中国研究人员推ImageBind-LLM:通过ImageBind实现LLM的多模态指令调优方法
文章概要:
- 中国研究人员最近取得了在大型语言模型(LLM)指令调整领域的显着进展。
- ImageBind-LLM是一种多模态指令调优方法,通过ImageBind进行大型语言模型的微调,能够响应多种形式的输入指令。
- 该模型使用视觉语言数据来调整多模态指令,特别建议仅使用视觉语言数据进行调整。
研究人员最近在大型语言模型(LLM)的指令调整方面取得了令人瞩目的进展。这一发现对于提高通用语言模型的性能和多模态指令响应能力具有重要意义。

图源备注:图片由AI生成,图片授权服务商Midjourney
虽然通用语言模型如ChatGPT和GPT-4在语言和视觉理解方面已经取得了显著进展,但由于闭源限制,它们仍然无法实现完全的复制。因此,研究人员提出了一种使用自行生成的数据来修改可公开访问的LLaMA(语言指令模型)的方法,以解决这一问题。
为了实现多模态指令调优,研究人员推出了ImageBind-LLM,这是一种通过ImageBind进行大型语言模型的微调的方法。本研究来自上海人工智能实验室、香港中文大学MMLab和vivo AI实验室的作者介绍了ImageBind-LLM多模态指令跟随模型,该模型在预训练的ImageBind中的联合嵌入空间的方向下有效地微调LLaMA。
与之前的视觉指令模型不同,ImageBind-LLM可以响应多种形式的输入指令,而不仅仅是图片。这意味着它具有更好的可扩展性和泛化能力。
ImageBind的关键在于其图像对齐多模态嵌入空间,因此研究人员建议仅使用视觉语言数据来调整多模态指令。对于图片-标题对,他们首先使用ImageBind的冻结图像编码器提取全局图像特征,然后使用可学习的绑定网络进行嵌入转换。这些转换后的图片特征随后应用于LLaMA中的所有转换器层单词标记,从而创建了用于生成适当文本标题的视觉上下文。与之前的零初始化注意力机制不同,他们的视觉注入机制更加简单,并通过可训练的零初始化门控因子进行加权。
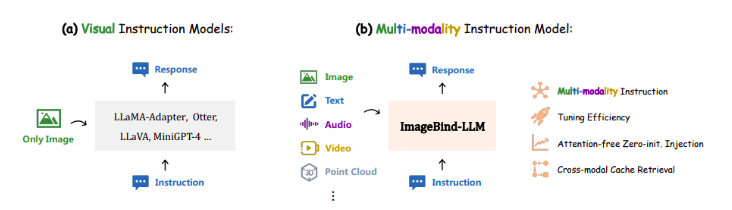
此外,研究人员还提出了一种基于视觉缓存的方法,用于在推理过程中进行嵌入增强,以解决图像训练和文本、音频、3D或视频条件下的模态差异。这个缓存模型包括了由ImageBind检索的训练数据集中的数百万图片特征,通过获得可比较的视觉特征(Tip-Adapter),提升了文本/音频/3D/视频嵌入的质量。这意味着对于多模态指令的口头回应质量更高。
ImageBind-LLM展示了四个关键特点:
1. 支持多种模式的指令,包括图片、文本、音频、3D点云和视频。
2. 实现了高效的调优方法,包括图像编码器冻结和参数高效方法的使用。
3. 使用可学习的门控方法进行渐进性知识注入,更为高效。
4. 提供了来自图像特征的视觉缓存模型,用于增强嵌入以解决训练和推理之间的模态差异。
这项研究的成果为大型语言模型的多模态指令响应能力提供了新的方法和思路,具有重要的实际应用潜力。
项目网址:https://github.com/OpenGVLab/LLaMA-Adapter
论文网址:https://arxiv.org/abs/2309.03905
- 0000

 0000
0000- 00031
- 0000

 0000
0000