Xwin-LM击败GPT-4登顶斯坦福AlpacaEval 多项性能评估表现出色
要点:
1. Xwin-LM,一款基于Llama2微调的语言模型,成功在斯坦福AlpacaEval上击败了GPT-4,成为新的榜首模型。
2. Xwin-LM分别推出了70B、13B、7B规模的模型,在多项性能评估和自然语言处理任务中表现出色。
3. AlpacaEval是一款自动评估工具,用于比较模型在遵循指令和性能表现方面的能力,对模型的性能提供了有效的评估方法。
Xwin-LM是一款基于Llama2微调的语言模型,最近在斯坦福大学的AlpacaEval评估中一举击败了GPT-4,登上了榜首之位。这一成就引发了广泛的关注,因为GPT-4一直以来在AlpacaEval上表现出色,胜率超过95%。然而,Xwin-LM的出现改变了这一局面,展示出了其强大的性能。
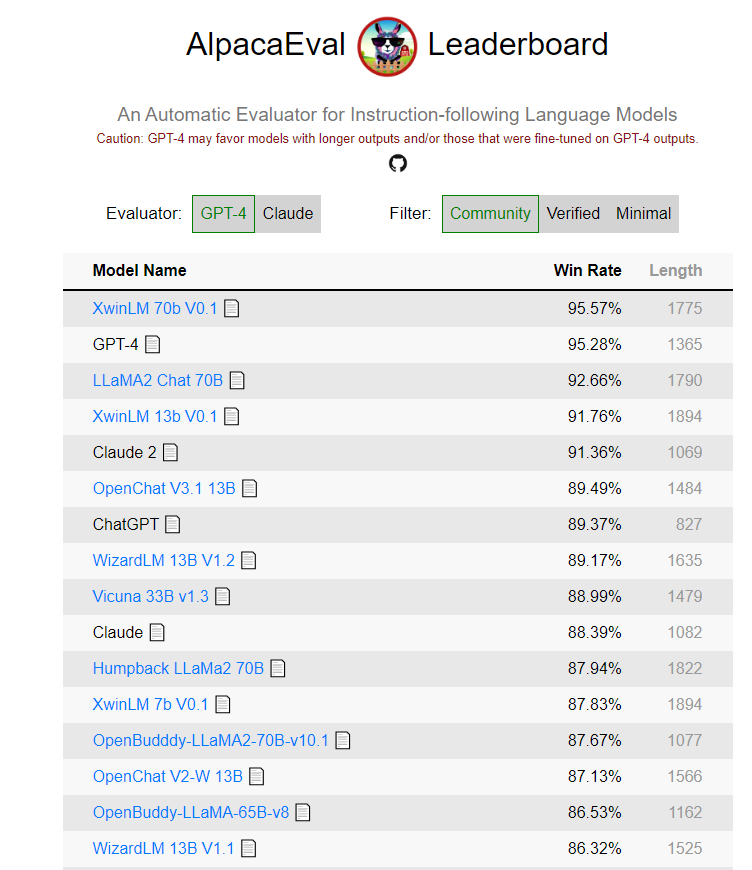
项目地址:https://tatsu-lab.github.io/alpaca_eval/
Xwin-LM不仅成功击败了GPT-4,还分别推出了70B、13B、7B规模的模型,在多项性能评估和自然语言处理任务中表现出色。其中,Xwin-LM-70B-V0.1在AlpacaEval基准测试中对Davinci-003的胜率达到95.57%,首次超越了GPT-4。而Xwin-LM-13B-V0.1在AlpacaEval上取得了91.76%的胜率,在所有13B模型中排名第一,而Xwin-LM-7B-V0.1在AlpacaEval上取得了87.82%的胜率,在所有7B机型中排名第一。这些结果显示出Xwin-LM在不同规模下的模型都具有出色的性能。
Xwin-LM的成功背后有其独特的模型微调技术,包括监督微调、奖励模型、拒绝采样、人类反馈强化学习等。这些技术的结合使得Xwin-LM能够更好地理解用户的问题并提供更准确的回答。
AlpacaEval是一个自动评估工具,它被用来比较模型在遵循指令和性能表现方面的能力。AlpacaEval在评估模型性能时考虑了多个因素,包括与人类标注的一致性、胜率等。虽然AlpacaEval提供了一种有效的评估方法,但文章也提到了其局限性,包括对模型安全性的未评估和评估集中指令的相对简单性。
总的来说,Xwin-LM的出现为大型语言模型领域带来了新的竞争力,展示了其在性能和任务完成能力方面的优势。同时,AlpacaEval作为一种自动评估工具,为研究人员提供了一种比较模型能力的有效方式。这一研究对于推动自然语言处理领域的进步具有重要意义。
- 0000
- 0000
- 0000
- 0000
- 0000