蚂蚁集团开 “卷” 金融大模型,“四力和一” 解决产业真命题
大模型最让人印象深刻的是它们的「涌现」行为,数以万计的二进制计算决策融合成一种仿佛人类的理解力和创造力,让金融行业看到开发一个专注金融的语言大模型的巨大价值。
近半年时间,素来以新技术最早采用者著称的金融机构以及科技公司纷纷下场:
3月,美国彭博正式发布百亿级语言大模型 BloombergGPT;
5月,度小满推出国内首个千亿级中文金融大模型「轩辕」;
6月,开源金融大模型貔貅(PIXIU) 、聚宝盆(Cornucopia)接踵而至
.....
9月8日,蚂蚁集团在外滩大会上正式发布工业级金融大模型(AntFinGLM) ,同时开放了金融专属任务评测集「Fin-Eval」。
该测试集从五大维度(认知、生成、专业知识、专业逻辑、安全性)28类金融专属任务评估了金融大模型能力,结果大幅超过当前主流通用大模型。在「研判观点提取」、「金融意图理解」、「金融事件推理」任务上,金融大模型已经达到专家平均水平。
巨头做大模型一定会和自己过往的业务深度融合。除了模型层,蚂蚁集团也发布了两个金融大模型的产业应用。
用户端的支小宝(2.0)是国内首个应用大模型技术的智能理财助理。内测近半年,完成备案工作后上线。
产业端的「支小助」(类似金融版 Copilot)也是蚂蚁集团首个基于金融大模的面向产业的生产力工具。
一、金融大模型:屹立在万亿 Token 上的「知识力」
通用大模型缺少金融领域的专业力、知识力、语言力以及安全力,金融大模型实现落地行业是一个复杂化的系统工程,需要将「四力」形成合力。蚂蚁集团金融行业大模型负责人王晓航在发布会上讲到。
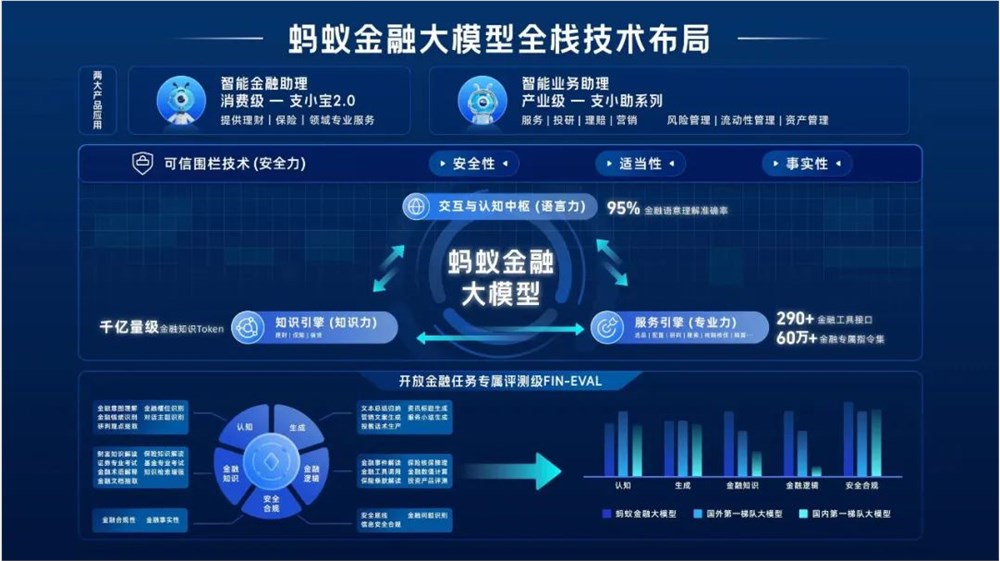
蚂蚁金融大模型具有「四力」,知识力、语言力、专业力和安全力
所谓知识力,主要是指金融大模型的底座能力,模型规模只有足够大(通常百亿以上),才会有「涌现」现象的出现。预训练大模型则需要海量数据。
从目前公开的数据来看,BloombergGPT 的通用数据集包含3454亿个 Token,金融领域数据集由彭博在过去四十年的商业经营中积累而来,共包含3635亿个 Token。
国内金融大模型「轩辕」(2.0)使用了自身业务中积累的金融领域的13B(130亿) Token。恒生电子 Light-GPT 利用了超过4000亿个 Token 的金融领域数据。
蚂蚁金融大模型,在万亿量级 Token 通用语料基础上,注入了千亿量级 Token 金融知识 —— 包括全网公开的金融行业语料约5000亿 Token 以及蚂蚁独家金融语料约279亿 Token,行业领先。
就国内数据市场而言,我国政府数据资源占全国数据资源比重超过3/4,但开放规模不足美国的10%,个人和企业可资利用的规模更是不及美国的7%。在此背景下,具有私域属性的行业数据的重要性就更为凸显。蚂蚁有着多年保险、理财、信贷平台经验,在金融大模型布局上拥有先天优势。
「小模型时代,蚂蚁就积累了深厚的数据资产和产业 AI 的 know-how。」蚂蚁集团金融行业大模型负责人王晓航在大会上讲到,他也多次提到了蚂蚁的金融知识工程。
如果说大模型是一个参数化的知识力容器,那么,知识图谱就是另一种基于符号机制的知识力容器。对蚂蚁金融大模型来说,两种知识力形成互补,缺一不可,金融知识图谱能够指导大模型对金融行业进行正确精准的认知,提高其理解、推理决策的能力。
过去几年,蚂蚁的金融科技团队在金融知识工程上做了大量投入。例如,支小宝团队基于一些研报、新闻、大 V 资讯以及高质量权威合作数据源和数据库,通过合作的一些业务专家和策略专家,对于领域专业知识进行了提炼和萃取,形成了一个标准化基础知识层。算法工程师在此基础上做了一些领域知识的关联和整合,尝试建构金融现象之间的因果逻辑,构建形成匹配金融专业要求的知识图谱、资产图谱和事理图谱等机器可读可用的数字资产。
