基于ChatGLM-6B 构建本地私有化离线知识库
前言
Quivr 基于Supabase构建本地知识库
如何快速部署PrivateGPT?打造企业私有化GPT
前面我们介绍过几款构建本地知识库的开源项目,其原理还是基于本地文件构建向量数据库的方式,通过调用现有GPT语言模型的能力做向量相似计算,对于希望基于GPT语言模型的能力构建自己的APP应用或者集成到现有产品中去实际上会非常方便,具有一定的市场空间。
然后,对于一些涉密或者Security等级比较高的单位或者企业,希望在保证数据安全性的前提下,也能享受大语言模型带来的红利,构建企业级本地私有化模型,基于此构建自己的GPT产品或者聊天机器人、智能客户等等
在经过了一系列的选型,尝试,对比之后,像LLaMa和GPT4ALL之类的开源模型目前对中文的支持不不够友好,另外参数量也比较小,最终发现清华大学开源的一款ChatGPT-6B模型,最关键的问题,对中文支持比较友好,也可以上传数据集自己进行模型微调,最重要的是可以支持在消费级的显卡上运行,当然了,要是实际使用还是建议选择一台具备AI算力的服务器来部署,显存至少25G以上,在没有服务器的条件下,建议使用Colab,并启用GPU A100。
一、产品介绍
1.1、GLM:预训练模型
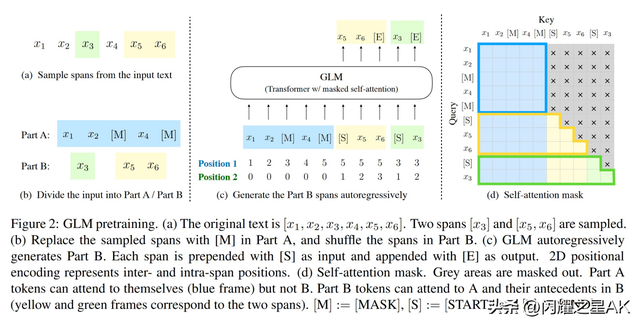
GLM的出发点是将3种主流的预训练模型进行统一:
GPT的训练目标是从左到右的文本生成
BERT的训练目标是对文本进行随机掩码,然后预测被掩码的词
T5则是接受一段文本,从左到右的生成另一段文本
1.2、开源GLM系列
GLM Github Paper(https://github.com/THUDM/GLM)
GLM-130B Github Paper(/abs/2210.02414)
ChatGLM-6B 博客(/blog)
可以在消费级的GPU上进行微调
1.3、功能演示

1.4、ChatGLM-6B
由清华大学知识工程 (KEG) 实验室和智谱AI公司与于2023年共同训练的语言模型
ChatGLM-6B 参考了 ChatGPT 的设计思路,在千 亿基座模型 GLM-130B 中注入了代码预训练,通 过有监督微调等技术实现与人类意图对齐(即让机 器的回答符合人类的期望和价值观)
ChatGLM-6B 是一个具有62亿参数的中英双语语言模型。通过使用与 ChatGLM()相同的技术,ChatGLM-6B 初具中文问答和对话功能,并支持在单张 2080Ti 上进行推理使用。
不同于训练ChatGPT需要1万 A100显卡, ChatGLM-6B可以单机运行在消费级显卡上(13G 可运行,建议16-24G显卡),未来使用空间大
具体来说,ChatGLM-6B 有如下特点:
充分的中英双语预训练: ChatGLM-6B 在 1:1 比例的中英语料上训练了 1T 的 token 量,兼具双语能力。
优化的模型架构和大小: 吸取 GLM-130B 训练经验,修正了二维 RoPE 位置编码实现,使用传统FFN结构。6B(62亿)的参数大小,也使得研究者和个人开发者自己微调和部署 ChatGLM-6B 成为可能。
较低的部署门槛: FP16 半精度下,ChatGLM-6B 需要至少 13GB 的显存进行推理,结合模型量化技术,这一需求可以进一步降低到 10GB(INT8) 和 6GB(INT4), 使得 ChatGLM-6B 可以部署在消费级显卡上。
更长的序列长度: 相比 GLM-10B(序列长度1024),ChatGLM-6B 序列长度达 2048,支持更长对话和应用。
人类意图对齐训练: 使用了监督微调(Supervised Fine-Tuning)、反馈自助(Feedback Bootstrap)、人类反馈强化学习(Reinforcement Learning from Human Feedback) 等方式,使模型初具理解人类指令意图的能力。输出格式为 markdown,方便展示。
因此,ChatGLM-6B 具备了一定条件下较好的对话与问答能力。当然,ChatGLM-6B 也有相当多已知的局限和不足:
模型容量较小: 6B 的小容量,决定了其相对较弱的模型记忆和语言能力。在面对许多事实性知识任务时,ChatGLM-6B 可能会生成不正确的信息;她也不擅长逻辑类问题(如数学、编程)的解答。
