腾讯 AI Lab联合多家学术机构发布大模型幻觉问题评估
要点:
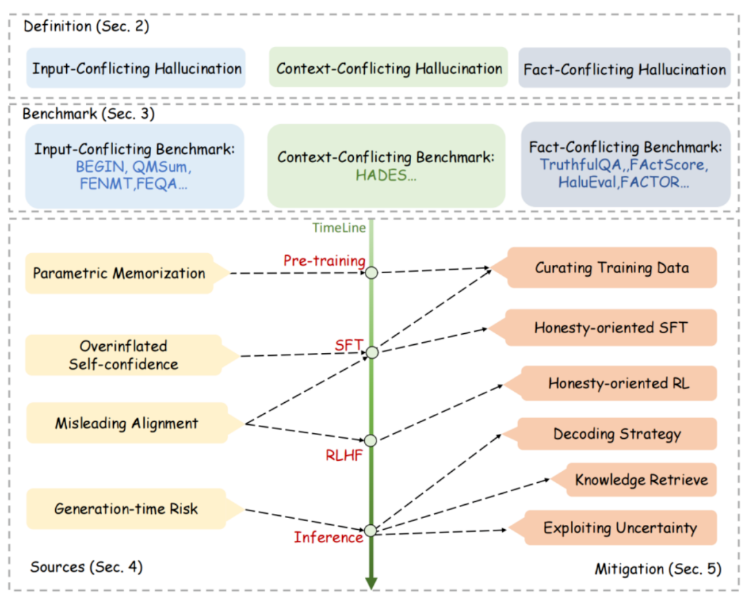
1、大模型幻觉主要分为与输入、上下文及事实冲突的三类,研究热点在第三类。
2、相比传统模型,大模型幻觉评估面临数据规模大、通用性强、不易察觉等新难题。
3、缓解幻觉可从预训练、微调、强化学习、推理等方面入手,但仍有可靠评估等挑战。
近年来,大规模语言模型在许多下游任务上表现强劲,但也面临着一定的挑战。其中,大模型生成的与事实冲突的“幻觉”内容已成为研究热点。近期,腾讯 AI Lab 联合国内外多家学术机构发布了面向大模型幻觉工作的综述,对幻觉的评估、溯源、缓解等进行了全面的探讨。
论文链接:https://arxiv.org/abs/2309.01219
Github 链接:https://github.com/HillZhang1999/llm-hallucination-survey
研究者根据大模型幻觉与用户输入、模型生成内容及事实知识的冲突,将其分为三大类。目前研究主要集中在与事实知识冲突的幻觉上,因为这最易对用户产生误导。与传统语言生成任务中幻觉问题不同,大模型幻觉面临数据规模巨大、模型通用性强以及幻觉不易被察觉等新难题。
针对大模型幻觉的评估,已提出多种生成式和判别式的基准,以问答、对话等不同任务形式检验模型的幻觉倾向。这些基准各自设计了判定幻觉的指标,但可靠的自动评估仍有待探索。分析认为,海量低质训练数据以及模型对自身能力的高估是导致幻觉的重要原因。
为减少幻觉,可从预训练、微调、强化学习等多个阶段进行干预。预训练可关注语料质量;微调可人工检查数据;强化学习可惩罚过度自信的回复。此外推理阶段,也可通过解码策略优化、知识检索、不确定度测量等方式缓解幻觉。尽管取得一定进展,可靠评估、多语言场景、模型安全性等方面仍存在诸多挑战。总体来说,大模型幻觉的评估与缓解仍有待深入研究,以促进大模型的实际应用。
- 0000
- 0002
- 0000
- 0000
- 0000