Parrot提出新型多重奖励强化学习框架以改进文本生成图像
**划重点:**
- 🔄 **多奖励优化:** Parrot是一种用于文本生成图像的多重奖励强化学习(RL)框架,采用联合优化方法,有效解决了奖励过度优化和降级问题。
- 📊 **质量度量改进:** 与使用单一奖励模型相比,Parrot框架在美学、图像情感和人类喜好等多个质量指标上取得了显著改进。
- 🌐 **伦理关切:** 尽管Parrot在提高图像质量方面取得了成功,但其对现有度量的依赖存在一定限制,并引发了对其潜在生成不当内容的伦理关切。
在使用强化学习(RL)进行文本生成图像(T2I)时,质量奖励成为一个紧迫问题。尽管观察到通过强化学习RL可能提高图像质量,但多个奖励的聚合可能导致在某些度量中过度优化而在其他度量中降级。手动确定最佳权重变得困难,因此需要一种在RL中联合优化多个奖励的有效策略。
已提出各种T2I生成模型,如使用LLMs的稳定扩散模型,利用潜在文本表示。在评估生成的图像质量时,考虑了多个质量度量,包括美学、人类偏好、图像文本对齐和图像情感。RL微调通过将去噪视为多步决策任务,在人类偏好学习方面表现出优越性。其中一个例子是Promptist,它使用对齐和美学分数作为奖励,对提示扩展模型进行微调。然而,它在联合微调T2I模型方面表现不足,限制了其适应图像生成任务的能力。
谷歌DeepMind和OpenAI的研究人员与Rutgers University和Korea University合作提出了Parrot,这是一种新颖的T2I生成的多重奖励RL框架,采用联合优化方法,用于T2I模型和提示扩展网络,以增强生成质量感知的文本提示。该方法在推断时引入了原始的以提示为中心的指导,以抵消对原始提示的潜在遗忘。
Parrot使用奖励特定标识符引入偏好信息,自动确定每个奖励目标的重要性。在Promptist数据集上进行了提示扩展网络的监督微调,用于RL训练。基于稳定扩散1.5的JAX版本的T2I模型使用LAION-5B数据集进行预训练。使用策略梯度算法实现对RL T2I扩散模型的微调,将去噪过程视为马尔可夫决策过程。
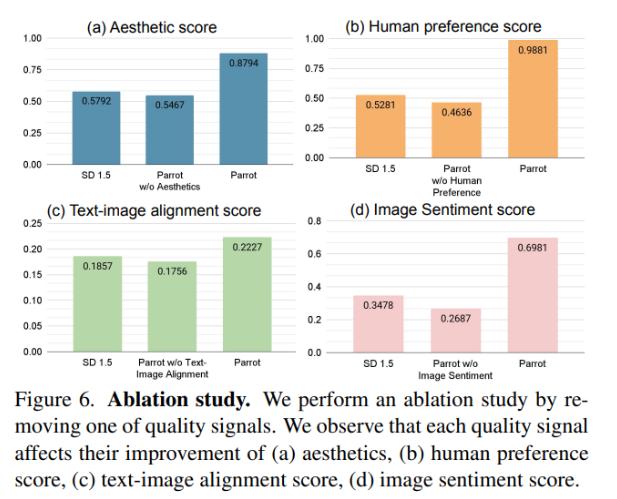
与使用单一奖励模型相比,该框架还改善了多个质量指标,如美学、图像情感和人类喜好。其原始的以提示为中心的引导有效解决了通过添加上下文而压倒主要内容的问题,从而生成了忠实于原始提示并包含视觉上令人愉悦的细节的图像。
尽管Parrot在有效性上表现出色,但对现有度量的依赖存在限制,强调了对进展的需求。Parrot对更广泛奖励的适应性提高了其在量化图像质量方面的适用性。但在Parrot潜在生成不当内容的能力方面引发了伦理关切,强调了在部署中进行审查和伦理考虑的必要性。
论文网址:https://arxiv.org/abs/2401.05675
- 0000
- 0000
- 0000
- 0000
- 0000