可能会产生有害说明或有偏见的内容:ChatGLM-6B 只是一个初步与人类意图对齐的语言模型,可能会生成有害、有偏见的内容。
较弱的多轮对话能力:ChatGLM-6B 的上下文理解能力还不够充分,在面对长答案生成,以及多轮对话的场景时,可能会出现上下文丢失和理解错误的情况。
英文能力不足:训练时使用的指示大部分都是中文的,只有一小部分指示是英文的。因此在使用英文指示时,回复的质量可能不如中文指示的回复,甚至与中文指示下的回复矛盾。
易被误导:ChatGLM-6B 的“自我认知”可能存在问题,很容易被误导并产生错误的言论。例如当前版本模型在被误导的情况下,会在自我认知上发生偏差。即使该模型经过了1万亿标识符(token)左右的双语预训练,并且进行了指令微调和人类反馈强化学习(RLHF),但是因为模型容量较小,所以在某些指示下可能会产生有误导性的内容。
1.5、ChatGLM-130B
2022年8月,智谱AI基于GLM框架,推出1300亿参数的中英双语稠密模型GLM-130B,综合能力与GPT3相当 内存节省75%,可在单台3090 (4)或单台2080(8)进行无损推理 高速推理,比Pytorch提升7-8倍速度
跨平台,支持不同计算平台的适配和应用
ChatGLM 参考了 ChatGPT 的设计思路,在千亿基座模型 GLM-130B1 中注入了代码预训练,通过有监督微调(Supervised Fine-Tuning)等技术实现人类意图对齐。ChatGLM 当前版本模型的能力提升主要来源于独特的千亿基座模型 GLM-130B。它是不同于 BERT、GPT-3 以及 T5 的架构,是一个包含多目标函数的自回归预训练模型。2022年8月,我们向研究界和工业界开放了拥有1300亿参数的中英双语稠密模型 GLM-130B1,该模型有一些独特的优势:
双语: 同时支持中文和英文。
高精度(英文): 在公开的英文自然语言榜单 LAMBADA、MMLU 和 Big-bench-lite 上优于 GPT-3 175B(API: davinci,基座模型)、OPT-175B 和 BLOOM-176B。
高精度(中文): 在7个零样本 CLUE 数据集和5个零样本 FewCLUE 数据集上明显优于 ERNIE TITAN 3.0 260B 和 YUAN 1.0-245B。
快速推理: 首个实现 INT4 量化的千亿模型,支持用一台 4 卡 3090 或 8 卡 2080Ti 服务器进行快速且基本无损推理。
可复现性: 所有结果(超过 30 个任务)均可通过我们的开源代码和模型参数复现。
跨平台: 支持在国产的海光 DCU、华为昇腾 910 和申威处理器及美国的英伟达芯片上进行训练与推理。

三、系统部署
3.1、硬件要求
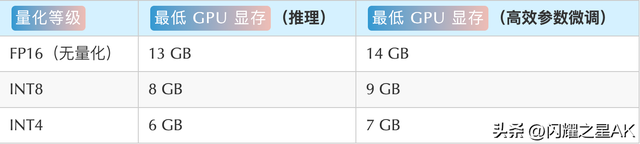
在无量化的情况下,显存初始化基本上都需要13G内存,16G的显存可能对话两轮就内存爆满了,个人部署建议还是使用量化模型。
3.2、系统环境
操作系统:CentOS 7.6 (内存:32G)
显卡配置: 2x NVIDIA Gefore 3070Ti 8G (共16G显存)
Python 3.8.13 (版本不要高于3.10,否则有些依赖无法下载,像paddlepaddle 2.4.2在高版本Python还不支持)
# 安装Python3.8所需依赖sudo yum -y install gcc zlib zlib-devel openssl-devel# 下载源码wget /ftp/python/3.8.13/Python-3.8.13.tgz# 解压缩tar -zxvf Python-3.8.13.tgz# 编译配置,注意:不要加 --enable-optimizations 参数./configure --prefix=/usr/local/python3# 编译并安装make && make install
3.3、部署ChatGLM 6B
3.3.1、下载源码git clone https://github.com/imClumsyPanda/langchain-ChatGLM.gitcd langchain-ChatGLM
3.3.2、配置Python虚拟环境
确认您已经安装了 Python 3.8.13,可以在终端或命令行中输入 python3 -V 来检查。
