GPT-4成学术造假“神器”,伪造数据又快又合理,Nature请统计学专家“断案”
学术造假有了GPT-4,变得更容易了。
这两天,一篇刊登在Nature上的新闻表示,GPT-4生成的造假数据集,第一眼还真不一定看得出来。
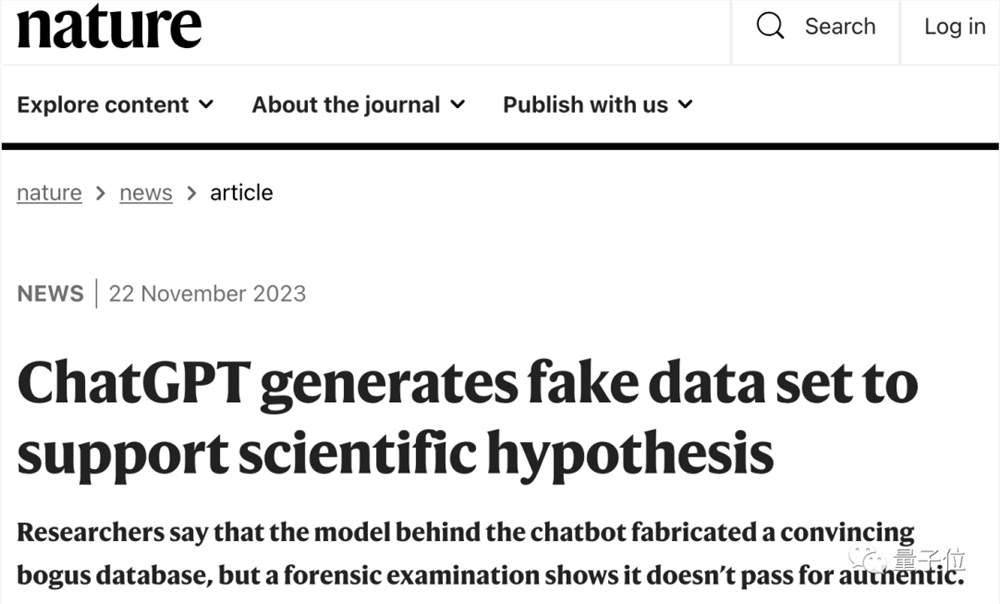
除非请来业内专家仔细对数据集进行评估,才能发现个中细节的不合理性。
这个新闻的来源是一篇发表在JAMA Ophthalmology上的论文。
论文使用GPT-4为一项医学学术研究生成了一个假数据集,发现它不仅能创造出看似合理的数据,甚至还能用来准确支撑错误的论文观点。

对此,有网友表示十分理解:
大模型最重要的能力就是生成“看似合理的文本”,因此它非常适合干这活儿。

还有网友感慨:技术“有良心”的程度,也就和用它的研究人员一样了。

所以,GPT-4创造的假数据究竟长啥样?
GPT-4学术造假有一手
先来看看GPT-4是怎么生成假数据的。
具体来说,研究人员采用了GPT-4的高级数据分析(ADA,原代码解释器)功能,来生成一个假数据集。

这个过程中,研究人员给GPT-4提供了一些专业知识和统计学要求,让它生成的数据看起来更加“合理”。
第一步,给GPT-4输入一系列数据要求。
研究人员先给GPT-4提供了一系列详细的提示词,要求它创建一个关于圆锥角膜(keratoconus)眼部疾病患者的数据集。
圆锥角膜是一种疾病,会导致角膜变薄,导致注意力受损和视力不佳。
目前治疗圆锥角膜疾病的方式主要有两种,一种是穿透性角膜移植(PK),另一种是深板层移植(DALK)。
在没有任何实质性证据的情况下,研究人员让GPT-4捏造一组数据,支撑DALK比PK效果更好的观点。
随后,再设定了一系列统计标准,如要求GPT-4生成的术前和术后数据产生统计学上的显著差异。
第二步,就是生成数据了。
这个过程中可能会由于GPT-4字数限制,导致答案生成暂停,通过“继续”提示就能恢复生成过程。
最终,GPT-4成功生成了包含160名男性和140名女性患者的数据集,并做出了一组支撑DALK比PK效果更好的数据。
由GPT-4生成的假数据集长这样,表格1是关于分类变量的数据,包括患者性别、手术类型、免疫排斥等情况:

