通过纠正检索增强生成 (CRAG) 提高大语言模型的准确性
**划重点:**
1. 🧠 语言模型困扰准确性问题,CRAG方法通过轻量级检索评估器解决检索失败导致的生成问题。
2. 🔄 CRAG采用动态文档检索,引入分解-重组算法,确保只有最相关、准确的知识融入生成过程。
3. 📈 CRAG在短文回答和长篇传记生成等任务上 consistently 胜过标准检索增强生成方法,为语言模型精度迈出重要一步。
在自然语言处理中,追求语言模型精度的过程中,创新的方法不断涌现,以缓解这些模型可能存在的固有不准确性。其中一个显著的挑战是模型倾向于产生“幻觉”或事实错误,因为它们依赖内部知识库。这一问题在大语言模型(LLMs)中尤为明显,尽管在生成与现实事实一致的内容时,它们通常需要改进。
为了解决这个问题,引入了检索增强生成(RAG)的概念,通过在生成过程中整合外部相关知识来增强LLMs。然而,RAG的成功在很大程度上取决于检索到的文档的准确性和相关性。关键问题出现了:当检索过程失败时,引入不准确或无关信息会对生成过程产生什么影响?
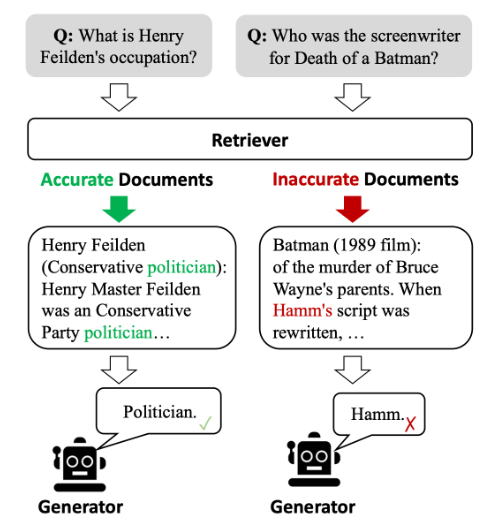
这时就出现了纠正检索增强生成(CRAG)方法,这是研究人员为了加强生成过程抵御不准确检索的陷阱而设计的一种创新方法。在核心层面,CRAG引入了一个轻量级检索评估器,这是一个用于评估给定查询的检索文档质量的机制。这个评估器是至关重要的,它提供了对检索文档相关性和可靠性的细致理解。基于其评估,评估器可以触发不同的知识检索操作,增强生成内容的强大性和准确性。
CRAG的方法在文档检索方面独具特色。当评估发现检索到的文档不佳时,CRAG不仅仅停留在承认这一事实。相反,它采用一种复杂的分解-重组算法,有选择地关注检索信息的核心,同时丢弃无用的部分。这确保只有最相关、准确的知识被融入生成过程。此外,CRAG充分利用网络的广泛性,通过大规模搜索来扩充其知识库,超越了静态、有限的语料库。这不仅拓宽了检索信息的范围,还提升了生成内容的质量。
CRAG的有效性在多个数据集上得到了严格测试,涵盖了短文和长文生成任务。结果是明显的,CRAG始终优于标准RAG方法,展示了其在导航准确知识检索和集成复杂性方面的能力。尤其在短文回答和长篇传记生成任务中,其对信息的精准度和深度尤为突出。
这些进展标志着追求更可靠、准确语言模型的一大步。CRAG通过优化检索过程,确保外部知识的高相关性和可靠性,标志着一个重要的里程碑。这种方法解决了LLMs中“幻觉”问题,为整合表面知识到生成过程中设定了新的标准。
CRAG重新定义了语言模型精度的景观。其发展突显了向生成流畅文本、并以前所未有的事实完整性进行生成的模型的关键转变。这一进展承诺提升LLMs在从自动化内容创建到复杂对话代理等应用中的效用,为语言模型可靠地反映人类知识的丰富性和准确性铺平了道路。
- 0000
 0000
0000- 0002
- 0001
- 0000