python3.8 -m venv env38
其中 env38 是您为该虚拟环境取的名字,可以根据需要自行更改。
激活虚拟环境。在终端或命令行中输入 source env38/bin/activate(Mac/Linux) 或 env38\Scripts\activate.bat(Windows)激活虚拟环境。# 激活虚拟环境source env38/bin/activate# 升级pip到最新版本pip install --upgrade pip
在虚拟环境中安装所需的 Python 包和依赖项。可以使用 pip 命令来安装,例如 pip install numpy。
当您完成所有操作后,可以使用 deactivate 命令退出虚拟环境。
注意:为了不影响全局的Python环境,建议后续所有的操作都在Python的虚拟环境中执行,终端中显示(myenv)你的虚拟环境名称就代表你当前切入的虚拟环境。
3.3.3、设置国内镜像源
为了构建依赖更快一点,我们可以使用阿里云的镜像源进行下载
如果你在国内使用pip安装缓慢,可以考虑切换至腾讯的源:pip config set global.index-url
https://mirrors.aliyun.com/pypi/simple/
镜像同步版本可能不及时,如果出现这种情况建议切换至官方源:pip config set global.index-url /simple

3.3.4、安装依赖
# 项目中 pdf 加载由先前的 detectron2 替换为使用 paddleocr,如果之前有安装过 detectron2 需要先完成卸载避免引发 tools 冲突$ pip uninstall detectron2# 检查paddleocr依赖,linux环境下paddleocr依赖libX11,libXext$ yum install libX11$ yum install libXext# 安装依赖pip install -r requirements.txt# 如果没有设置pip的下载镜像,也可以直接用-i参数指定镜像源地址# pip install -r requirements.txt -i https://mirrors.aliyun.com/pypi/simple/
3.3.5、安装Git LFS
因为模型文件较大,如果你的网络环境较差,下载模型参数可能会花费较长时间甚至失败。此时可以先将模型下载到本地,然后从本地加载。Git下载大文件需要安装Git LFS# 下载Git LFS安装文件wget -O git-lfs-3.3.0-1.el7.x86_64.rpm /1358/1665/el/7/package_files/2361926.rpm?t=1685358605_8973d6064d1793877554bc4a45dd68c5388da3eb# 设置文件执行权限chmod xgit-lfs-3.3.0-1.el7.x86_64.rpm# 通过yum命令安装yum install git-lfs-3.3.0-1.el7.x86_64.rpm# 验证Git LFS是否安装成功git-lfs/3.3.0 (GitHub; linux amd64; go 1.19.3; git 77deabdf)
3.3.6、下载模型
1)选项1:从 Hugging Face Hub 下载
模型需要先安装Git LFS,然后克隆下载运行(由于访问HuggingFace网络不稳定,仓库文件过大会出现抖动,下载失败的情况)

# 下载 LLM 模型git clone /THUDM/chatglm-6b /your_path/chatglm-6b# 下载 Embedding 模型git clone /GanymedeNil/text2vec-large-chinese /your_path/text2vec# 模型需要更新时,可打开模型所在文件夹后拉取最新模型文件/代码git pull
由于文件太大,如果从Huggingface网站上下载失败的,可以考虑用从清华的镜像下载或者百度网盘进行下载:
2)选项2:手动下载 当从huggingface repo下载的速度很慢时,可以使用这个方法
第1步:克隆 repo,跳过大文件
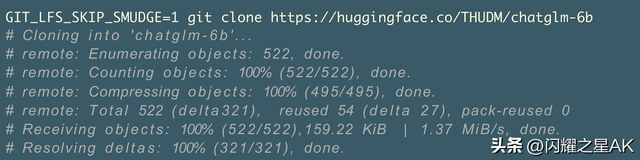
