CPU、GPU、NPU,究竟谁才是“AI PC”的主角?
众所周知,如今“AI PC”可以说是消费电子行业最为热门的话题之一。对于一些不太了解技术细节,但却对这个概念心向往之的消费者而言,他们相信“AI PC”可以更智能地帮助自己完成一些不熟练的操作,或是减轻日常工作的负担。
但对于像我们这样,对“AI PC”既抱有极高期待、但同时又相对比较了解的用户来说。很多时候思考的其实是AI PC早就出现了,可为什么到现在才被真正推行起来?
AI PC到底有多早?其实7年前就已经出现了
且不论那些专业的超级电脑,对于个人消费者来说,“AI PC”到底是什么时候开始出现的?
从CPU的角度来说,答案是2019年。因为在这一年的第10代酷睿-X处理器(比如i9-10980XE)上,Intel就首次引入了专门用于加速16位运算的“DL BOOST”指令集。并在之后将其普及到了定位更低的10代酷睿移动版、11代酷睿全系产品上,让它们能在处理深度学习、AI应用时,理论上效率比以前高了整整一倍。
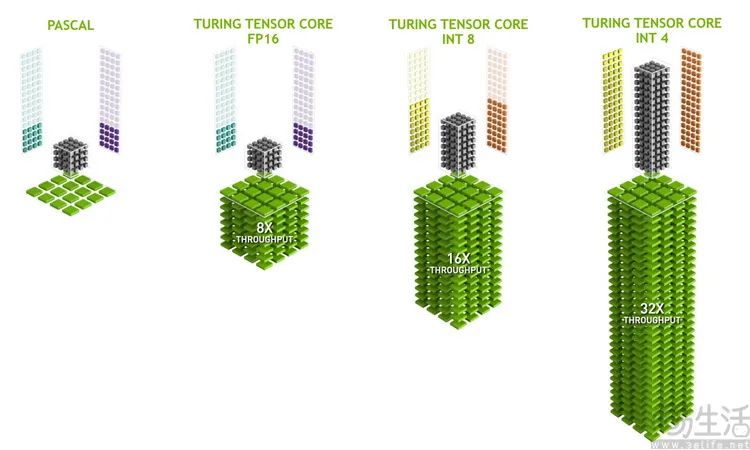
而从显卡的角度来说,更是早在2017年消费级市场就迎来了首款内置Tensor Core的“AI显卡”——NVIDIA TITAN V。根据公开的技术资料可知,它集成的640颗初代Tensor Core单元,在FP16模式下可提供119TFlops的AI加速算力。
有意思的是,如果对数值敏感,你可能就会意识到,这款7年前的老显卡,AI算力甚至还比最新的很多“AI PC”所宣称的算力水平,还要高了10倍以上。
NPU的AI性能不算高,可为什么还要用它们呢
那么为什么会出现这样的情况呢?根据我们的实际使用经验来说,其实主要源自三个方面。
首先,是能效问题。的确、现代的CPU和GPU其实都具备一定得AI加速能力,特别是GPU的AI算力更是惊人。但CPU的AI计算效率确实算不上高,而GPU拿来算AI时的高功耗,对于像笔记本电脑这类设备来说也是无法忽视的,所以处理AI比CPU更快、比GPU更省电的NPU,自然也就有了省电方面的价值。

有的朋友可能会说,如果用算力更高的设备在更短的时间里算完,是不是也能省电呢?确实是这个道理,可问题在于对当下的“AI PC”来说,AI任务不一定都是像视频超分处理、生成式图像这样的高算力需求,也有可能像是AI语音助手、AI性能调度之类需要常驻后台,以最低延迟随时给出反馈的用例。
很显然,这种时候笔记本电脑就不可能允许CPU或GPU一直处于高功率状态,去满足这种“随时维持的AI应用”需求了。
AMD基于GPU的端侧AI大模型聊天功能,就非常吃显卡性能
而且从实际的使用场景来看,目前大量的常用PC程序、常见游戏都并非是基于“AI”,这意味着如果一直用CPU或GPU去分担AI算力,那么它们就相当于会降低电脑的性能。很显然,除了专门做AI相关工作之外,绝大多数的用户都不会愿意看到这种情况。
“算力融合”才是未来,但要做好它并不容易
当然,就算NPU有着高能效、低功耗,可以常时启动、不影响CPU和GPU性能等好处,但想必还是会有朋友产生与我们一样的想法,为什么不能让CPU、GPU、NPU同时被用于AI运算,从而更灵活地兼顾“高性能”和“高能效”呢?

