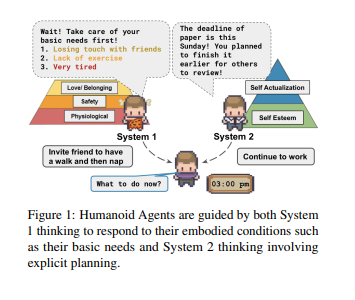
中国研究人员推ControlLLM框架:提升大语言模型处理多模态任务能力
🔍划重点:
研究人员提出了ControlLLM,旨在增强LLMs的效果
LLMs通过外部工具获取信息,减少幻觉,并实现多模态交互
努力培养具有固有多模态能力的LLMs,扩大其适用范围
中国的研究人员近期提出了一项名为ControlLLM的创新框架,旨在增强大型语言模型(LLMs)在处理复杂的现实任务时的表现。尽管LLMs在处理自主代理的规划、推理和决策方面已经取得了显著进展,但在某些情况下,由于用户提示不清晰、工具选择错误以及参数设置和调度不足,它们可能需要辅助工具。
这项研究还探讨了通过外部工具增强LLMs的方法,以获取当前信息、减少幻觉并实现多模态交互。工具增强型LLMs借助LLMs的零-shot或少-shot上下文学习,可以处理任务分解、工具选择和参数完成,而无需显式微调。然而,幻觉和有效分解等挑战仍然存在,因此研究人员正在致力于培养具有固有多模态能力的LLMs,以扩大其适用范围,以适应更复杂的现实场景。
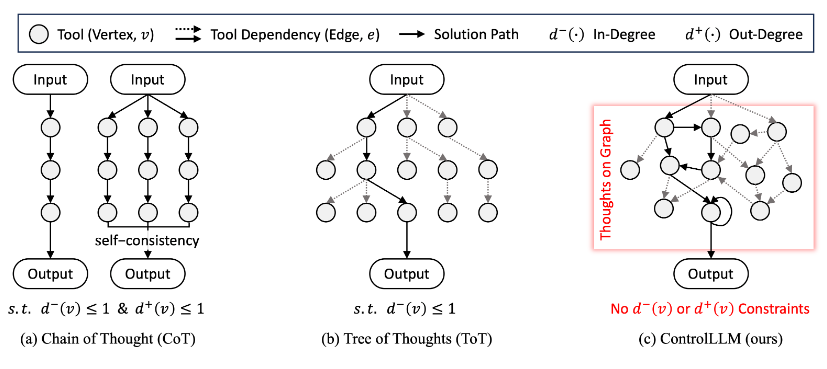
LLMs已经在自然语言理解方面展示出了卓越的能力,现在它们正在将这些能力扩展到包括图像、视频、音频等多模态交互中。通过整合工具,LLMs可以处理更复杂的任务,但需要解决任务分解、工具选择、参数分配以及高效执行调度等挑战。以往的方法,如“Chain-of-Thought”、 “Tree-of-Thought” 和“self-consistency”,通过将复杂任务分解成较小的子任务来解决这些挑战。
ControlLLM框架由三个关键组成部分构成:任务分解器、Thoughts-on-Graph方法和多功能执行引擎。任务分解器将复杂的用户提示分解成具有明确定义的子任务,具有不同的输入和输出。Thoughts-on-Graph方法在预定义的工具图上探索最佳解决方案路径,指定工具之间的参数和依赖关系。执行引擎解释这条路径,并在各种计算设备上高效执行操作。
与现有方法相比,ControlLLM框架在准确性、效率和多功能性方面表现出色,尤其在涵盖图像、音频和视频处理等各种任务中表现出色。它在解决具有挑战性的任务时拥有惊人的98%的成功率,超过了最佳基准性能的59%。ControlLLM还显著提高了工具的使用,灵活地推断和分配工具参数。无论是在简单还是复杂的情景中,ControlLLM都能够无缝整合各种信息类型,生成基于执行结果的全面而有意义的回应。
ControlLLM框架赋予LLMs能力,使它们能够利用多模态工具处理复杂的现实任务,提供更高的准确性、效率和适应性。
其组成部分,包括任务分解器、Thoughts-on-Graph方法和多功能执行引擎,共同为工具的利用做出了实质性的改进。ControlLLM通过精湛的工具参数推断和分配以及在解决方案评估中取得高成功率来持续展示其能力。
通过广泛的案例研究,它证实了其任务规划能力,提供了丰富的解决方案,以增强用户体验。ControlLLM整合了各种信息源,以生成基于执行结果的全面而有意义的回应。
项目网址:https://github.com/OpenGVLab/ControlLLM

 0001
0001- 0000

 0001
0001- 0000
- 0003