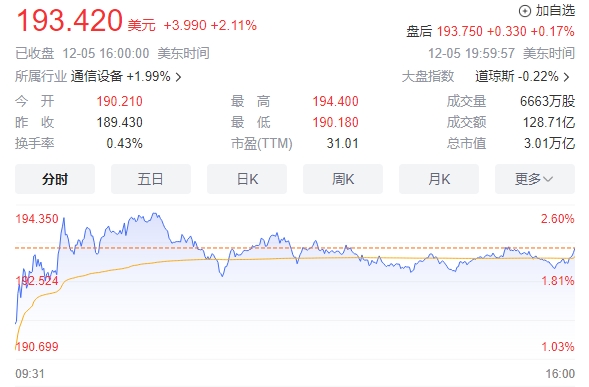
研究人员提出 “Hyena”:可能颠覆现有的大模型注意力机制系统
一项由斯坦福大学和 Mila 研究人员提出的新架构 “Hyena” 正在自然语言处理(NLP)社区中引起轰动,并被认为可能颠覆现有的注意力机制系统。
该架构通过长卷积和逐元素乘法门控制实现了与注意力机制相媲美的性能,同时降低了计算成本。通过在自动回归语言建模和图像分类方面进行实验,研究人员发现 Hyena 能够在性能上与注意力模型相媲美,并且具有更低的计算复杂度和参数数量。这项研究对于大规模语言模型的开发具有重要意义,并可能成为一种高效的替代方案。
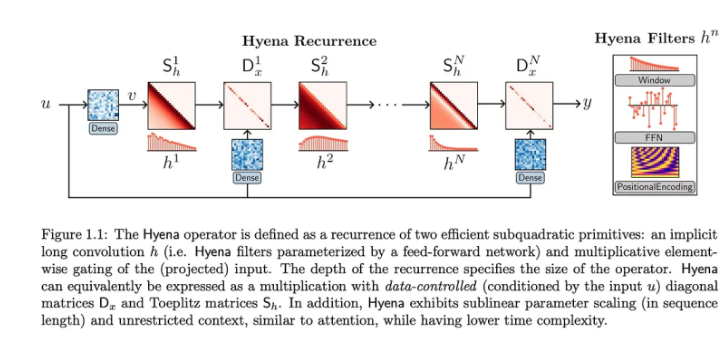
研究人员在论文中提到:
二次算子可以大规模匹配注意力模型的质量,而无需在参数和优化成本方面付出高昂的代价。基于有针对性的推理任务,作者提炼出了对其性能有贡献的三个最重要的属性。
数据控制
次线性参数缩放
不受上下文限制。
考虑到这些要点,他们随后引入了鬣狗等级制度。这个新算子结合了长卷积和逐元素乘法门控,以匹配大规模注意力的质量,同时降低计算成本。
进行的实验揭示了令人震惊的结果。
语言建模。
Hyena 的扩展性在自回归语言模型上进行了测试,在基准数据集 WikiText103和 The Pile 上对困惑度进行评估时,发现 Hyena 是第一个与 GPT 质量相匹配的无注意力卷积架构,总 FLOPS 降低了20%。
WikiText103上的困惑(相同的分词器)。* 是来自(Dao 等人,2022c)的结果。更深更薄的模型(Hyena-slim)可实现更低的困惑度
训练模型的堆上的困惑,直到令牌总数达到50亿(每个令牌总数不同)。所有模型都使用相同的分词器 (GPT2)。FLOP 计数针对150亿代币运行
大规模图像分类
该论文展示了 Hyena 作为图像分类通用深度学习算子的潜力。在图像翻译方面,他们用 Hyena 算子替换了 Vision Transformer(ViT)中的注意力层,并将性能与 ViT 进行匹配。
在 CIFAR-2D 上,我们在标准卷积架构中测试了2D 版本的 Hyena 长卷积滤波器,该滤波器在2D 长卷积模型 S4ND(Nguyen 等人,2022)的精度上进行了改进,加速率提高了8%,参数减少了25% 。
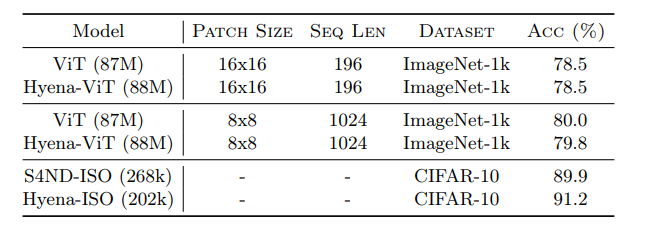
在十亿级参数规模上取得的有希望的结果表明,注意力可能不是我们所需要的全部,并且像鬣狗这样的更简单的二次设计,通过简单的指导原则和对机械可解释性基准的评估,构成了高效大型模型的基础。
- 0000
- 0000
 0003
0003- 0000


 0001
0001