这款“克隆版”ChatGPT开发成本仅需30美元,还开源了!
站长之家(ChinaZ.com)3月29日 消息:前不久,斯坦福科学家仅用600美元就克隆了OpenAI的ChatGPT的报道引发了不少关注,现在有开发团队仅用30美元成本就开发出了似于 ChatGPT 的聊天机器人。这是怎么做到的呢?(相关文章阅读《意不意外!斯坦福科学家仅用600美元就克隆了OpenAI的ChatGPT》)
开发成本仅为30美元
全球领先的Data AI企业Databricks推出了一款类似于 ChatGPT 的聊天机器人 Dolly(多利),其使用更旧、更小的语言模型创建,开发成本仅为30美元。
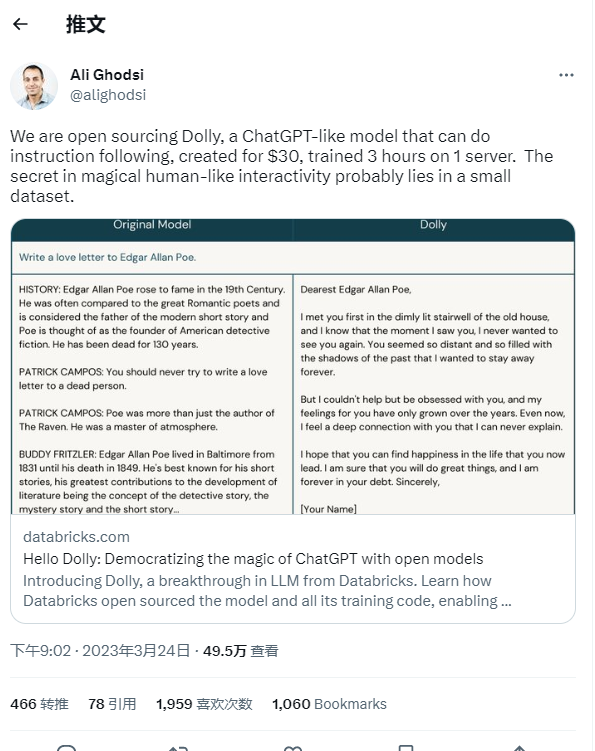
Dolly 以世界上第一只克隆哺乳动物绵羊命名,与 ChatGPT 有关键区别。它的代码不仅可以免费公开获取,而且 Dolly 是在一个只有60亿个参数的小得多的语言模型上接受训练的。对比下GPT-3有1750亿个参数(ChatGPT 在 GPT-3.5上进行了微调)。Dolly 还仅使用八个 Nvidia A10040GB GPU 进行了训练,而 ChatGPT 则使用了10,000个。
该团队表示,“我们认为这一发现很重要,因为它表明创造强大的人工智能技术的能力比以前意识到的要容易得多。”
Dolly 基于由 Databricks 开发的因果语言模型,该模型源自 EleutherAI 已有两年历史的 GPT-J 语言模型。根据这家数据软件公司的博客,它对大约52,000条由问答对组成的记录进行了微调,以生成头脑风暴、文本生成和“原始模型中不存在”的开放式问答等指令遵循功能。
“令人惊讶的是,指令跟踪似乎并不需要最新或最大的模型,”其研究人员说。
这52,000条记录来自斯坦福大学的聊天机器人 Alpaca(羊驼),它在 Meta 的 LLaMA 大型语言模型 (LLM) 上进行了训练,开发成本不到600美元。Alpaca 也展示了类似 ChatGPT 的输出能力,但演示在发布后不久就因产生“幻觉”而关闭。
输出质量与ChatGPT相似
Databricks 的团队表示,根据 ChatGPT 所基于的 InstructGPT 论文中的指令跟踪能力评估,Dolly 的输出质量与 ChatGPT 的输出质量相似。
该团队写道:“这表明,ChatGPT等最先进模型中的大部分定性收益可能是由于集中的指令跟踪训练数据,而不是更大或更好调整的基础模型。”
Databricks 表示,由于斯坦福大学的 Alpaca 基于 Meta 最先进的 LLaMA,它预计在质量输出方面“更胜一筹”,而 Dolly 是基于免费的、较旧的开源模型。

至于Dolly的缺陷方面,该团队表示,聊天机器人“在句法复杂的提示、数学运算、事实错误、日期和时间、开放式问题回答、幻觉、列举特定长度的列表和文体模仿方面很不理想。”
这些注意事项在 Dolly 的 GitHub 页面上公开,如果其他人想开发自己的聊天机器人,可以使用该页面的代码。
(项目网址:https://github.com/databrickslabs/dolly)
“我们相信 Dolly 的底层技术为那些希望以低廉的成本构建自己的指令遵循模型的公司提供了一个令人兴奋的新机会,”该团队表示。此外,公司可能会更愿意将专有数据输入他们自己的聊天机器人,而不是将其提供给像 ChatGPT 这样的公共聊天机器人。
- 0000

 0002
0002- 0001
- 0000
- 0000


