苹果最新研究:将有限内存推理速度提高25倍
站长网2023-12-21 11:04:570阅
近年来,大型语言模型(LLMs)在自然语言处理任务中表现卓越,但其对计算和内存的高需求对于内存有限的设备构成了挑战。
本文提出了一种在设备内存有限的情况下,通过将模型参数存储在闪存中,并在推断时按需将其加载到DRAM,实现了高效运行LLMs的方法。
论文地址:https://arxiv.org/pdf/2312.11514.pdf
方法包括构建与闪存内存行为协调的推断成本模型,通过减少从闪存传输的数据量和以更大、更连续的块读取数据的方式进行优化。
在这个框架内,引入了两种关键技术:窗口化策略通过重用先前激活的神经元来减少数据传输,行列捆绑技术通过适应闪存的顺序数据访问增加了从闪存读取的数据块的大小。
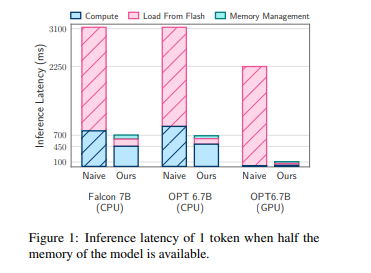
这两种方法使得能够运行比可用DRAM容量大两倍的模型,相较于朴素加载方法,CPU和GPU的推断速度分别提高了4-5倍和20-25倍。同时,结合稀疏感知、上下文自适应加载和硬件导向设计,为在内存有限的设备上进行LLMs推断打开了新的可能性。
0000
评论列表
共(0)条相关推荐
- 0000
- 0000


 0000
0000- 0000
 0000
0000