第2步:从清华云下载模型文件大文件,一个一个地下载是很麻烦的,注意下载完模型后需要与前面HuggingFace克隆下来的项目进行合并。
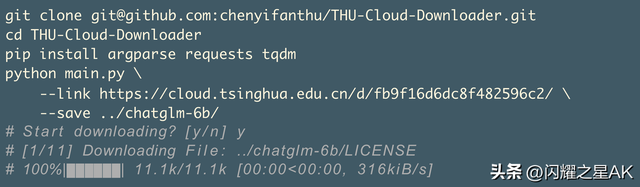
为了解决网络问题和一个个下载繁琐的问题,langchain-chatglm为大家提供了从百度网盘下载的方式。#清华镜像下载地址:/d/674208019e314311ab5c/?p=%2F&mode=list- chatglm-6b:/d/674208019e314311ab5c/?p=%2Fchatglm-6b&mode=list- chatglm-6b-int4:/d/674208019e314311ab5c/?p=%2Fchatglm-6b-int4&mode=list- chatglm-6b-int8:/d/674208019e314311ab5c/?p=%2Fchatglm-6b-int8&mode=list- text2vec-large-chinese:/GanymedeNil/text2vec-large-chinese
#百度网盘下载地址:- ernie-3.0-base-zh.zip 链接: [https://pan.baidu.com/s/1CIvKnD3qzE-orFouA8qvNQ?pwd=4wih](https://pan.baidu.com/s/1CIvKnD3qzE-orFouA8qvNQ?pwd=4wih)- ernie-3.0-nano-zh.zip 链接: [https://pan.baidu.com/s/1Fh8fgzVdavf5P1omAJJ-Zw?pwd=q6s5](https://pan.baidu.com/s/1Fh8fgzVdavf5P1omAJJ-Zw?pwd=q6s5)- text2vec-large-chinese.zip 链接: [https://pan.baidu.com/s/1sMyPzBIXdEzHygftEoyBuA?pwd=4xs7](https://pan.baidu.com/s/1sMyPzBIXdEzHygftEoyBuA?pwd=4xs7)- chatglm-6b-int4-qe.zip 链接: [https://pan.baidu.com/s/1DDKMOMHtNZccOOBGWIOYww?pwd=22ji](https://pan.baidu.com/s/1DDKMOMHtNZccOOBGWIOYww?pwd=22ji)- chatglm-6b-int4.zip 链接: [https://pan.baidu.com/s/1pvZ6pMzovjhkA6uPcRLuJA?pwd=3gjd](https://pan.baidu.com/s/1pvZ6pMzovjhkA6uPcRLuJA?pwd=3gjd)- chatglm-6b.zip 链接: [https://pan.baidu.com/s/1B-MpsVVs1GHhteVBetaquw?pwd=djay](https://pan.baidu.com/s/1B-MpsVVs1GHhteVBetaquw?pwd=djay)
3.3.7、模型配置
模型下载完成后,请在 configs/model_config.py 文件中,对embedding_model_dict和llm_model_dict参数进行修改。embedding_model_dict = {
'ernie-tiny': 'nghuyong/ernie-3.0-nano-zh',
'ernie-base': 'nghuyong/ernie-3.0-base-zh',
'text2vec-base': 'shibing624/text2vec-base-chinese',
'text2vec': '/your_path/text2vec-large-chinese',}# supported LLM models# llm_model_dict 处理了loader的一些预设行为,如加载位置,模型名称,模型处理器实例llm_model_dict = {
'chatglm-6b-int4-qe': {
'name': 'chatglm-6b-int4-qe',
'pretrained_model_name': 'THUDM/chatglm-6b-int4-qe',
