谷歌研究团队推新AI方法SynCLR:从合成图像和字幕中学习视觉表征
划重点:
- 💡 SynCLR是一种新颖的人工智能方法,通过合成图像和合成字幕,实现对视觉表征的学习,无需使用真实数据。
- 💡 该方法通过三个阶段实现,包括合成图片字幕、生成合成图像和字幕,以及训练视觉表征模型。
- 💡 研究结果表明,SynCLR在图像分类、细粒度分类和语义分割等任务上表现出色,显示了利用合成数据训练强大AI模型的潜力。
近期,Google Research和MIT CSAIL共同推出了一项名为SynCLR的新型人工智能方法,该方法旨在通过使用合成图像和字幕,实现对视觉表征的学习,摆脱对真实数据的依赖。
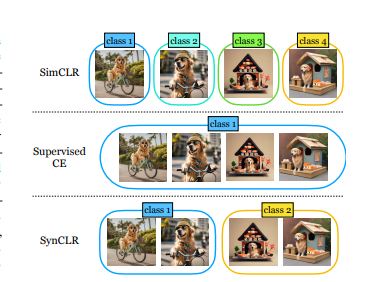
SynCLR的工作原理
研究团队首先提出了一个三阶段的方法。首先,在“合成图片字幕”阶段,他们采用大型语言模型的上下文学习能力,通过单词到字幕的转换示例,生成了大量的图片字幕。接着,在“生成合成图像和字幕”阶段,利用文本到图像扩散模型,生成了包含6亿张合成图片的数据集。最后,在“训练视觉表征模型”阶段,研究团队使用了掩蔽图像建模和多正对比学习,训练模型从合成数据中学到有意义的表征。
实验结果
研究结果表明,SynCLR在多个任务上取得了令人瞩目的成绩。通过与现有模型如CLIP和DINO v2进行比较,SynCLR在ImageNet-1K上的线性探测准确率以及细粒度分类和ADE20k上的语义分割任务上都表现出色。特别值得一提的是,SynCLR在以字幕为级别的细粒度上的优越性,为模型的可扩展性和在线类别增强提供了便利。
尽管SynCLR在合成数据上展现出了强大的性能,研究团队也提出了一些改进方向。其中包括使用更复杂的大型语言模型、优化不同概念之间的样本比例、探索高分辨率训练阶段等。这些改进有望进一步提升合成数据在训练人工智能模型中的效果。
项目网址:https://github.com/google-research/syn-rep-learn
论文网址:https://arxiv.org/pdf/2312.17742.pdf
 0000
0000- 0000
- 0001
- 0000
- 0000