋顶与阴霾的天空形成鲜明对比。地面上覆盖着一层白雪,为画面增添了一丝宁静。
前景中,一群人正走向紫禁城,寒冷的空气中,他们的呼吸清晰可见。其中,有一个人正在用手机捕捉这一刻,或许是为了珍藏记忆,或许是为了与亲朋好友分享。
画面从低角度仰望故宫,突出了故宫的宏伟和历史意义。这一视角还能清晰地看到前景中的人物,使场景更具规模感和纵深感。
图片上有「CCTV2」和「CCTV.COM 」的水印,表明很可能是由中国中央电视台拍摄的。水印还表明,该图像可能是新闻报道或纪录片的一部分。
而GPT-4V对于中国场景的了解确实还是不如我们国产模型,没有识别出故宫,但是看出了CCTV-2,整体上两边解释的程度区别不大。
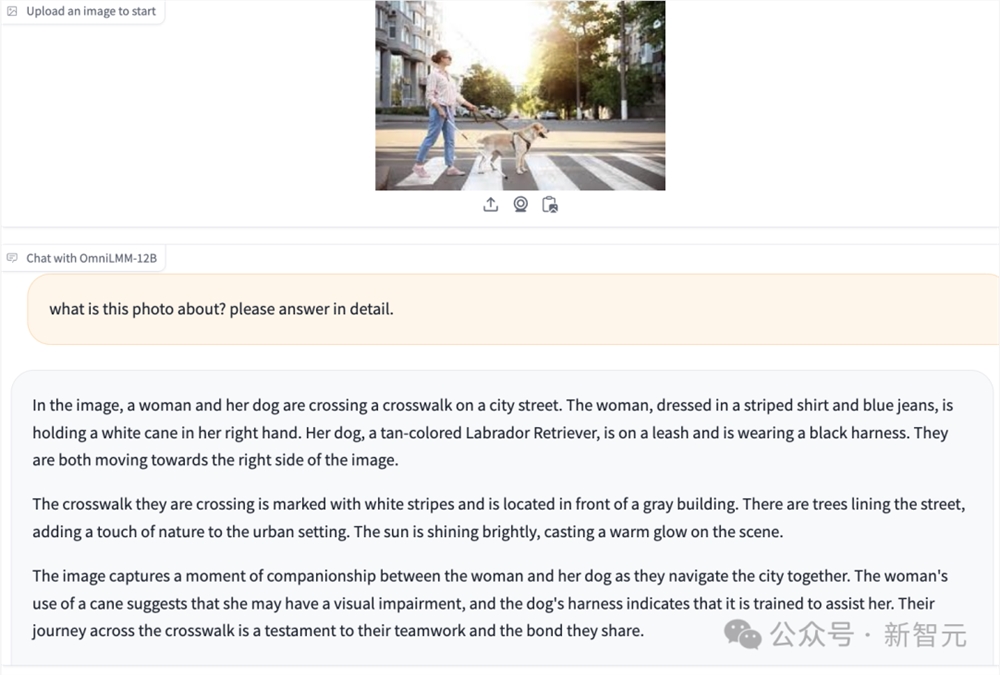
对于没有文字说明的图片,OmniLMM甚至可以根据服装,亦或者墨镜和导盲杖等小细节精准推断出图片表达的含义,充分展现了其「会看会思考」的综合能力。
画面中,一名女士和她的狗正在穿过城市街道上的人行横道。这名女士身穿条纹衬衫和蓝色牛仔裤,右手拿着一根白色手杖。她的爱犬是一只棕褐色的拉布拉多犬,拴着皮带,戴着黑色安全带。她们都在向画面右侧移动。
她们穿过的人行横道上有白色条纹,位于一栋灰色建筑前。街道两旁绿树成荫,为城市环境增添了一丝自然气息。艳阳高照,投射出温暖的光辉。
画面捕捉了这位女士和她的爱犬在城市中相伴前行的瞬间。女人使用的拐杖表明她可能有视力障碍,而狗的背带表明它受过训练,可以帮助她。他们穿过人行横道的旅程见证了他们的团队合作和共同的纽带。
以小博大,实力在哪?
