北邮、南洋理工推沙雕视频数据集FunQA 用算法学习喜剧
要点:
1.FunQA是一个包含4365个反直觉视频和312万个文本问答的新数据集。
2.FunQA包含3个子集:幽默视频HumorQA、创意视频CreativeQA和魔术视频MagicQA。
3.FunQA设计了时间戳定位、详细描述、反直觉推理等任务,对模型的理解力提出深入挑战。
来自北京邮电大学、新加坡南洋理工大学及艾伦人工智能研究所的学者们提出了FunQA,一个全新的高质量视频问答数据集,用于测试和提高AI模型对反直觉视频内容的理解能力。
论文地址:https://arxiv.org/abs/2306.14899
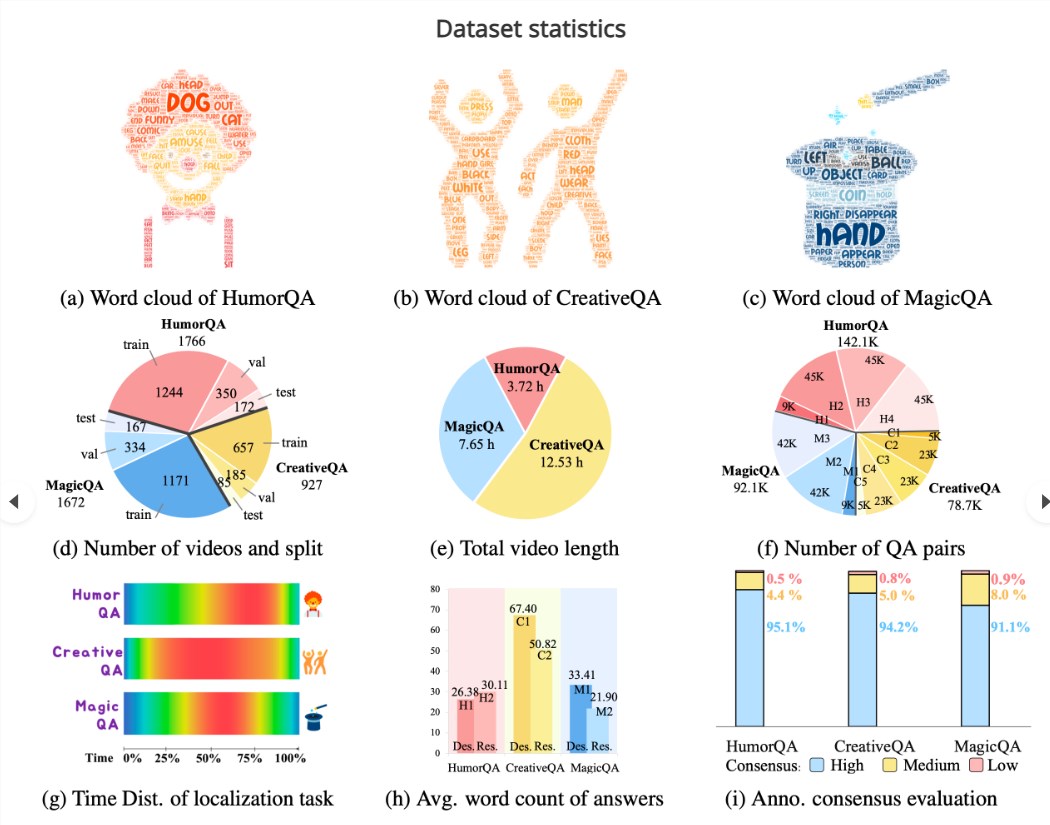
FunQA包含总时长近24小时、来自3种反直觉艺术类型的4365个短视频,以及312万条人工注释的视频问答对。它由3个子集组成:幽默视频集HumorQA、创意视频集CreativeQA和魔术视频集MagicQA。这些具有反直觉特点的视频可以对模型的理解力产生深入的挑战。
项目地址:https://funqa-benchmark.github.io/
与现有视频QA数据集相比,FunQA有以下特点:
1. 专注反直觉领域,测试模型对非常规事件的理解力。
2. annotation丰富,每个问答平均34词,远超其他数据集。
3. 创新探索幽默感理解,需要模型学习幽默原理。