其实从理论上来说,这当然是可以实现的。比如根据相关资料显示,高通就在他们即将上市的骁龙X Elite系列里,做到了CPU、GPU、NPU都能参与AI运算,甚至可以根据代码类型、任务负载的不同实现自动分配的“异构协同”设计。
不过从它身上,我们其实也正好可以窥见其他“AI PC”硬件方案,难以实现不同处理单元协同运算的原因所在。说白了,问题就是出在了大家“各自为战”的产品构成上。
最新的NVIDIA驱动界面会提供一系列基于RTX显卡的AI加速功能
比如,在GPU领域,NVDIA的RTX全系、AMD的RX7000系列、以及Intel的ARC系列独显,内部其实都带有独立的AI计算单元。但NVIDIA并不造消费级PC CPU,所以可以看到他们完全不考虑与CPU的AI计算协同,反而是最近一直在更新基于显卡的AI视频超分、AI色彩强化、AI音频降噪,甚至是AI语音聊天等功能,大有主张“AI PC只要有显卡算力就够了”的意思。
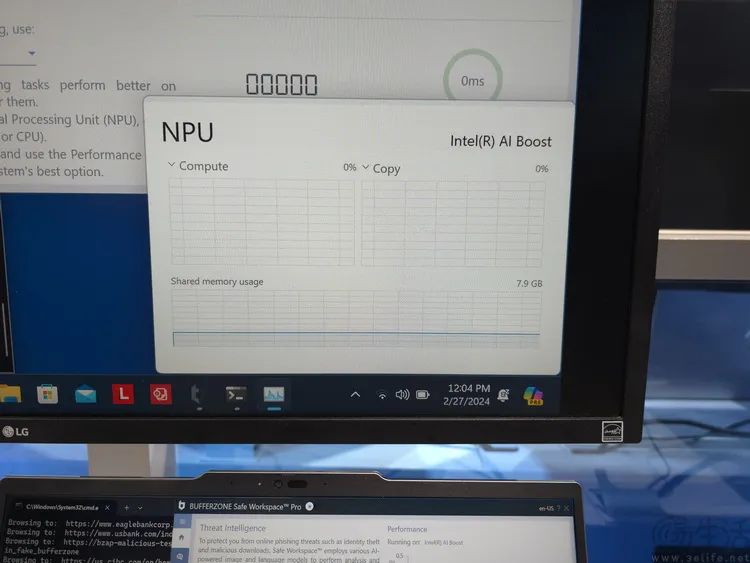
相比之下,I、A两家则更尴尬一些。比如Intel的ARC独显虽然内含XMX矩阵计算单元,但其集成到CPU里的这一代ARC核显却取消了这个设计,结果就是导致目前的MTL架构CPU实际上只有内置NPU这么一个独立的AI计算单元。而且即便搭配ARC独显使用,也无法实现核显与独显的AI算力“叠加”。
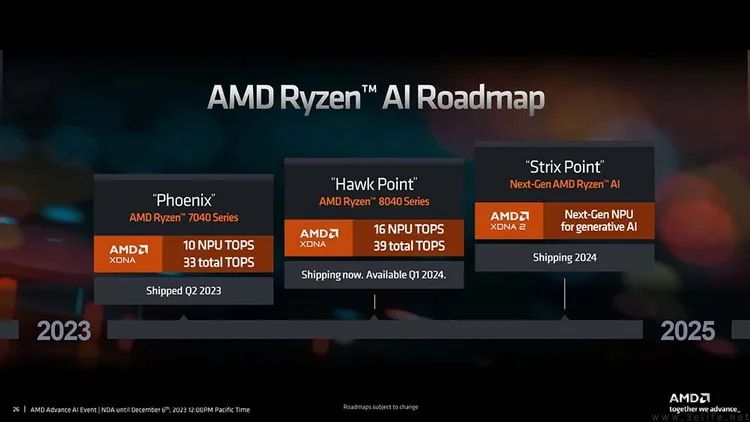
AMD的CPU和GPU现在都有AI单元,但架构和软件都不通用
与此同时,AMD在他们的CPU里,使用的是来自旗下企业级计算卡的XDNA成熟架构来作为NPU单元,所以理论上有着软件更容易适配的优势。但不知为何,AMD在RDNA3独显架构里却似乎使用了另外的AI单元设计,以至于他们到目前都还没能搞定基于AI代码的游戏画面超分功能。而且在此前演示的很多显卡AI用例里,用到的都还只是GPU本身的浮点算力,因此这也意味着它(相比于只用显卡内置AI单元的处理方式)会有着更高的功耗,而且更没法做到“边打游戏边算AI”了。
芯片厂商不团结,下游品牌就只能想方设法“自救”
说了这么多,那么这些问题是否有办法解决呢?其实还是有的。比如对于Intel和AMD来说,他们当然都有希望在未来的产品线上通过架构修正,来解决这种“算力不统一”的问题。而对于NVIDIA来说,虽然他们没有消费级x86CPU产品线,但显然还不能排除NVIDIA未来通过ARM CPU入局Windows on ARM生态的可能。
当然,以上所说的这些,多少都相当于是将问题扔给了未来的架构、扔给了下一代的硬件平台。那么对于现在即将购机的消费者、甚至是那些早已用了很多年、内置AI单元的显卡或CPU的消费者来说,难道就完全没办法了吗?
也不至于。一方面,站在操作系统厂商的角度来说,微软当然不希望看到这种“AI PC标准分裂”的局面。所以他们其实有在驱动、API层面做一些工作,以统合不同硬件架构的AI算力。比较典型的例子,就是不管显卡(的浮点算力)、NPU、还是显卡内置的AI单元,在Windows系统中其实都归属Direct ML API统一调度,因此它们就可以实现一定程度上的算力“融合”。
另一方面,除了微软之外,PC厂商自己也会做出一些努力。通过自研的一些AI底层来试图统合CPU、GPU和NPU的算力,或是将GPU的加速API更深入地集成到系统底层里,从而强化其进行AI计算时的效率。当然,这些技术手段也是有意义的,只不过它们会受到PC品牌、有时甚至是具体产品线的制约,所以其效果或许很好,但不一定会对整个行业产生广泛的推动作用。
- 0001

 0000
0000- 0000
- 0000

 0000
0000