端侧模型的发展,已经半年多了。去年七月开始,很多厂商都入局了端侧大模型。
面壁智能这一系列在大模型上取得的突破,都来源于他们强大的团队和多年的技术积累。
2021年,面壁智能就构建了高效的技术优势,集中在Infra、算法和数据方法论这三个方向中。

算力 算法 数据
可以说,Infra能力是大模型创业的护城河,因为Infra会决定公司的技术上限。
没有好的Infra,很容易遇到模型调优的天花板。想做更深入的工作时,往往会受到Infra的限制。

而面壁智能在21年就已经开发出了BMtrain分布式训练框架,在Infra上有了很长时间的沉淀。
在算法层面,面壁智能积攒了「模型沙盒」技术。
三年实践中总结出的这个模型方法论,让大模型炼丹变成了实验科学。
他们找到了各个尺寸模型训练的超参和训练过程的最优解。
在发布MiniCPM之前,研究者做了上千次模型沙盒实验,探索出了一系列业界最优配置。
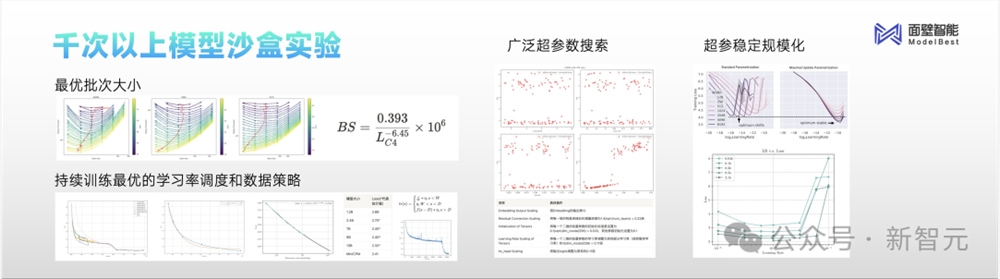
比如全新提出的WSD学习率优化器,可以在任何阶段退火,取得该阶段最优的模型。而之前的Cosine LRS方法,却无法实现,因为持续训练的情况下不是最优的。