4. 强调深度时空推理,如通过常识判断幽默反差。
5. 设计了时间戳定位、详细描述、反直觉推理等任务考察模型的视觉编码、语义表达和逻辑推理能力。
FunQA的具体组成如下:
1. HumorQA:来自脱口秀和模仿秀的1335个幽默视频。
2. CreativeQA:来自创意短视频平台的1465个反常识创意视频。
3. MagicQA:来自网络平台的1565个难以理解的魔术视频。
针对每个子集,FunQA设计了3个核心任务:
1. 反直觉时间戳定位:找到视频中关键反直觉事件的时间点。
2. 详细视频描述:用语句描述视频内容。
3. 反直觉推理:解释视频中反直觉的原因。
此外还有视频标题生成等扩展任务。
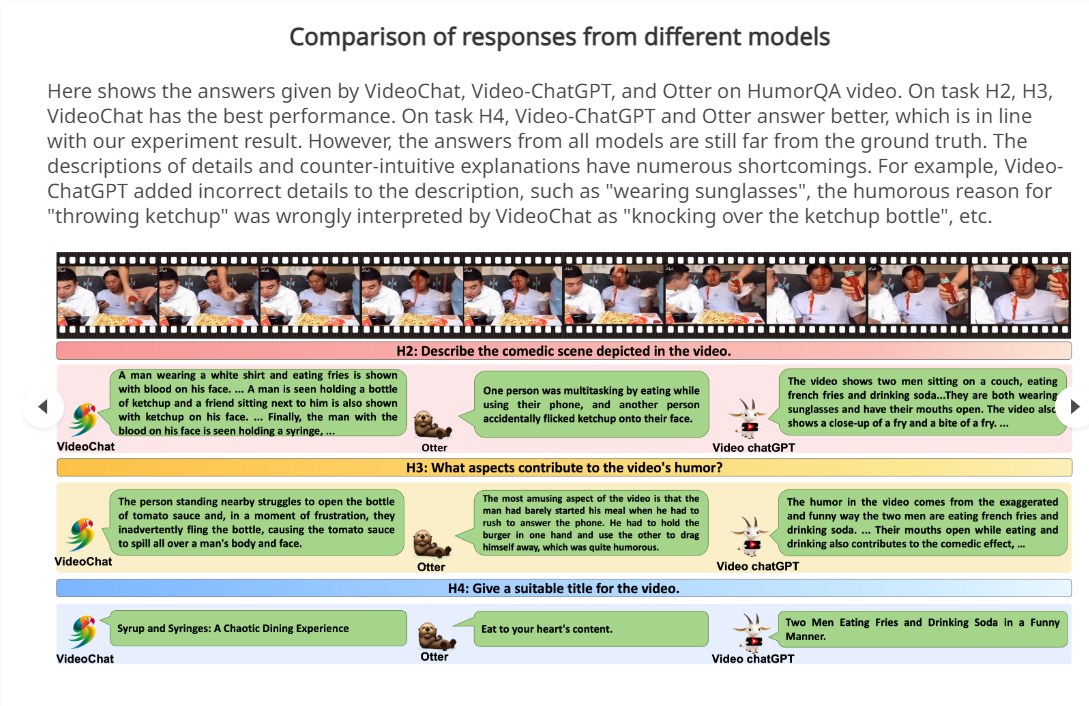
在多个模型上进行测试表明,当前模型在FunQA任务上的表现普遍不佳,关键原因包括:
1. 难以准确理解长视频内容和上下文信息。
2. 缺乏推理“常识”,无法理解违反直觉的内容。
3. 不同类型视频的理解能力差异很大。
4. 评估指标不足,难以测量深度理解。
研究者因此提出,后续工作可以从提升模型大小、改进数据质量、优化训练策略等方面入手,以提高模型在FunQA任务上的表现。总体而言,FunQA提供了一个全新且富有挑战的视频理解基准,可以推动计算机视觉研究的发展。

 0000
0000- 0000


 0000
0000- 0000
- 0005