大模型RoBERTa:一种稳健优化的 BERT 方法
要点:
1. BERT模型的出现在自然语言处理领域取得了显著进展,但研究人员继续对其配置进行实验,希望获得更好的性能。
2. RoBERTa是一种改进的BERT模型,通过多个独立的改进来提高性能,包括动态遮蔽、取消下一句预测、训练更长的句子、增加词汇量和使用更大的批次。
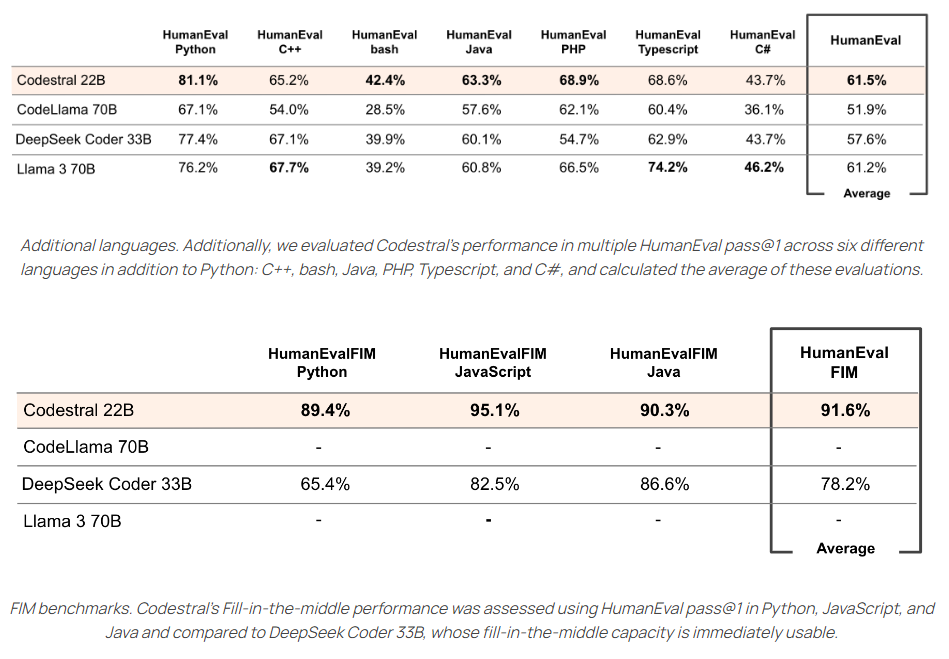
3. RoBERTa的性能在流行的基准测试中超越了BERT模型,虽然其配置更复杂,但只增加了15M个额外的参数,保持了与BERT相当的推理速度。
BERT模型在自然语言处理(NLP)领域具有举足轻重的地位。尽管BERT在多个NLP任务中取得了卓越的成绩,但研究人员仍然致力于改进其性能。为了解决这些问题,他们提出了RoBERTa模型,这是一种对BERT进行了多个改进的模型。
RoBERTa是一个改进的BERT版本,通过动态遮蔽、跳过下一句预测、增加批量大小和字节文本编码等优化技巧,取得了在各种基准任务上的卓越性能。尽管配置更复杂,但RoBERTa只增加了少量参数,同时保持了与BERT相当的推理速度。
RoBERTa模型的关键优化技巧:
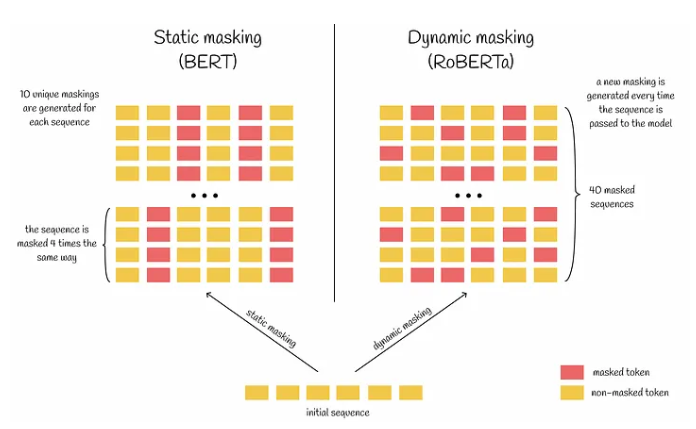
1. 动态遮蔽:RoBERTa使用动态遮蔽,每次传递序列给模型时生成独特的遮蔽,减少了训练中的数据重复,有助于模型更好地处理多样化的数据和遮蔽模式。
2. 跳过下一句预测:作者发现跳过下一句预测任务会略微提高性能,并且建议使用连续句子构建输入序列,而不是来自多个文档的句子。这有助于模型更好地学习长距离依赖关系。
3. 增加批量大小:RoBERTa使用更大的批量大小,通过适当降低学习率和训练步数,这通常有助于提高模型性能。
4. 字节文本编码:RoBERTa使用字节而不是Unicode字符作为子词的基础,并扩展了词汇表大小,这使得模型能够更好地理解包含罕见词汇的复杂文本。
总的来说,RoBERTa模型通过这些改进在流行的NLP基准测试中超越了BERT模型,尽管其配置更复杂,但只增加了15M个额外的参数,保持了与BERT相当的推理速度。这为NLP领域的进一步发展提供了有力的工具和方法。
- 0000

 0000
0000

 0000
0000- 0000
- 0000