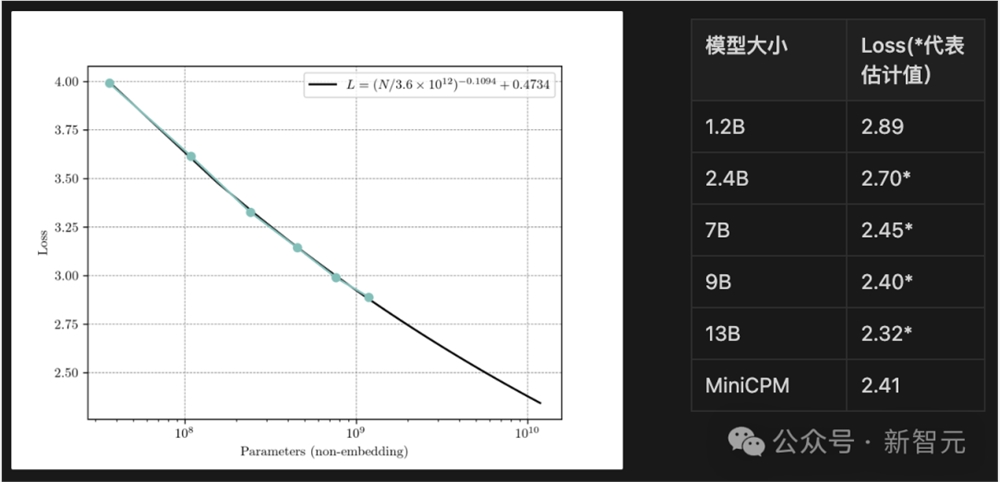
同时,通过在MiniCPM上验证6种参数模型,可以预测到参数规模越小,Loss值便会增大。MiniCPM的最终C4Loss为2.41,接近于9B的Chinchilla Optimal模型。
此外,面壁也积累了大量的高质量数据。
MiniCPM的训练十分高效,只用了高质量数据集中1T的tokens,当然,都是来自于模型训练方法论指导筛选出来的数据。
1T tokens超越Mistral-7B,就是这么来的。
为了促进行业发展,面壁智能开源了两个阶段的数据配方。
1. 稳定训练阶段
在此阶段,使用1T的去重后的数据,其中大部分数据从开源数据中收集来,比例如下图。
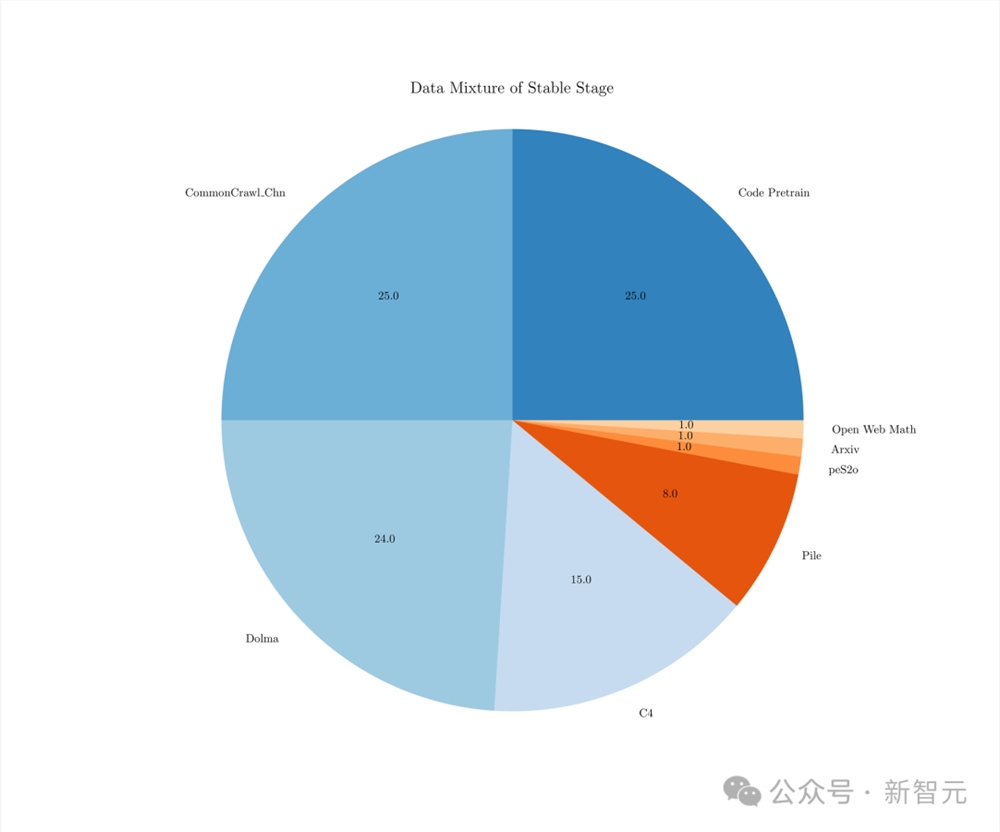
研究团队使用了模型沙盒实验中探索出的最优配置,WSD LRS,batchsize为3.93M,Max Learning Rate为0.01。
2. 退火阶段
在此阶段,SFT数据配比如下:
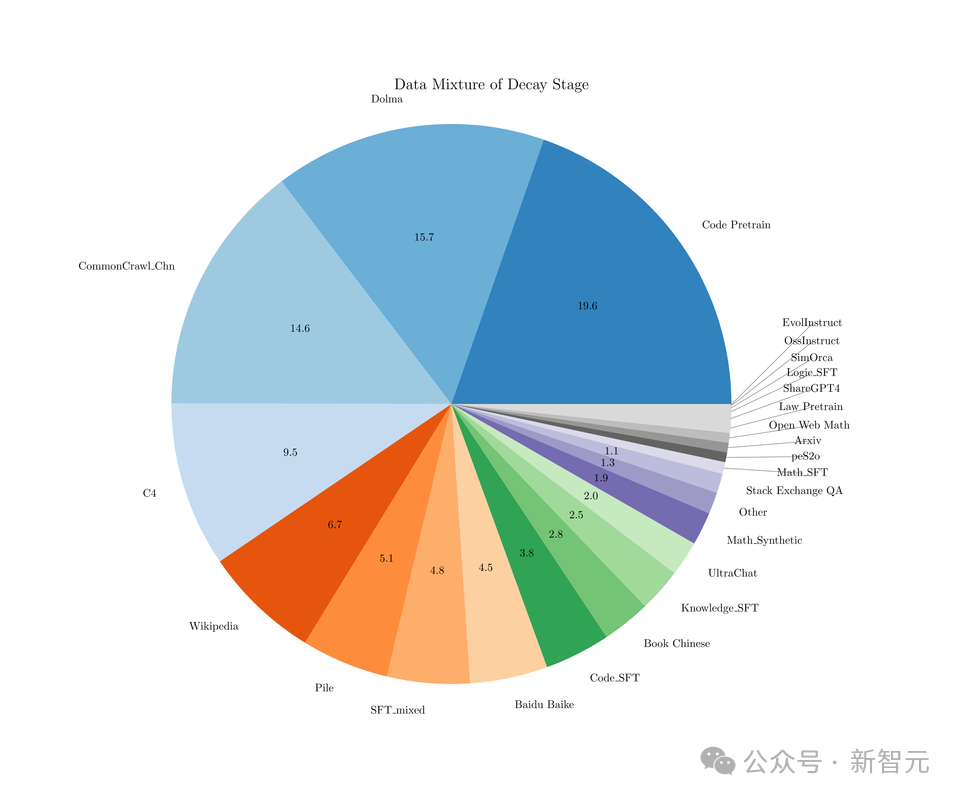
