OpenAI「登月计划」剑指超级AI!LeCun提出AGI之路七阶段,打造世界模型是首位
通用AGI,或许近在咫尺。
OpenAI下一步「登月计划」,就是实现人类期待已久的超级人工智能,而到达这一步的前提是——解决超级AI对齐问题。

就在前几天,首席科学家Ilya带头OpenAI超级对齐团队取了的实质性成果。他们发表的最新论文,首次确定了超级AI对齐的研究方向:
即小模型监督大模型。
实证表明,GPT-2可以用来激发GPT-4的大部分能力,能够达到GPT-3.5的性能。甚至还可以泛化到小模型失败难题上。
其中,官方博客的第一句便是:我们相信超级智能可能会在未来10年内出现。

再加上传闻中即将面世的GPT-4.5,以及或许会在明年诞生的GPT-5,OpenAI似乎已经准备好迎接超级人工智能到来了。
然而,在LeCun看来,「超人AI」的发展不会一蹴而就,而是要经历多个阶段逐渐完成。

第一阶段:学习世界运作方式
首先,是构建能像小动物一样学习世界运作方式的系统——可以观察环境并从中学习,为发展更高级的AI能力打下基础。而这也是AI进化的关键一步。
相比之下,如今的语言模型如GPT-4或Gemini,主要关注的还是文本数据,这显然远远不够。
LeCun经常嘲讽当前AI的一句话是,「如今大模型的智力连猫狗都不如」。甚至在他看来,通往AGI路上,大模型就是在走歪路。

一直以来,他坚信世界有一种「世界模型」,并着力开发一种新的类似大脑的AI架构,目的是通过更真实地模拟现实世界来解决当前系统的局限性,例如幻觉和逻辑上的缺陷。
这也是想要AI接近人类智力水平,需要像婴儿一样学习世界运作的方式。
这个世界模型的架构,由6个独立的模块组成:配置器模块、感知模块、世界模型模块、成本模块、短期记忆模块,以及参与者模块。
其中,核心是世界模型模块,旨在根据来自感知模块的信息预测世界。能够感知人在向哪移动?汽车是转弯还是继续直行?
另外,世界模型必须学习世界的抽象表示,保留重要的细节,并忽略不重要的细节。然后,它必须在与任务水平相适应的抽象级别上提供预测。
LeCun认为「联合嵌入预测架构」(JEPA)能够解决这个难题。JEPA支持对大量复杂数据进行无监督学习,同时生成抽象表示。