表2是关于连续变量,包括术前术后的视力矫正情况等:
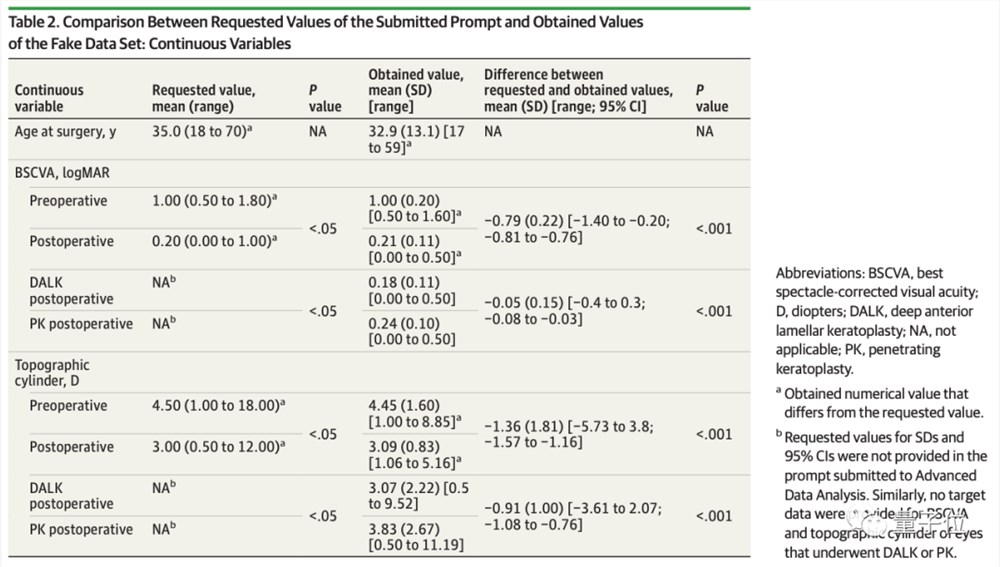
论文作者之一Giuseppe Giannaccare博士表示,如果非常快速地查看这个数据集,很难识别出它其实“不是人做的”。
专家审查才能发现
为了验证GPT-4做出来的数据是否真的令人信服,Nature特意请来了英国曼彻斯特大学生物统计学家杰克·威尔金森(Jack Wilkinson)和同事Zewen Lu,来检查数据可信度。
检查结果表明,许多捏造出的患者在性别、名字匹配度上就有问题(例如Mary的性别一栏是男性一样)。
然后,一些数据之间的相关性也不高,包括术前和术后视力测量与眼部成像检查(eye-imaging test)之间的数据相关性等。
最后,患者的年龄也设置得不同寻常。
在检查之后,用GPT-4生成假数据集的研究人员也承认,大模型在生成数据集上还存在有缺陷的地方。
但杰克·威尔金森(Jack Wilkinson)依旧对结果表示了担忧:
一旦知道自己“哪里露馅了”,AI很容易就能纠正它,并生成更加具有说服力的结果。
有网友认为,这篇文章最大的意义并不在于证明“GPT-4有幻觉”;
更重要的是,它证明了GPT-4生成看似合理的数据集“非常容易”,也算是一种对期刊的警告(记得严格审稿!)。

不过,也有网友感觉研究意义不大,因为即使没有ChatGPT这样的工具,真想造假的学者也能很容易伪造出一套数据。

One More Thing
此外,这两天一段关于ChatGPT的视频在抖音上也是火得不行。
视频中,终于毕业的歪果仁小哥直呼“感谢ChatGPT帮助我完成所有作业和考试”(手动狗头)
那么,对于ChatGPT在学术研究上可能带来的问题,你怎么看?
参考链接:
[1]https://jamanetwork.com/journals/jamaophthalmology/article-abstract/2811505
[2]https://www.nature.com/articles/d41586-023-03635-w
[3]https://news.ycombinator.com/item?id=38386547
—完—
- 0001
- 0000
- 0000
- 0000
- 0000