在263000步(约1T数据)时,开始进行退火,退火过程也变现出了损失函数急剧下降的现象,同时在各种任务数据、SFT数据上的Loss也有显著下降。
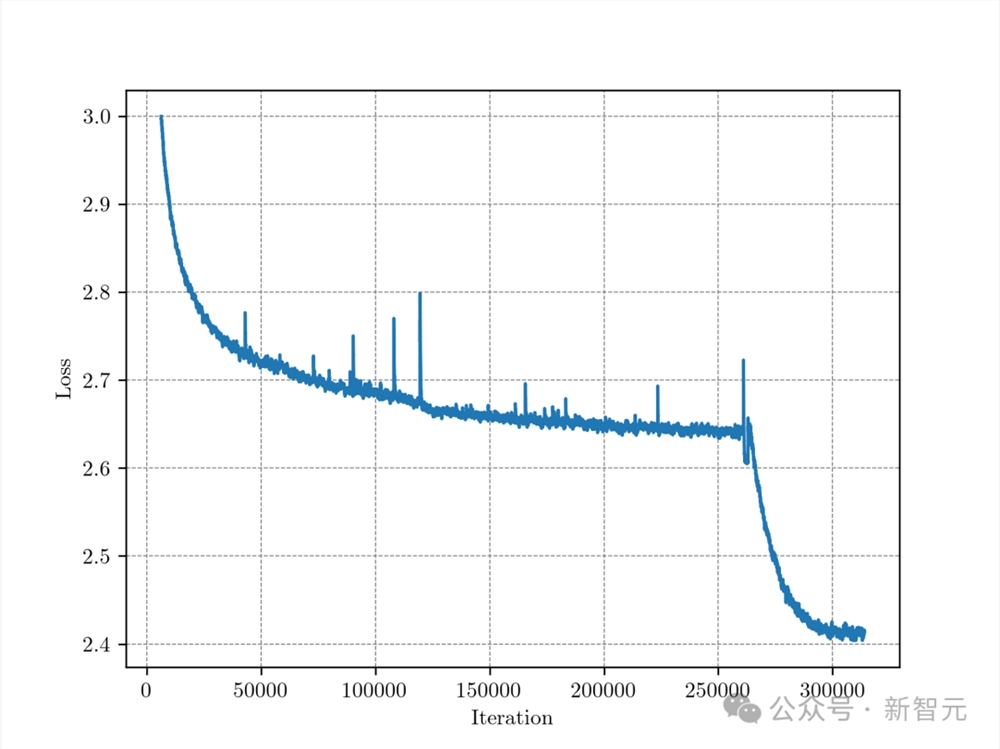
整个训练过程中,C4训练集上Loss
「宇宙中心」大模型 Agent早期实践者
在2023大模型元年里,五道口大模型Vally纷纷汇聚了百川智能、面壁智能、智谱华章等中国主流大模型创业公司,以及智源研究院这样杰出的研究机构。
若说其中,最早开始大模型 Agent的研究者,便是面壁智能了。
成立于2022年8月,这家初创公司的创始团队来自于清华计算机系,这样的强大背景就注定了它将来的不凡。

谁能想到,这家公司才刚满1岁
明星团队,「双CP」领军组合
据介绍,面壁智能团队有100 人的明星科研团队,而且是80%清北含量,平均年龄28岁。
其中一位带头人——刘知远是深度学习、BERT、大模型、Agent四次重要技术方向的推动者,沉淀积累了大量的经验。在四次变革中,他都找对了方向,让面壁智能能始终引领热点。
他曾在2018年帮助推动清华NLP实验室研究路线转型,并推出了全球首个知识指导的预训练模型ERNIE。