今年6月,基于「世界模型」的愿景,他又提出了一个全新架构I-JEPA。

论文地址:https://ai.meta.com/blog/yann-lecun-ai-model-i-jepa/
不过,LeCun更高层次的愿景留下了许多未解决的问题,例如关于世界模型的架构和训练方法的细节。
第二阶段:目标驱动且有保护措施的系统
其次,是构建目标驱动并在一定的保护措施下运作的机器。
这些保护措施将确保AI系统在追求目标时仍然安全可控。
第三阶段:规划与推理
随着AI系统的不断成熟,它们将发展出规划和推理的能力,从而在遵守安全规范的前提下,实现既定目标。
这将使AI系统能够基于对世界的理解做出更加明智的决策,并采取合适的行动。
第四阶段:分层规划
再进一步,AI系统将能够进行分层规划,从而大幅提升决策能力。
这将使AI系统更加高效地处理复杂任务和难题。
第五阶段:增强机器智能
随着AI的进化,这些系统的智能将从最初的老鼠提升至类似狗或者乌鸦的水平。
在此过程中,为确保AI系统保持可控和安全,将需要不断对其保护措施进行调整。
第六阶段:更广泛的训练与微调
当AI系统达到一定的智能水平时,就需要将它们放在不同环境和任务中接受训练,使其更加灵活,能够应对各种挑战。
随后,还需要对AI系统进行微调,以便在特定任务上表现出色。
第七阶段:超人类AI的时代
总有一天,我们开发的AI系统会在几乎所有的领域超越人类智能。
但这并不意味着这些系统具备情感或意识。只不过是在执行任务方面,会比人类做得更好。
同时,即使这些高级AI系统智力超群,它们也必须始终受到人类的控制。
根据LeCun之前提出的观点,这理论上是可行的:由于智力水平与主导欲望之间并无直接联系,而AI并不像人类那样具有天生的主导欲望。因此,AI或许会愿意为智力上不及它们的人类服务。
当然,这种情况在未来5年内不太可能出现。
LLM自我迭代,走向AGI
为了让超级AI系统能够迭代学习,持续完成任务并不断改进效果,当前的许多框架采用了可识别的过程。
类似于下图中的结构,包括反馈控制和强化学习。
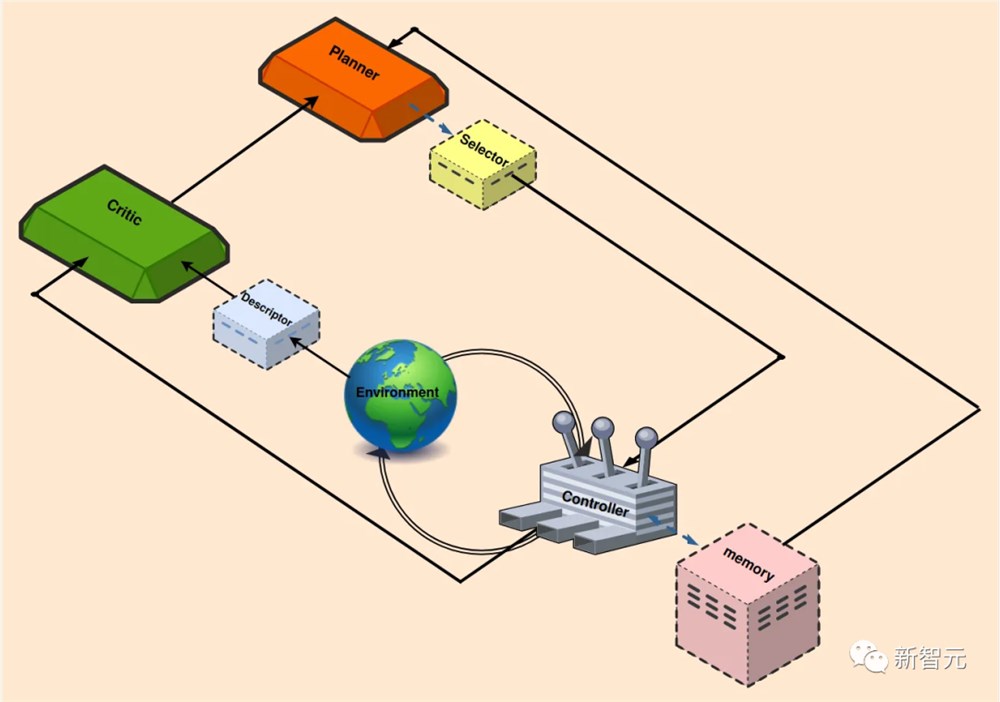
另外,还可以采用一些附加功能,以最大限度地减少人工输入并增强流程自动化。
那么,上面展示的迭代学习系统是如何运行的?