'local_model_path': None,
'provides': 'ChatGLM'
},
'chatglm-6b-int4': {
'name': 'chatglm-6b-int4',
'pretrained_model_name': '/your_path/chatglm-6b-int4',
'local_model_path': None,
'provides': 'ChatGLM'
},
'chatglm-6b-int8': {
'name': 'chatglm-6b-int8',
'pretrained_model_name': '/your_path/chatglm-6b-int8',
'local_model_path': None,
'provides': 'ChatGLM'
},
'chatglm-6b': {
'name': 'chatglm-6b',
'pretrained_model_name': '/your_path/chatglm-6b',
'local_model_path': None,
'provides': 'ChatGLM'
},
'chatyuan': {
'name': 'chatyuan',
'pretrained_model_name': 'ClueAI/ChatYuan-large-v2',
'local_model_path': None,
'provides': None
},
'moss': {
'name': 'moss',
'pretrained_model_name': 'fnlp/moss-moon-003-sft',
'local_model_path': None,
'provides': 'MOSSLLM'
}}
四、系统启动
4.1、Web 模式启动
pip install gradiopython webui.py
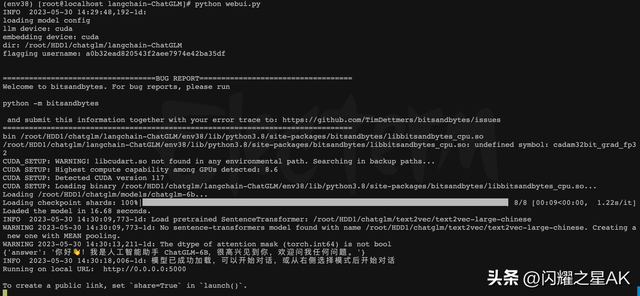
启动完成后如下图所示,如在启动过程中遇到问题可以查阅官方仓库中的FAQ.md,启动端口可以根据需要在webui.py最末尾处修改。
4.1.1、访问系统
直接访问系统可以看到默认提供的一个demo体验界面,该界面主要实现了以下基本功能:
运行前自动读取configs/model_config.py中LLM及Embedding模型枚举及默认模型设置运行模型,如需重新加载模型,可在 模型配置 Tab 重新选择后点击 重新加载模型 进行模型加载;
可手动调节保留对话历史长度、匹配知识库文段数量,可根据显存大小自行调节;
对话 Tab 具备模式选择功能,可选择 LLM对话 与 知识库问答 模式进行对话,支持流式对话;
添加 配置知识库 功能,支持选择已有知识库或新建知识库,并可向知识库中新增上传文件/文件夹,使用文件上传组件选择好文件后点击 上传文件并加载知识库,会将所选上传文档数据加载至知识库中,并基于更新后知识库进行问答;
新增 知识库测试 Beta Tab,可用于测试不同文本切分方法与检索相关度阈值设置,暂不支持将测试参数作为 对话 Tab 设置参数。
后续版本中将会增加对知识库的修改或删除,及知识库中已导入文件的查看。

【说明】:如果采用默认配置启动未量化的ChatGLM-6B,初始状态需要消耗13G的显存,如果显存不够的建议选择量化INT4或者INT8来运行,需要修改configs/model_config.py,将LLM的值修改为chatglm-6b-int4或者chatglm-6b-int8.
以下是我基于chatglm-6b-int4运行,进行了几轮对话,基本上效果还可以,显存消耗7G左右。
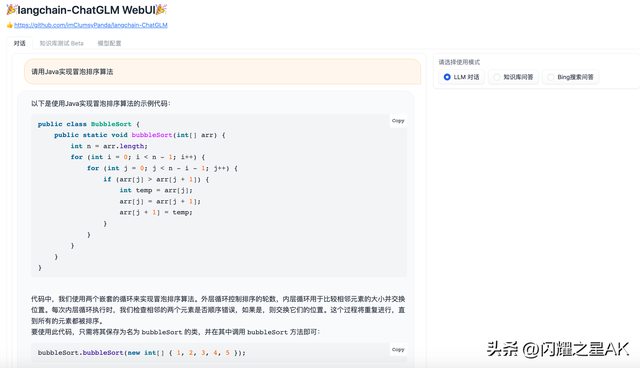
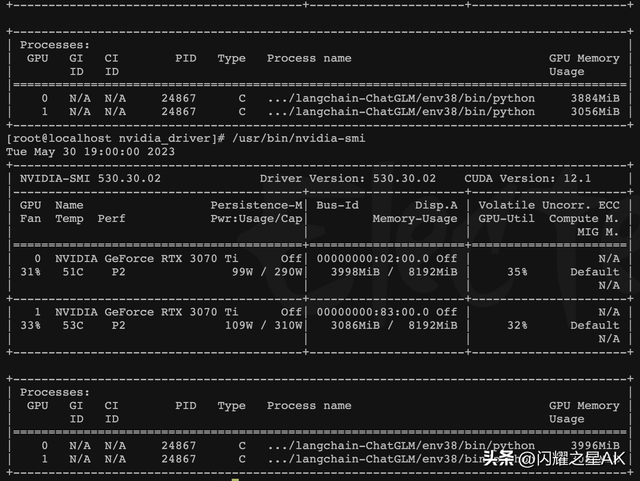
4.1.2、模型配置
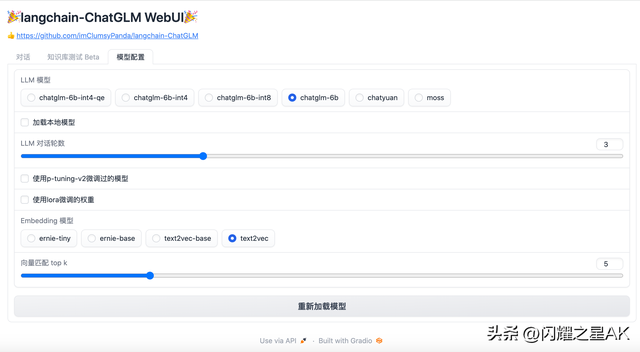
4.1.3、上传知识库
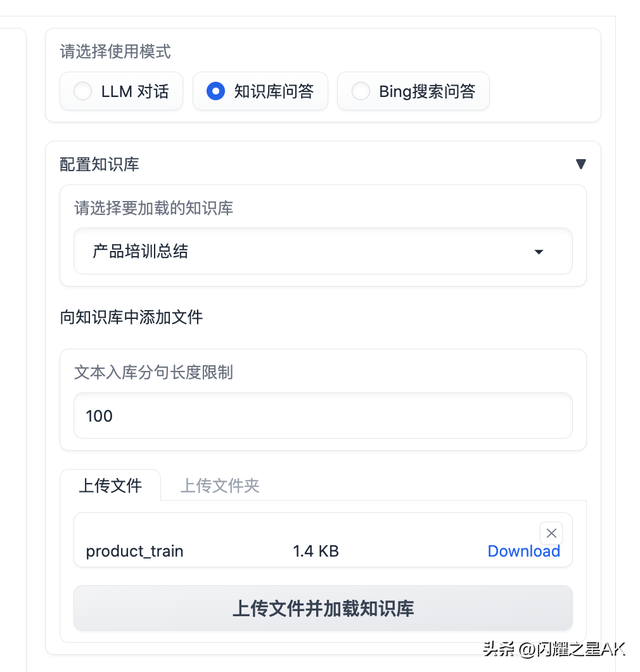
