谷歌最新的人工智能大型语言模型 PaLM 2 在训练中使用的文本数据是其前身的近五倍
据 CNBC 披露,谷歌上周宣布的新型大型语言模型 PaLM 2 使用的训练数据量几乎是 2022 年前身的 5 倍,可执行更高级的编码、数学和创意写作任务。据 CNBC 获悉,谷歌的新通用大型语言模型(LLM)PaLM 2 已训练了 3.6 万亿个 token。而 token 是单词字符串,是训练 LLM 的重要组成,因为它们使模型能够预测序列中接下来出现的单词。

过去谷歌的 PaLM 使用了 7800 亿个 token,虽然谷歌一直渴望展示其人工智能技术的强大功能以及如何将其嵌入搜索、电子邮件、文字处理和电子表格中,但公布训练数据量及其它细节方面一直非常保密。微软支持的 ChatGPT 的创建者 OpenAI 也保密其最新的 LLM GPT-4 的细节。
两家公司都表示,不公开训练数据等细节是因为业务竞争的原因,但研究界呼吁进行更大的透明度。自公布 PaLM 2 以来,谷歌已表示新模型比以前的 LLM 更小,这表明谷歌的技术正在变得更加高效,同时可以完成更复杂的任务。PaLM 2 据内部文档所示,已经训练了 3400 亿个参数,是模型复杂性的指标。而初始的 PaLM 则是训练了 5400 亿个参数。至于 PaLM 2 的训练数据具体来自哪里,谷歌发言人拒绝发表评论。
据谷歌在 PaLM 2 的博客文章中表示,这种新技术称为「compute-optimal scaling」,通过这种方法,LLM 运行效率更高,性能更好,包括更快的推理、更少的服务参数以及更低的服务成本。谷歌证实 PaLM 2 已经训练了 100 种语言,并且可以执行广泛的任务,已经被用于推动 25 个功能和产品,包括谷歌的实验性聊天机器人 Bard。它提供四种大小的选择,从最小的 Gecko 到最大的 Unicorn。
众所周知,PaLM 2 比现有任何模型都更强大,在公开披露的数据中如此。Facebook 的 LLM 称为 LLaMA,是在今年 2 月宣布的,使用了 1.4 万亿个 token 训练。上一次 OpenAI 披露 ChatGPT 的训练规模是在 GPT-3 时,当时公司表示它使用了 3000 亿个 token,而现在 OpenAI 在 3 月份推出了 GPT-4,并表示该模型在许多专业测试中达到了「人类水平的表现能力」。
如今,随着新的 AI 应用快速走向主流,围绕 AI 的争议也变得越来越激烈。谷歌的高级研究科学家 El Mahdi El Mhamdi 在 2 月份因公司缺乏透明度而辞职。周二,OpenAI 首席执行官 Sam Altman 在参议院隐私和技术小组的听证会上作证,同意议员们需要一个处理 AI 的新系统。「对于这项非常新的技术,我们需要一个新的框架,」Altman 说:「像我们这样的公司肯定要对我们在世界上推出的工具负起很大的责任。」