首先,人类将广义定义的任务分配给智能体。
任务通常采取提示的形式,概述主要目标,例如,「探索环境,并完成尽可能多的不同任务」。
Planner(规划)模块以这个目标为条件,将目标分解为一系列可执行的、可理解的任务。
由于LLM已经在大量数据上进行了训练,充分了解智能体运行的环境,可以很好地支持目标分解。此外,还可以补充上下文来增强LLM的性能。
当Planner提供了一组派生的子任务后,Selector负责确定最合适的下一个子任务(满足先决条件,且能产生最佳结果)。
Controller的工作是生成当前子任务所需要的操作。然后,生成的操作被引入到环境中。
在这个过程中,使用Memory块检索最相似的学习任务,将它们集成到其正在进行的工作流中。
为了评估最近操作的影响,Critic会监视环境状态,提供反馈,包括识别缺点和失败原因等。
Descriptor块把环境和智能体的状态描述为文本,作为Critic的输入,然后,Critic为Planner提供全面的反馈,以协助进行下一次试验。

下面来看一下系统中每个模块的一些具体细节。
规划(Planner)
Planner负责组织整个任务,根据智能体的当前状态和水平来协调学习过程。
通常会假设基于LLM的Planner在训练中接触过类似的任务分解过程,但这个假设在这里并不成立。
因此,研究人员提出了一种方法:从环境手册文本中提取所有相关信息,总结成一个小尺寸的上下文,并连接到提示中。
在现实生活中的应用程序中,智能体会遇到各种不同复杂程度的环境,这种简单而有效的方法,可以避免频繁为新任务进行微调。
Planner模块与VOYAGER和DEPS在某些方面类似。
VOYAGER使用 GPT-4作为自动课程模块,试图根据探索进度和智能体的状态提出越来越难的任务。它的提示包括:
在设定约束条件的同时鼓励探索;
当前智能体的状态;
以前完成和失败的任务,
来自另一个GPT-3.5自问答模块的任何其他上下文。
然后,VOYAGER输出要由智能体完成的任务。
DEPS在不同环境中使用CODEX、GPT-4、ChatGPT和GPT-3作为LLM规划器,提示内容包括:
强大的最终目标(例如,在Minecraft环境中获得钻石);
最近生成的计划;
对环境的描述和解释。
为了提高计划的效率,DEPS还提出了一个状态感知选择器,从规划器生成的候选目标集中,根据当前状态选择最近的目标。
在复杂的环境中,通常存在多个可行的计划,优先考虑更接近的目标可以提高计划效率。
