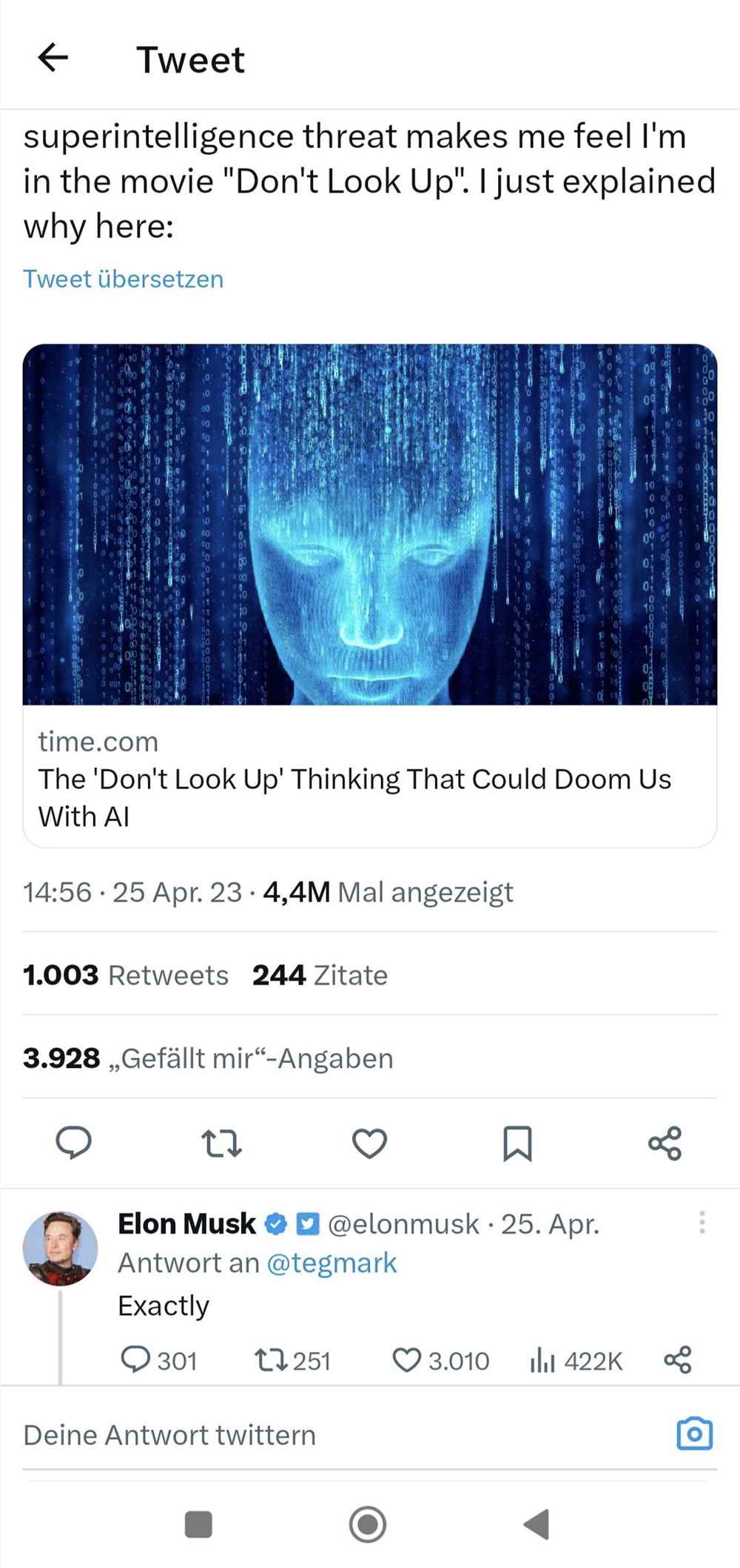
美国立法者提案 要求基础模型披露训练数据来源
站长之家(ChinaZ.com) 12月25日 消息:近日,美国两名立法者提出了一项法案,要求基础模型的创建者披露训练数据的来源,以便版权所有者知道他们的信息被盗用。
由众议员安娜·埃索 (Anna Eshoo) 和唐·贝尔 (Don Beyer) 提交的《人工智能基金会模型透明度法案》将指示联邦贸易委员会 (FTC) 与国家标准与技术研究所 (NIST) 合作,建立报告培训数据透明度的规则。
图源备注:图片由AI生成,图片授权服务商Midjourney
制作基础模型的公司将被要求报告训练数据的来源以及在推理过程中如何保留数据,描述模型的局限性或风险,模型如何与 NIST 计划的人工智能风险管理框架和任何其他联邦标准保持一致可能会建立,并提供有关用于训练和运行模型的计算能力的信息。
该法案还规定,人工智能开发人员必须向该模型“红队”报告,以防止其在医疗或健康相关问题、生物合成、网络安全、选举、治安、金融贷款决策、教育、就业决策、公共服务和儿童等弱势群体。
该法案强调了围绕版权进行数据透明度培训的重要性,因为已经有几起针对人工智能公司涉嫌侵犯版权的诉讼。它特别提到了艺术家针对 Stability AI、Midjourney 和 Deviant Art 的案件,以及 Getty Images 针对 Stability AI 的投诉。
该法案指出:“随着公众使用人工智能的机会增加,诉讼和公众对侵犯版权的担忧也有所增加。” “基础模型的公开使用导致无数次向公众提供不准确、不精确或有偏见的信息。”
该法案仍需要分配给一个委员会并进行讨论,目前尚不清楚这是否会在繁忙的竞选季节开始之前发生。
Eshoo 和 Beyer 的法案补充了拜登政府的人工智能行政命令,这有助于建立人工智能模型的报告标准。然而,该行政命令不是法律,因此如果《人工智能基金会模型透明度法案》通过,它将把训练数据的透明度要求纳入联邦规则。
这项法案的提出是人工智能发展过程中的一个重要里程碑,它将有助于保护版权所有者和促进人工智能的负责任使用。
- 0000


 0000
0000- 0000
- 0000
 0000
0000