微软研究推新型视觉基础模型Florence-2:基于统一提示,适用各种计算机视觉和视觉语言任务
**划重点:**
1. 🌐 人工智能系统向使用预训练、可调整表示的方向发展,Florence-2是一款灵活的视觉基础模型,通过统一提示式表示,成功解决了空间层次和语义细粒度的挑战。
2. 📊 通过多任务学习和大规模数据集,Florence-2实现了灵活的通用表示,取得了在多个视觉任务上的零样本表现和超越专业模型的成果。
3. 🛠️ 采用序列到序列结构,Florence-2不需要特定任务的架构调整,支持目标识别、字幕生成等多种视觉任务,是一种具有统一基础的灵活模型。
近来,人工智能领域的趋势是采用预训练、可调整表示的方法,为各种应用提供任务不可知的优势。与此趋势相呼应,微软研究推出了Florence-2,这是一款灵活的视觉基础模型,通过统一提示式表示成功应对了计算机视觉中的挑战。
在自然语言处理(NLP)中,我们看到了这种趋势的明显体现,先进的模型展示了在多个领域和任务上灵活性的同时,能够通过简单的指令进行深入的知识覆盖。NLP的流行鼓励在计算机视觉中采用类似的策略,但计算机视觉面临更多挑战,因为它需要处理复杂的视觉数据,如特征、遮挡轮廓和物体位置。为了实现通用表示,模型必须熟练处理二维排列的各种具有挑战性的任务。
Florence-2通过统一的预训练和网络设计,引领了在计算机视觉中整合空间、时间和多模态特征的潮流。该模型通过任务特定的微调和使用嘈杂的文本-图像对进行预训练,在转移学习方面取得了显著的进展。然而,由于对大型任务特定数据集和适配器的依赖,存在解决空间层次和语义细粒度两个主要问题的差距。研究人员通过使用富有视觉标注的多任务学习,提供了一个通用的骨干,实现了基于提示的统一表示,成功解决了数据不完整和缺乏统一架构的问题。
在实现多任务学习时,大规模、高质量的标注数据是必不可少的。为了克服人工标注的瓶颈,研究团队创建了一个名为\fld 的广泛的视觉数据集,其中包含对126M张照片的5.4B注释。通过使用专门的模型共同和自主地注释照片,该数据引擎的第一个模块跳出了传统的单一手动注释策略。与众多模型合作,共同创建共识,形成更公正和可信的图片解释。第二个模块使用学习到的基本模型,反复改进和过滤这些自动注释。
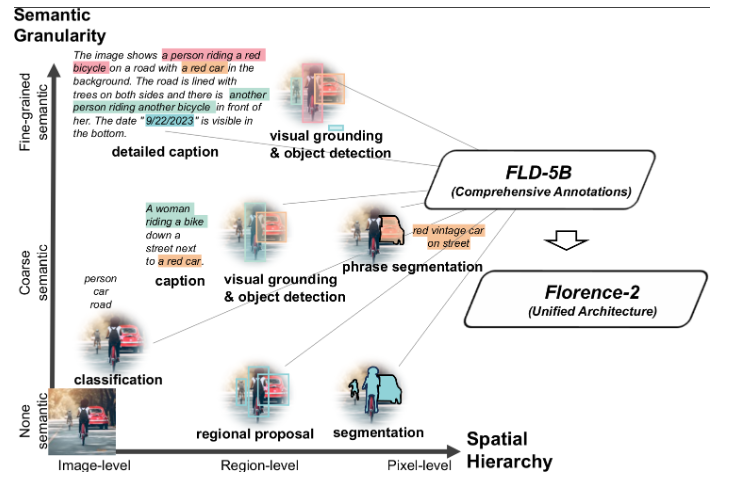
Florence-2采用序列到序列(seq2seq)结构,通过整合图像编码器和多模态编码器-解码器,利用这个大型数据集。这种架构支持多种视觉任务,无需任务特定的架构调整,符合NLP社区创建具有统一基础的灵活模型的目标。数据集中的每个注释都被一致地标准化为文本输出,从而实现了使用相同损失函数的单一多任务学习策略的一致优化。结果是一个灵活的视觉基础模型,可以处理一系列功能,包括目标识别、字幕生成和定位,都在单一模型的统一参数控制下。文本提示被用来激活任务,与大型语言模型(LLMs)采用的方法一致。
该方法实现了通用表示,并在许多视觉任务中具有广泛的应用。关键发现包括:
- 该模型是一种灵活的视觉基础模型,在诸如RefCOCO的任务中实现了新的零样本性能,包括引用表达理解、Flick30k上的视觉定位和COCO上的字幕生成。
- 尽管体积较小,但在使用公开可用的人工标注数据进行微调后,与更专业的模型竞争。值得注意的是,改进后的模型在RefCOCO上创下了新的基准最先进得分。
- 预训练的骨干在下游任务中超越了监督和自监督模型,在COCO对象检测和实例分割以及ADE20K语义分割上取得了显著的增长。使用Mask-RCNN、DINO和UperNet框架的模型在COCO和ADE20K数据集上分别取得了6.9、5.5和5.9个点的显著增加,同时将在ImageNet上预训练模型的训练效率提高了四倍。
这项研究的全部功劳归功于该项目的研究人员。如果您喜欢他们的工作,请查看论文,并加入他们的社交媒体群体,获取最新的人工智能研究新闻和有趣的项目。
论文网址:https://arxiv.org/abs/2311.06242
- 0000
- 0000
- 0000
- 0002
- 0000