INFO 2023-05-30 19:22:44,945-1d: /root/HDD1/chatglm/langchain-ChatGLM/content/产品培训总结/product_train 已成功加载INFO 2023-05-30 19:22:44,945-1d: 文件加载完毕,正在生成向量库Batches: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 5.90it/s]INFO 2023-05-30 19:22:45,826-1d: Loading faiss with AVX2 support.INFO 2023-05-30 19:22:45,852-1d: Successfully loaded faiss with AVX2 support.INFO 2023-05-30 19:22:45,895-1d: 已添加 product_train 内容至知识库,并已加载知识库,请开始提问
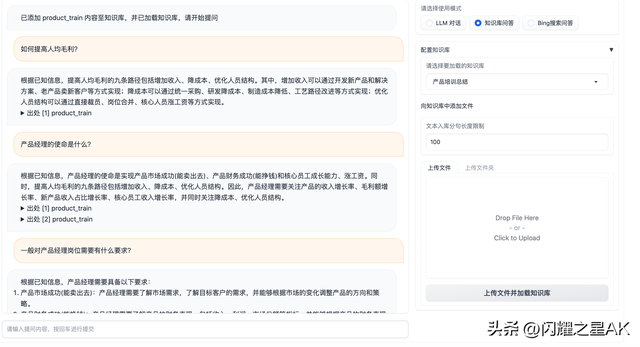
回答情况基本上是根据我提供的素材进行的语言组织来回答的,如果提交的稳定质量比较高,再经过微调,实现智能客户类的应用基本上可以满足需求。
4.2、命令行启动
$ python cli_demo.py
五、FAQ
问题1、torch.cuda.OutOfMemoryError: CUDA out of memory
很明显,显存不足,建议切换到chatglm-6b-int4或者chatglm-6b-int4torch.cuda.OutOfMemoryError: CUDA out of memory. Tried to allocate 2.00 MiB (GPU 0; 7.80 GiB total capacity; 5.95 GiB already allocated; 2.56 MiB free; 6.91 GiB reserved in total by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF
问题2、'RuntimeError: Library cudart is not initialized'
这个错误通常是由于缺少或损坏的 CUDA 库文件引起的。要解决这个问题,需要安装 CUDA Toolkit :
安装CUDA Toolkit
sudo yum-config-manager --add-repo https://developer.download.nvidia.com/compute/cuda/repos/rhel7/x86_64/cuda-rhel7.reposudo yum clean allsudo yum -y install nvidia-driver-latest-dkmssudo yum -y install cuda
在安装 CUDA Toolkit 后,您需要设置一些环境变量以确保 CUDA 应用程序能够正常工作。以下是一些常见的环境变量:
1)、PATH:将 CUDA 工具和库路径添加到 PATH 环境变量中,以便系统可以找到它们。export PATH=/usr/local/cuda-12.1/bin:$PATH
2)、LD_LIBRARY_PATH:将 CUDA 库路径添加到 LD_LIBRARY_PATH 环境变量中,以便系统可以加载它们。这通常包括 CUDA 运行时库、CUDA 驱动程序和 NVIDIA 图形驱动程序。
export LD_LIBRARY_PATH=/usr/local/cuda-12.1/lib64:$LD_LIBRARY_PATH
3)、CUDA_HOME:设置 CUDA_HOME 环境变量指向您的 CUDA 安装路径,以便其他程序可以使用它。export CUDA_HOME=/usr/local/cuda-12.1
为了使上述环境变量在每次登录时都可用,可以将它们添加到 ~/.bashrc 文件中,或者根据您所使用的 shell 添加到其他 shell 配置文件中。
4)、检查 CUDA 路径:首先,请确保您已经正确安装了 CUDA 并且设置了正确的环境变量。您可以检查 CUDA 的安装路径和环境变量是否正确设置。例如,在bash下,您可以通过运行以下命令来查看CUDA的版本和路径
nvcc --versionecho $LD_LIBRARY_PATH
