几千元训完中文版LLaMA2!Colossal-LLaMA-2把大模型门槛打下来了!
站长网2023-09-25 14:07:480阅
要点:
1、通过词表扩充、数据筛选和多阶段训练策略,在15小时内用几千元成本训练出中文版LLaMA2。
2、中文版LLaMA2在多项中文任务上的表现明显提升,达到同规模模型的先进水平。
3、构建流程、代码和权重均开源,可迁移应用到其他语言和领域,实现低成本大模型训练。
以前,从头预训练大模型被认为需要高达5000万美元的投资,这让很多开发者和中小企业望而却步。而Colossal-LLaMA-2的出现降低了大模型的门槛。
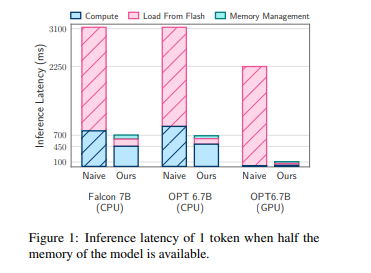
现在,仅需15小时和几千块钱的投入,就能够完成中文LLaMA2大模型的训练,数据规模达到85亿 tokens。这一方案的综合性能达到了开源社区同规模的SOTA模型水平,且完全开源,包括训练流程、代码以及权重。最重要的是,没有商业限制,可以将其应用于各种领域,实现低成本构建从头预训练的大模型。
那么,如何利用Colossal-AI系统和框架,在短时间内用很低的成本构建出表现优异的中文版本LLaMA2模型呢?
首先,通过扩充原英文词表,新增中文词汇,并利用原模型权重智能初始化,实现英文知识迁移。然后,利用严格的数据筛选流程构建高质量增量训练语料。
在训练策略上,设计了多阶段渐进式训练流程,以及均衡的数据分桶策略。最后,构建了完整的评估体系ColossalEval来全面评测模型效果。
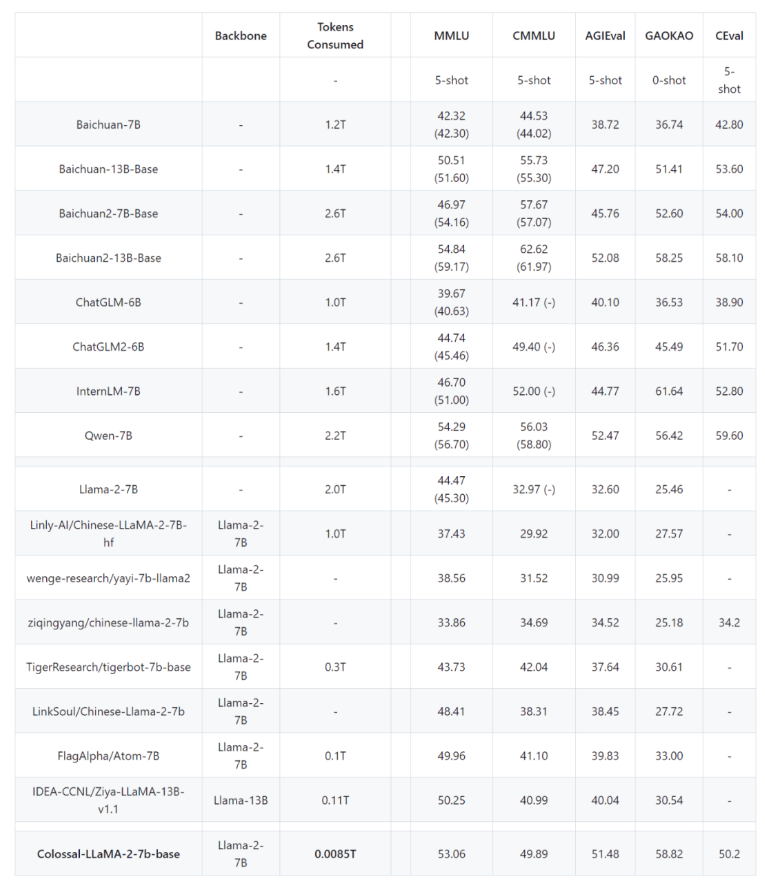
在此流程的启发下,仅用15小时和几千元成本,就训出了中文版LLaMA2。该模型在各类中文任务上的表现已达到甚至超过同规模模型的先进水平。
所有训练代码和预训练权重均开源,可以直接应用到其他语言和领域,实现大模型低成本快速构建。背后是Colossal-AI提供的高效并行和异构内存支持等系统优化。该方案业已应用到多个行业领域,构建垂类大模型并取得良好效果。
0000
评论列表
共(0)条相关推荐
- 0000
- 0000
- 0000
- 0000
- 0000