阿里巴巴推大规模音频语言模型Qwen-Audio
要点:
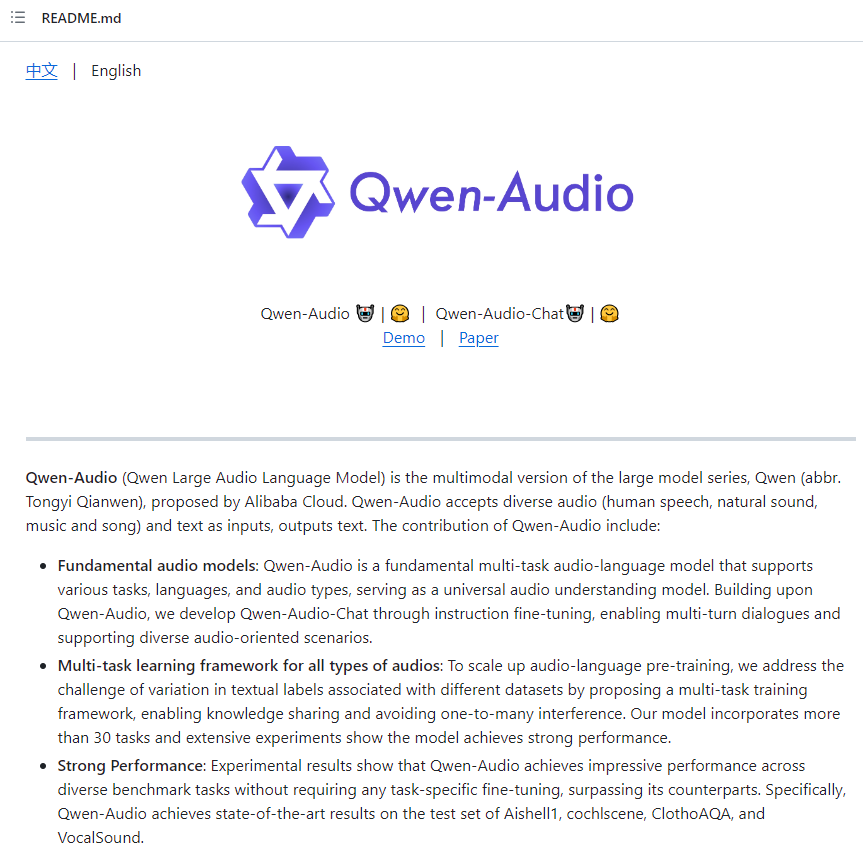
阿里巴巴研究团队推出了Qwen-Audio系列,这是一组具有通用音频理解能力的大规模音频语言模型。
Qwen-Audio通过采用层次标签的多任务框架,成功应对了多样化任务的挑战,并在基准任务上取得了令人印象深刻的性能,无需特定任务的微调。
Qwen-Audio-Chat是在Qwen-Audio基础上构建的,支持多轮对话和各种音频中心场景,展示了其通用音频理解能力。
阿里巴巴研究团队最近推出的Qwen-Audio系列为大规模音频语言模型领域带来了重大突破。该系列通过采用层次标签的多任务框架,成功解决了有限的预训练音频模型面临的多样化任务的挑战。
相比之前专注于语音的工作,Qwen-Audio不仅包含人类语音,还涵盖了自然声音、音乐和歌曲,实现了在具有不同粒度的数据集上的协同训练。该模型在语音感知和识别任务方面表现出色,而无需进行特定任务的修改。
Qwen-Audio的多任务框架有助于减轻干扰,实现了在基准任务上的显著性能。Qwen-Audio-Chat作为扩展,不仅支持多轮对话,还适用于各种音频中心场景,展示了在大规模音频语言模型中全面的音频交互能力。
项目地址:https://github.com/qwenlm/qwen-audio
尽管大规模语言模型在通用人工智能方面表现出色,但它们缺乏对音频的理解。Qwen-Audio系列的推出填补了这一空白,将预训练扩展到30个任务和多种音频类型。
Qwen-Audio系列的训练方法分为两种:Qwen-Audio采用多任务预训练方法,优化音频编码器同时冻结语言模型权重;相反,Qwen-Audio-Chat采用监督微调,优化语言模型同时固定音频编码器权重。这一训练过程包括多任务预训练和监督微调,使Qwen-Audio-Chat具有多样的人际交互能力,支持从音频和文本输入中的多语言、多轮对话。
Qwen-Audio在各种基准任务上表现出色,明显优于没有特定任务微调的对照组。它在AAC、SWRT ASC、SER、AQA、VSC和MNA等任务上始终超越基线,同时在CochlScene、ClothoAQA和VocalSound上取得了最先进的结果,展示了其在挑战性音频任务中的有效性和能力。
Qwen-Audio系列未来的探索方向包括扩展不同音频类型、语言和特定任务的能力。通过优化多任务框架或探索替代的知识共享方法,可以解决协同训练中的干扰问题。
研究人员还计划通过不断更新基于新基准、数据集和用户反馈的内容,提高通用音频理解水平。Qwen-Audio-Chat将进一步优化以符合人类意图,支持多语言互动,并实现动态多轮对话。
- 0001
- 0002
- 0001

 0000
0000- 0000