刘知远与另一位联合创始人李大海、CTO曾国洋、首席研究员韩旭并称为「双CP」领军组合。

其中曾国洋还是悟道中文预训练模型团队骨干成员,2020年12月发布全球第一个20亿中文开源大模型CPM。
2022年4月,清华NLP实验室联手智源发起开源社区OpenBMB。

成立1年以来,面壁智能连续发布了多款模型,如CPM-Bee、CPM-Cricket,智能对话助手面壁露卡,以及在2023下半年密集发布了Agent产品,全都体现了这家公司厚和广的基础积累。
从Mistral AI的成功,我们能看到,一家能在AI赛道上做出有影响力产品的初创公司,团队一定以科学家为主,研究能力强,且技术栈全面,互补的。

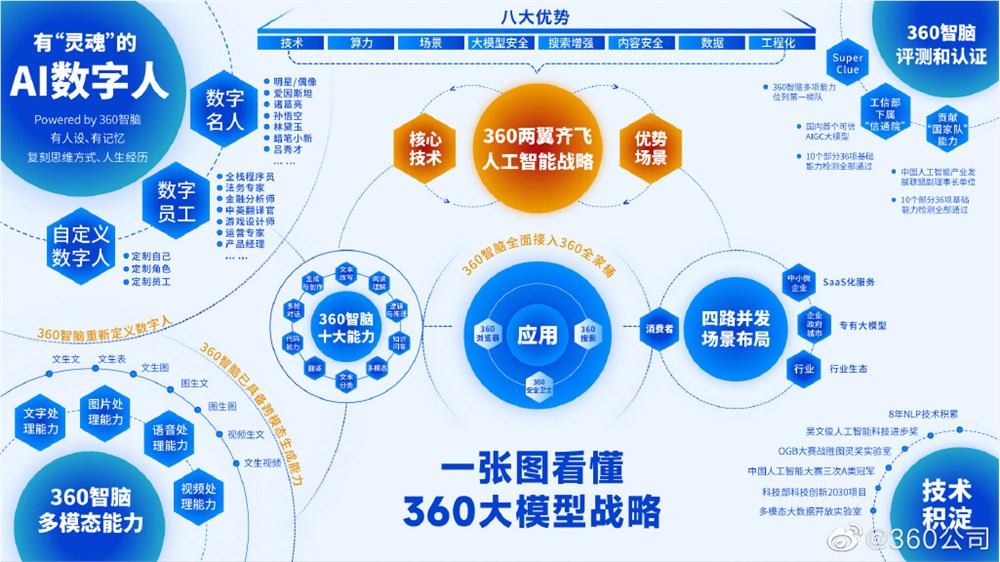
而现在,面壁智能也形成了全面的产品线,包括大模型C系、O系、Mini系,Agent宇宙,高效Infra。
One More Thing
春节假期马上就到了,过年嗑瓜子,不如嗑「CP神器」——心间。
在这个App上,不光有李白杜甫、清华北大的CP,或许,你还可以找到平行宇宙的ta。


 0000
0000- 0000
- 0005
- 0000
- 0000