亚马逊机器学习团队推出 Mistral 7B 基础模型 支持8000个token上下文长度
文章概要:
- Mistral7B 是Mistral AI开发的英文文本和代码生成基础模型,参数规模70亿。
- SageMaker JumpStart提供一键部署Mistral7B进行推理,可快速自定义。
- Mistral7B具有8000个token的上下文长度,表现低延迟和高吞吐量。
亚马逊机器学习团队近日宣布,Mistral AI开发的Mistral7B基础模型现已在亚马逊SageMaker JumpStart上提供,用户可以通过该平台一键部署模型进行推理。
Mistral 7B是Mistral AI开发的英文文本和代码生成基础模型,拥有70亿个参数,支持文本摘要、分类、文本补全和代码补全等多种用例。为展示模型的易于自定义性,Mistral AI还发布了Mistral7B Instruct对话模型,使用各种公开对话数据集进行了优化。
Mistral 7B采用transformer架构,通过grouped-query attention和sliding-window attention实现更快的推理速度和处理更长序列的能力。该模型具有8000个token的上下文长度,表现出低延迟和高吞吐量,与更大模型相比性能出色,参数量只有70亿,显存需求较低。Mistral7B基于宽松的Apache2.0许可发布,可无限制使用。
亚马逊SageMaker JumpStart是一个机器学习中心,提供各种预训练好的算法和模型,用户可以快速上手机器学习。现在,用户可以通过几次点击在SageMaker Studio中发现并部署Mistral 7B,或者通过SageMaker Python SDK以编程方式部署,利用SageMaker的各项功能如管道、调试器对模型性能及MLOps进行控制。模型部署在AWS安全环境下、用户的VPC控制之中,有助于确保数据安全。
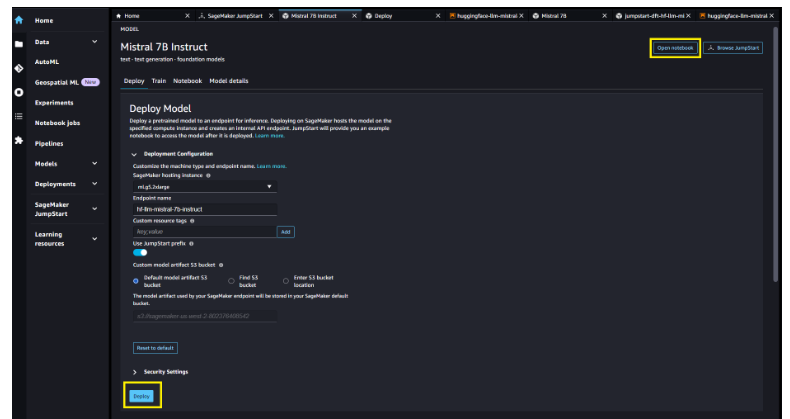
SageMaker JumpStart为机器学习从业者提供了越来越多性能最好的基础模型。它们帮助降低训练和基础设施成本,并支持自定义以适应特定用例。
总结Mistral7B的主要特色功能点大致如下:
1. 参数规模达70亿,支持多种自然语言处理任务。Mistral 7B是一个具有70亿参数的基础模型,支持文本摘要、分类、补全等多种英文NLP任务。
2. 推理速度快,具有8000个token的上下文长度。Mistral 7B使用了transformer架构,可以实现低延迟和高吞吐量推理,支持长达8000个token的上下文长度。
3. 易于部署使用,提供一键体验。用户可以通过Amazon SageMaker JumpStart一键部署Mistral7B,并便捷获得其推理服务,无需训练即可使用。
4. 模型开源,基于Apache2.0协议。Mistral7B的模型权重已在宽松的Apache2.0许可下开源,用户可以无限制地使用。
SageMaker JumpStart体验网址:https://aws.amazon.com/cn/sagemaker/jumpstart/
- 0000
- 0000
- 0000
- 0001

 0000
0000