Meta发布Llama 2-Long模型 处理长文本计算量需求减少40%
要点:
1. Meta发布Llama2-Long模型,能在处理长文本时不增加计算需求,仍保持卓越性能。
2. 模型的性能提升得益于持续预训练、位置编码改进和数据混合,而非依赖更多长文本数据。
3. 在短和长任务上,Llama2-Long都表现出色,超越其他长上下文模型,具有潜力革新自然语言处理领域。
Meta最新发布的Llama2-Long模型引领着处理长文本的革命。这个模型不仅处理长文本输入,而且在不显著增加计算需求的情况下,保持了卓越性能。这一成就的背后是一系列创新策略的结果,而不仅仅依赖于更多的长文本数据。
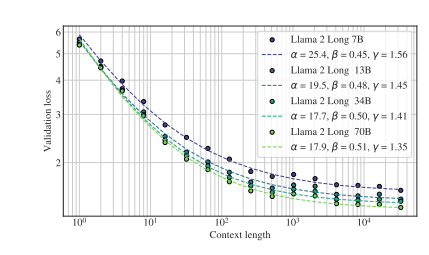
Llama2-Long采用了持续预训练策略,允许模型逐渐适应更长的输入序列,而不是从头开始进行长序列预训练。这一策略在保持性能的同时,最多可减少40%的计算开销。通过改进位置编码,研究人员成功提高了模型的上下文长度,使其更好地捕获远处信息。
论文地址:https://arxiv.org/pdf/2309.16039.pdf
数据混合也发挥了关键作用,研究人员通过调整预训练数据的比例以及添加新的长文本数据,进一步提升了模型的长上下文能力。实验结果表明,数据质量在长上下文任务中比文本长度更为关键。
模型的指令微调方法也经过优化,通过利用大型多样化短提示数据集,有效将知识传递到长上下文场景。这种方法的简单性和效果出奇的好,特别是在长语境基准测试中。
Llama2-Long不仅在长任务中表现出色,还在短任务中有卓越性能。相对于其他长上下文模型,它在编码、数学和知识密集型任务上表现出明显的改进,甚至超越了GPT-3.5。这一成就被归因于额外的计算资源以及新引入的长数据中学到的知识。
Llama2-Long模型的发布代表了自然语言处理领域的一次里程碑,为处理长文本提供了强大的解决方案。它不仅改进了处理长文本的性能,还通过创新策略为该领域注入了新的活力。
- 0000
- 0000
- 0000
- 0000
- 0000