英伟达GH200在MLPerf 3.1中惊艳亮相,性能相比H100跃升17%
要点:
英伟达最新发布的GH200Grace Hopper超级芯片,在MLPerf3.1基准测试中首次亮相。
GH200的性能比单个H100提升了17%,在各测试项目上表现均超过了H100。
MLPerf Inference3.1新增了大语言模型GPT-J的推理测试,以及更新后的DLRM推理测试。
MLPerf作为业界公认的AI系统性能基准测试,最近发布了3.1版本。此版本中,英伟达最新发布的GH200Grace Hopper超级芯片首次在公开基准中亮相。
测试结果显示,GH200的性能比单个H100GPU提升了17%,在服务器场景的各个测试项目上均具有明显优势。这主要得益于GH200集成了Grace CPU和H100GPU,并通过高达900GB/s的NVLink连接,实现了卓越的CPU-GPU协同计算性能。

此外,MLPerf Inference3.1也做出两点重要更新:
一是新增了GPT-J大语言模型的推理测试;
二是更新了DLRM推理测试的模型和数据集。可以看出,随着硬件性能的进步和AI模型的演进,基准测试也需要不断更新,以更好地评估不同系统在真实应用中的表现。GH200在此次基准测试中的抢眼表现预示着其在AI系统中的强大实力。
英伟达推出的GH200Grace Hopper超级芯片,它将一个H100GPU和Grace CPU集成在一起,通过900GB/s的NVLink-C2C连接。CPU和GPU分别配备了480GB的LPDDR5X内存和96GB的HBM3或者144GB的HBM3e的内存,集成了高达576GB以上的高速访问内存。
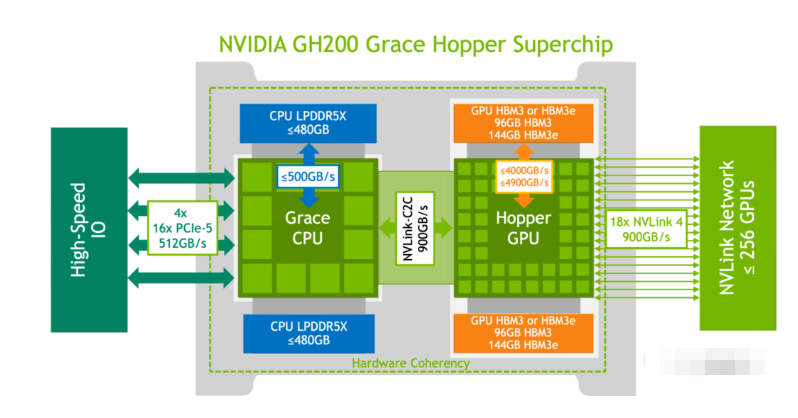
GH200Grace Hopper超级芯片专为计算密集型工作负载而设计,能够满足各种严苛的要求和各项功能。它可以训练和运行数万亿参数的大型Transformer模型,或者是运行具有数TB大小的嵌入表的推荐系统和向量数据库。在MLPerf Inference测试中,GH200刷新了英伟达单个H100SXM在每个项目中创下的最佳成绩。
与H100SXM相比,GH200Grace Hopper超级芯片集成了更大的内存容量和更大的内存带宽,使得在NVIDIA GH200Grace Hopper超级芯片上使用更大的批处理大小来处理工作负载。例如,在服务器场景中,RetinaNet和DLRMv2的批处理大小都增加了一倍,在离线场景中,批处理大小增加了50%。
GH200Grace Hopper超级芯片在Hopper GPU和Grace CPU之间的高带宽NVLink-C2C连接可以实现CPU和GPU之间的快速通信,从而有助于提高性能。例如,在MLPerf DLRMv2中,通过PCIe传输一批张量(Tensor)需要22%的批处理推理时间,而使用NVLink-C2C的GH200Grace Hopper超级芯片仅使用3%的推理时间就完成了相同的传输。
由于具有更高的内存带宽和更大的内存容量,与MLPerf Inference v3.1的H100GPU相比,Grace Hopper超级芯片的单芯片性能优势高达17%。此外,英伟达还展示了在目标检测AI网络RetinaNet上,英伟达的产品的性能提高了高达84%。
除了GH200Grace Hopper超级芯片,英伟达还推出了Jetson AGX Orin和Jetson Orin NX模块,为AI应用和机器人应用提供出色的性能。未来的软件优化将进一步释放这些模块中的英伟达Orin SoC的强大潜力。

 0000
0000

 0000
0000
 0002
0002
 0001
0001- 0000