问题3、ImportError: libGL.so.1: cannot open shared object file: No such file or directory
这个错误通常是由于缺少 OpenGL 库文件引起的。要解决这个问题,您需要安装缺失的 opengl 包。在 CentOS 系统中,您可以使用以下命令来安装 opengl 包:sudo yum install mesa-libGL
如果您已经安装了这个包但是还遇到了相同的问题,您可以尝试使用以下命令创建软链接:
sudo ln -sf /usr/lib64/libGL.so.1 /usr/lib/libGL.so.1
这个命令会将 /usr/lib64/libGL.so.1 文件的软链接创建到 /usr/lib/libGL.so.1 文件上,这通常可以解决 libGL.so.1 无法打开的问题。
问题4、ModuleNotFoundError: No module named '_sqlite3'
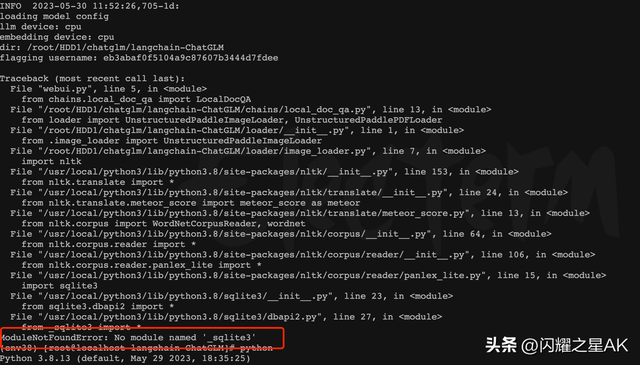
重新编译Python支持sqlite3数据库# 配置Python编译参数,增加sqlite3支持,--prefix指定编译安装路径LDFLAGS='${LDFLAGS} -Wl,-rpath=/usr/local/openssl/lib' ./configure --with-openssl=/usr/local/openssl --prefix=/root/HDD1/chatglm/langchain-ChatGLM/env38/bin/python3.8 --enable-loadable-sqlite-extensions# 编译并安装makemake install# 验证Python是否支持sqlite3,进入Python解释器环境import sqlite3print(sqlite3.version)
如果您想要替换虚拟环境中的 Python,并且保留已安装的第三方库(即 site-packages 目录),可以按照以下步骤操作:
备份当前虚拟环境的 site-packages 目录。在命令行中,进入虚拟环境所在的目录,然后使用以下命令将 site-packages 目录打包并备份到当前目录下(以 Linux 系统为例):
tar -czvf site-packages.tar.gz /path/to/virtualenv/lib/python3.x/site-packages
这将在虚拟环境目录下创建一个名为 site-packages.tar.gz 的压缩文件,其中包含了所有已安装的第三方库。
下载并安装新版本的 Python。您可以从 Python 官网下载适用于您的操作系统的安装程序,并按照提示进行安装。请确保选择与现有虚拟环境兼容的 Python 版本,并记下其安装路径。
删除原始虚拟环境中的 Python 解释器。在命令行中,进入虚拟环境所在的目录,然后运行以下命令删除原始的 Python 解释器(以 Linux 系统为例):rm -rf /path/to/virtualenv/bin/python
创建一个指向新 Python 解释器的符号链接。在虚拟环境所在的目录中,运行以下命令:
ln -s /path/to/new/python /path/to/virtualenv/bin/python
这将创建一个名为 python 的符号链接,它将指向新 Python 解释器的路径。
恢复 site-packages 目录。在虚拟环境所在的目录下,解压之前备份的 site-packages 目录的压缩文件,并恢复所有已安装的第三方库:tar -xzvf site-packages.tar.gz -C /path/to/virtualenv/lib/python3.x/
请注意修改上述命令中的 /path/to/virtualenv 和 /path/to/new/python 为实际的路径。如果您使用的是 Windows 系统,请相应地调整路径格式。
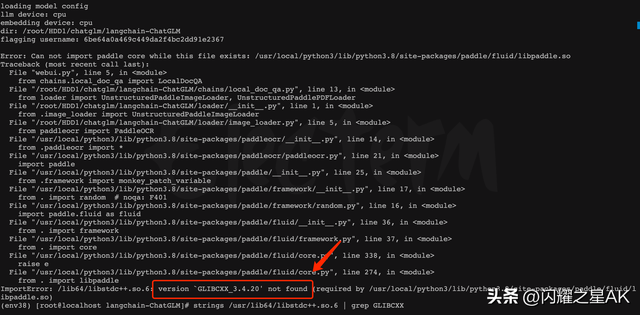
问题5、libstdc .so.6: version `GLIBCXX_3.4.20' not found
原因:CentOS 7.6默认安装的gcc版本为4.6.8,不支持GLIBCXX_3.4.20,需要升级gcc版本.
