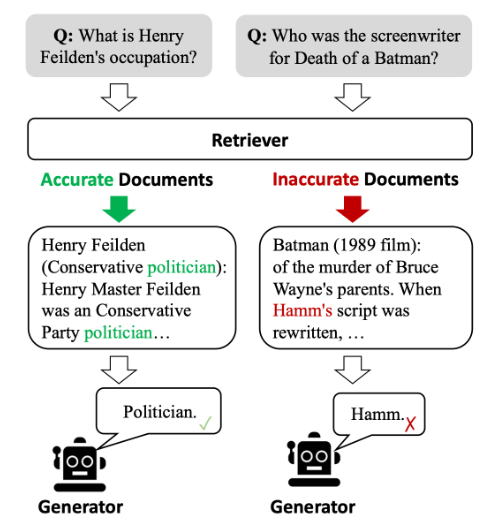
谷歌发布Cloud TPU v5p和AI超级计算机:人工智能处理能力飞跃
**划重点:**
1. 💡 **Cloud TPU v5p亮点:** Google 推出的最强大的张量处理单元,性能设计突出,每个 pod搭载8,960个芯片,芯片之间的互联速度达到4,800Gbps,相较于前代 v4,性能翻倍,高带宽内存(HBM)更是增加三倍。
2. 💡 **AI Hypercomputer革新:** AI 超级计算机采用优化的性能硬件、开源软件、主要机器学习框架以及可调整的消耗模型,通过协同系统设计提高在培训、微调和服务领域的人工智能效率和生产力。
3. 💡 **灵活消耗模型:** AI Hypercomputer引入创新的Dynamic Workload Scheduler和传统的消耗模型,支持Cloud TPU和Nvidia GPU,优化用户支出。
谷歌在推出其张量处理单元Cloud TPU v5p和具有突破性的超级计算机架构AI Hypercomputer时掀起了轩然大波。这些创新的发布,再加上资源管理工具Dynamic Workload Scheduler,标志着在处理组织的人工智能任务方面迈出了重要的一步。

Cloud TPU v5p,继去年11月发布的v5e之后,成为谷歌最强大的TPU。与其前身不同,v5p以性能为驱动设计,承诺在处理能力方面取得显著的改进。每个pod配备8,960个芯片,芯片之间的互联速度达到4,800Gbps,这一版本在浮点运算每秒(FLOPS)方面提供了两倍的性能,并在高带宽内存(HBM)方面比前代TPU v4增加了三倍。

在性能方面的聚焦取得了显著的成果,Cloud TPU v5p在训练大型LLM模型时的速度比TPU v4提高了惊人的2.8倍。此外,利用第二代SparseCores,v5p展示了在嵌入式密集模型方面的训练速度,比其前身快了1.9倍。
与此同时,AI Hypercomputer**作为超级计算机架构的一场革命性变革。它融合了优化的性能硬件、开源软件、主要机器学习框架和可调整的消耗模型。AI Hypercomputer放弃了强化离散组件的传统方法,而是利用协同系统设计,提高了在培训、微调和服务领域的人工智能效率和生产力。
这一先进的架构基于超大规模数据中心基础设施的精心优化的计算、存储和网络设计。此外,它通过开源软件为开发人员提供了对相关硬件的访问,支持诸如JAX、TensorFlow和PyTorch等机器学习框架。这种集成扩展到Multislice Training和Multihost Inferencing等软件,同时深度集成了Google Kubernetes Engine(GKE)和Google Compute Engine。
AI Hypercomputer的真正独特之处在于其灵活的消耗模型,专门满足人工智能任务的需求。它引入了创新的Dynamic Workload Scheduler和像承诺使用折扣(CUD)、按需和Spot等传统消耗模型的平台。这个资源管理和任务调度平台支持Cloud TPU和Nvidia GPU,简化了调度所有所需加速器以优化用户支出。
在这个模型下,Flex Start选项非常适合模型微调、实验、较短的培训会话、离线推理和批处理任务。它提供了一种经济有效的方式,在执行前请求GPU和TPU容量。相反,Calendar模式允许预订特定的启动时间,满足对培训和实验任务需要精确启动时间和持续时间的要求,可提前8周购买,持续7或14天。
谷歌发布Cloud TPU v5p、AI Hypercomputer和Dynamic Workload Scheduler代表了人工智能处理能力的一大飞跃,引领着性能增强、优化架构和灵活的消耗模型的新时代。这些创新有望重新定义人工智能计算的格局,并为各行各业的突破性进展铺平道路。
官方博客网址:https://cloud.google.com/blog/products/ai-machine-learning/introducing-cloud-tpu-v5p-and-ai-hypercomputer
- 0001
- 0000
- 0000
- 0000
- 0000