为此,研究人员使用离线轨迹训练了一个神经网络,根据在当前状态下完成给定目标所需的时间步长进行预测和排名。然后,Planner与Selector协作生成一系列要完成的任务。
控制(Controller)
Controller的职责是选择下一个动作来完成给定的任务。
Controller可以是一个LLM(例如VOYAGER),也可以是深度强化学习模型(例如DEPS),根据状态和给定任务生成操作。
VOYAGER在交互式提示中使用GPT-4来扮演控制器的角色。
VOYAGER、Progprompt和CaP选择使用代码作为操作空间,因为代码可以自然地表示时间扩展和组合操作。在VOYAGER中生成代码的提示包括:
代码生成动机指南;
可用的控制基元API列表及其描述;
从记忆中检索到的相关技能或代码;
上一轮生成的代码、环境反馈、执行错误、Critic输出;
当前状态;
思维链提示在代码生成前进行推理。
记忆(Memory)
人类的记忆一般可以分为短期记忆和长期记忆:
短期记忆存储用于学习和推理等任务的信息,可容纳大约7件物品,持续约20-30秒。
所有基于LLM的终身学习方法,都是通过上下文学习来使用短期记忆,而上下文学习受到LLM上下文长度的限制。
长期记忆用于长时间存储和检索信息,可以作为具有快速检索功能的外部向量存储来实现。
VOYAGER通过添加/检索从外部向量存储中学习到的技能,从长期记忆中受益。
如下图所示,上半部分描述了VOYAGER添加新技能的过程,下半部分表示技能检索。
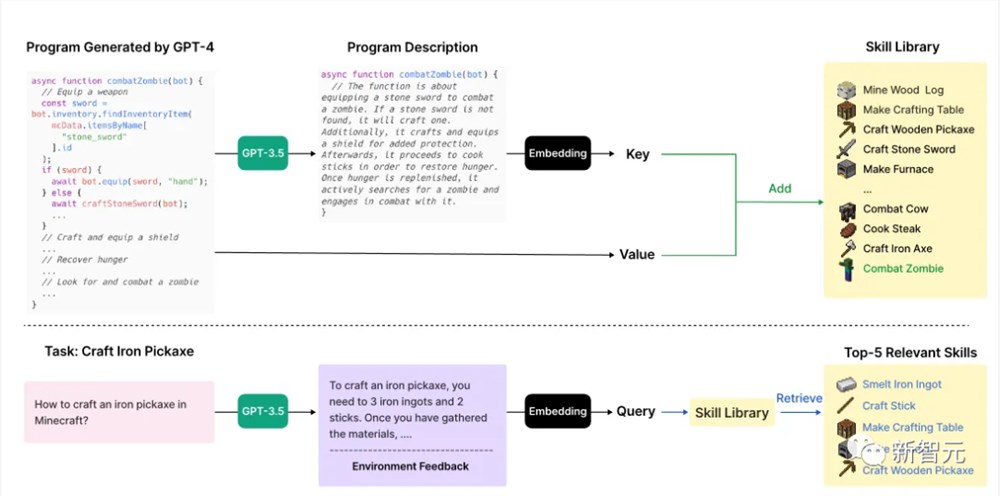
当Critic验证代码可以完成任务时,使用GPT-3.5生成代码的描述。
然后,技能将被以键值对的形式(技能描述和代码)存储在技能库中。
当Planner生成一项新任务时,GPT-3.5会生成新的描述,然后从技能库中检索前5个相关技能。
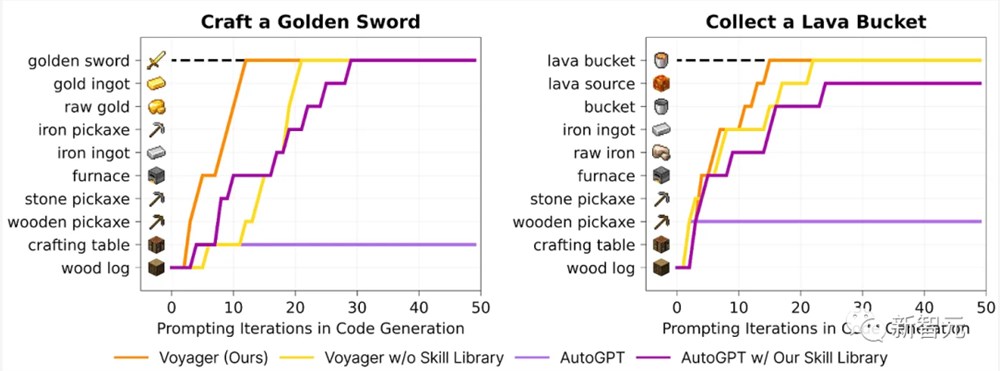
添加长期内存可以显著提高性能。上图展示了技能库对VOYAGER的重要性。
Controller同时利用短期记忆和长期记忆,以生成和完善其策略。
评论(Critic)
Critic也是一个基于LLM的模块,它对先前执行的计划进行点评,并提供反馈。
Critic可以采用GPT-4,利用奖励信号、当前轨迹以及持久记忆来生成反馈,这种反馈比标量奖励提供了更多的信息,并存储在内存中,供Planner用于优化计划。
描述(Descriptor)
在基于LLM的终身学习中,Planner的输入和输出是文本。