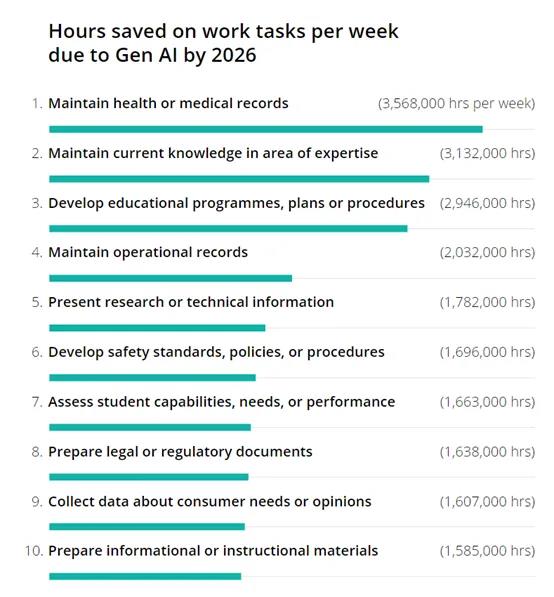
 0000
0000- 0000
- 0000

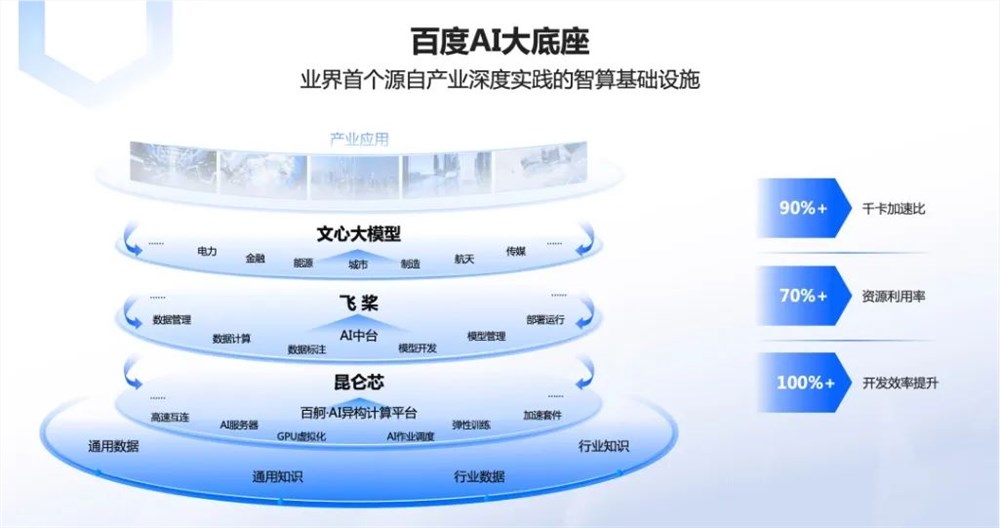
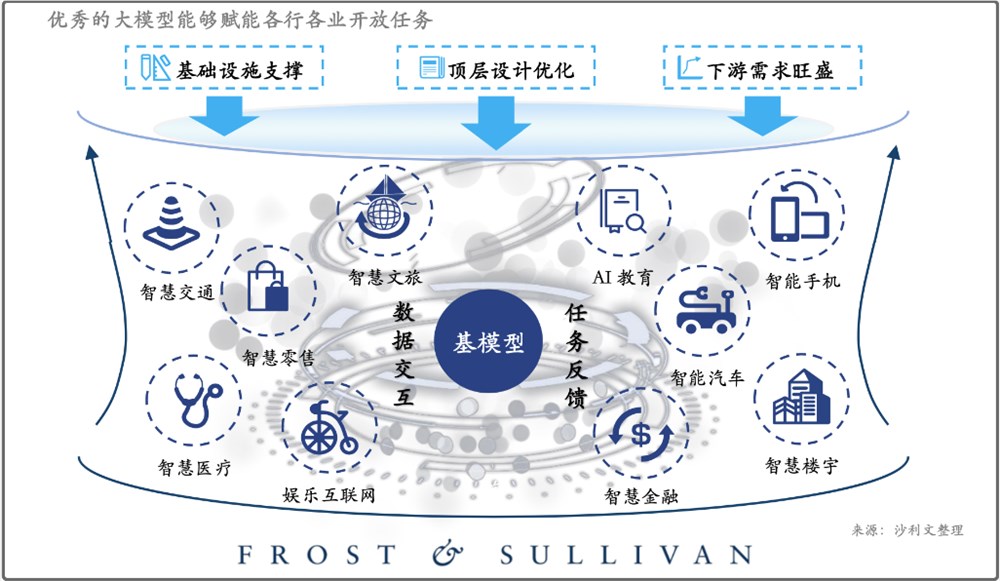 0000
0000- 0000