1)配置阿里elrepo镜像源
首先按照官网的安装说明,配置 ELRepo:
> rpm --import https://www.elrepo.org/RPM-GPG-KEY-elrepo.org
接着,按照你的系统版本,如果是 RHEL-8 或者 CentOS-8 则运行:> yum install https://www.elrepo.org/elrepo-release-8.el8.elrepo.noarch.rpm
RHEL-7, SL-7 或者 CentOS-7:
> yum install https://www.elrepo.org/elrepo-release-7.el7.elrepo.noarch.rpm
RHEL-6, SL-6 或者 CentOS-6:> yum install https://www.elrepo.org/elrepo-release-6.el6.elrepo.noarch.rpm
建议先备份
/etc/yum.repos.d/elrepo.repo :
sudo cp /etc/yum.repos.d/elrepo.repo /etc/yum.repos.d/elrepo.repo.bak
然后编辑
/etc/yum.repos.d/elrepo.repo 文件,在 mirrorlist= 开头的行前面加 # 注释掉;并将 elrepo.org/linux 替换为 mirrors.aliyun.com/elrepo。
最后,更新软件包缓存sudo yum makecache
2)安装新版本gcc
CentOS 7.6 默认安装的 GCC 版本是 4.8.5,如果需要升级到较新的版本,您可以按照以下步骤进行:
添加 SCL 软件仓库
SCL(Software Collections)是一种在 CentOS 中使用较新软件包的方法。您首先需要安装 centos-release-scl 包来启用 SCL 软件仓库:
sudo yum install centos-release-scl
安装所需的 GCC 版本
列出所有可用的 GCC 版本:sudo yum list devtoolset*
选择其中一个较新的版本,例如 GCC 8:
sudo yum install -y devtoolset-8-gcc devtoolset-8-gcc-c
安装后,您需要激活 devtoolset-8 工具集以使用新的 GCC 编译器。
激活 devtoolset-8
运行以下命令激活 devtoolset-8 工具集:scl enable devtoolset-8 bash
您也可以将此命令添加到 .bashrc 文件中,以便每次登录时自动激活工具集。
检查 GCC 版本
运行以下命令检查 GCC 版本:
[root@localhost lib64]# gcc --versiongcc (GCC) 8.3.1 20190311 (Red Hat 8.3.1-3)Copyright (C) 2018 Free Software Foundation, Inc.This is free software; see the source for copying conditions. There is NOwarranty; not even for MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE.
如果输出显示使用的是新版 GCC,则表明已经成功升级了。
3)创建软链指向新的gcc
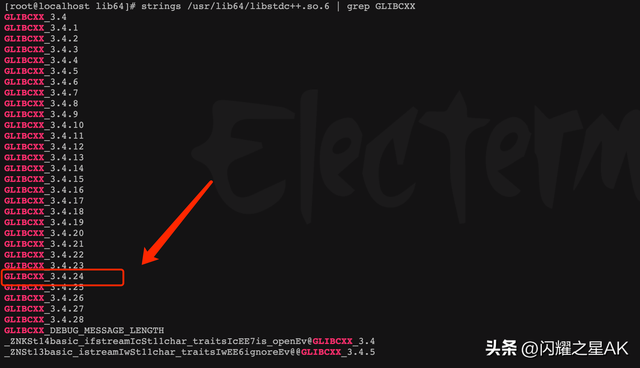
在安装完新版本的编译器之后,按照以下步骤执行,即可解决/lib64/libstdc .so.6:找不到版本“GLIBCXX_3.4.20”的问题。# 查看新版本gcc的安装路径which gcc# /opt/rh/devtoolset-8/root/usr/bin/gcc# /opt/gcc-10.2.1/usr/lib64/libstdc .so.6.0.28# 进入gcc安装目录cd /opt/gcc-10.2.1/usr/lib64cp libstdc .so.6.0.28 /usr/lib64/cd /usr/lib64/mv libstdc .so.6 libstdc .so.6.OLDln -sf libstdc .so.6.0.28 libstdc .so.6

strings /usr/lib64/libstdc .so.6 | grep GLIBCXX

 0000
0000

 0000
0000
 0005
0005- 0000
 0000
0000