虽然很多环境(如Crafter)是基于文本的,但有一些其他环境,会返回2D或3D图像的渲染,或者返回一些状态变量。
这时,Descriptor就可以充当中间的桥梁,将其他模态转换为文本,并将它们合并到LLM的提示中。
自主AI智能体
以上主要讨论了将基础模型与持续学习相结合的最新研究,这是实现AGI的重要一步。
而最近的AutoGPT和BabyAGI等几个工作又带给人们新的启发。
这些系统接受任务后,将任务分解为子任务,自动进行提示和响应,并重复执行,直到实现提供的目标。
他们还可以访问不同的API,或者访问互联网,大大扩展自己的应用范围。
AutoGPT可以访问互联网,并能够与在线和本地的应用程序、软件和服务进行交互。
为了实现人类给出的更高层次的目标,AutoGPT使用一种称为Reason and ACT (ReACT)的提示格式。
ReACT使智能体能够接收输入、理解并采取行动、根据结果进行推理,然后在需要时重新运行该循环。
由于AutoGPT可以自己提示自己,所以可以在完成任务的同时进行思考和推理,寻找解决方案,丢弃不成功的解决方案,并考虑不同的选择。
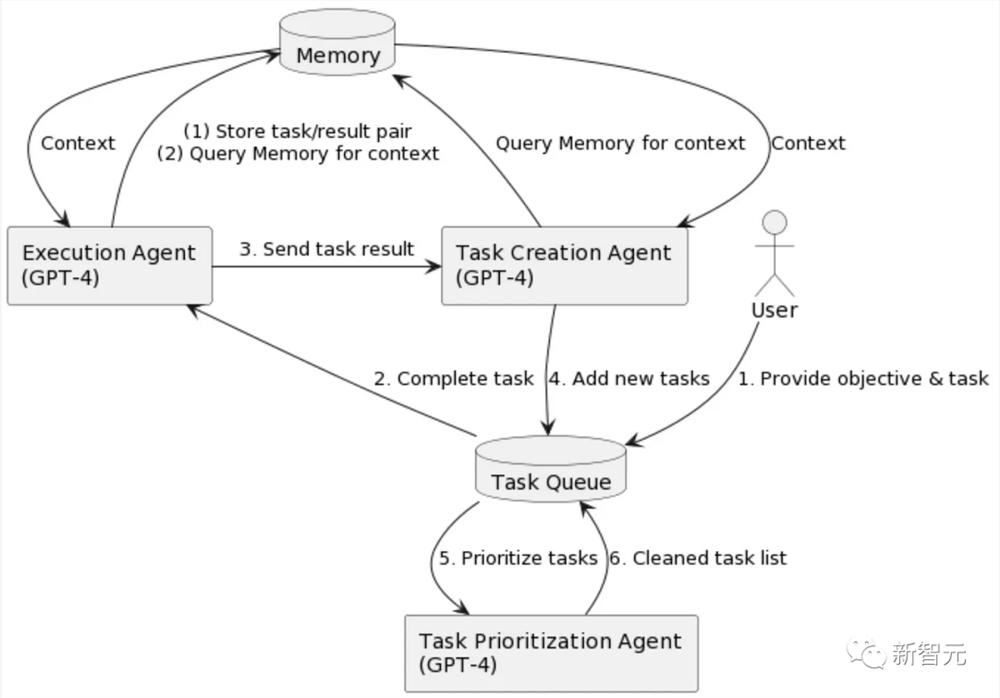
BabyAGI是另一个最近推出的自主AI智能体,上面是它的流程图。它有三个基于LLM的组件:
任务创建智能体:提出了一个任务列表(类似于Planer);
优先级智能体:尝试通过LLM提示(类似于Selector)确定任务列表的优先级;
执行智能体(类似于Controller):执行具有最高优先级的任务。
AutoGPT和BabyAGI都使用向量数据库来存储中间结果并从经验中学习。
局限性和挑战
不过,大语言模型(LLM)在终身学习过程中仍然存在一些问题。
首先就是模型有时会出现幻觉、捏造事实或安排不存在的任务,而且在一些研究中,将GPT-4换成GPT-3.5会严重影响性能。
其次,当大语言模型扮演规划者(Planner)或评论者(Critic)时,它们的表现可能不够准确。——比如评论者可能提供错误的反馈,而规划者可能重复同样的计划。
另外,大语言模型的上下文长度限制了它们的短期记忆能力,这影响了模型保存详细的过往经验、具体指令和控制原语API。
最后,多数研究假设大语言模型已经掌握了进行终身学习所需的全部信息,但这种假设并不总是成立。
所以研究人员为智能体提供互联网访问(如AutoGPT),或提供文本材料作为输入上下文(如本文介绍),这些方法对之后的研究提供了帮助。
- 0000
- 0000
 0000
0000- 0000
- 0000