以支小宝(2.0)为例,背后注入了金融资讯和百科420万 ,金融图谱覆盖保险3000 险种 /2万 常规药 /7000 常见病和几十种就医方式等万级实体和50万 关系,金融行业 / 板块 / 机构 / 产品 / 管理人 / 资讯等200万 实体和1100万 关系,金融数据、公开信息和条款存储量达到亿级。
不过,高质量数据集和知识图谱还只是金融大模型的「知识力」来源,大模型的业务「能力」离不开蚂蚁「从300 真实产业场景中提取了共60万 高质量指令数据」(貔貅 PIXIU 指令集为13.6万)。
金融大模型包括三个部分:上游是预训练语言模型;下游是针对通用任务或特定任务的微调。最后要与人类对齐,基于人类反馈进行强化学习。当我们用足够多的高质量指令集对它进行微调后,大模型才能很好地胜任金融任务,包括从未见过的任务。
当谈到与金融大模型相伴的数据安全与隐私问题时,金融大模型智能算法负责人陈鸿告诉我们,用户的隐私数据在语料当中会被全部清洗掉,避免用户个人信息或者任何能识别出可联想身份的信息进入大模型的训练环节,对大模型来讲,它里面不会压入任何用户的私人数据。
安全部分,我们也做得比较严格。他强调说,不止是训练数据从入库起的每一个环节都会做清洗和过滤,我们还做了对抗样本的技术去训练模型识别这些有害内容,有害内容拦截率现在已经到99% 以上。
二、出色的「语言力」,巴菲特为什么减持比亚迪?
金融大模型一定要有「语言力」,作为认知和交互的「中枢」,不仅要对用户的金融情感、金融意图,明察秋毫,还要善于总结归纳行业资讯,推理分析行业事件。
金融情绪有自己的特定属性。比如一些特定行情事件发生后,对于持有一些风险资产的人来说,这是个好消息,他可能会很兴奋。但对于一些持有债券、黄金资产的人来说,反而是个坏消息,不会很开心。
金融大模型有一个很重要的涌现能力 In-Context Learning,给到几个例子,不需要调整模型参数,它就能够很好地胜任这些情绪识别任务。蚂蚁金融大模型的情绪识别准确率已经超过90%。

过去做金融意图识别,让器听懂用户要什么,难度很大。
理财对话往往具有很强的时序、连续性和历史性,用户提问「招商银行怎么样?」,很可能在此之前已经讨论过相关内容。要想听懂用户要求,机器还得有一副好记性,还要能理解上下文。
如果遇到「我要 A、B、C 这三个基金,不要 D、E、F」这样的诉求,机器还得具备逻辑能力,否则只会一股脑儿地将用户提及的六只基金全抛给对方。但是给机器引入逻辑符号也是一件比较困难的事情。
现在,用足够多的高质量指令集进行微调后,蚂蚁金融大模型已经掌握金融意图的识别,识别准确率达到95%,达到了专家平均水平。即使从未见过的任务,也能胜任。
最有意思的是蚂蚁金融大模型甚至可以像投研专家一样解读行业事件。比如,「巴菲特为什么减持比亚迪?」
它会先从巴菲特的投资哲学、注重什么样的策略开始,然后分析他在投资界的影响力、比亚迪的业务、过去几年的财务状况等,接着分析巴菲特买入 / 卖出的时点、价格、原因。历经二十多个推理环节,最后输出它的解读:「减持原因可能是基于对股票价格与内在价值的判断和风险管理的考虑」,并做出详细解释。
传统方法难以数学建模的这么复杂的分析过程。现在,蚂蚁通过「仿金融专家多智能体协同推理」机制,实现了媲美人类投研专家的水平。
大模型其实本来就有「一人分饰 N 角」能力,可以用不同人设 prompt 召唤出它们。采用 AI Agent 的建模思路,蚂蚁让大模型派生出四个工作小组 —— 计划组、执行组、表达组和评价组 —— 执行不同任务,就像将一个大命题分拆成几个小的问题。只要业务有需要,每个小组还可以继续像这样被分拆,派生更多智能体。这些智能体协同作业,如同一个作战集群,可以快速跑出答案,给到用户。
当然,这里需要补充解释什么是「专家平均水平」?金融数据的标注需要专业人员来做。在蚂蚁集团,通常是两个专业人员打标,第三个人(专家)负责核实 ground truth(比如某个内容到底是不是合规)。蚂蚁金融大模型在某些任务上的识别精度已经达到这样的专家水平,高于负责打标的专业人员的平均水平。
三、「专业力」:调用工具,给你选基
所谓专业力,其实是指大模型调用蚂蚁的「存货」工具,完成复杂金融任务的能力。
除了意图识别,蚂蚁金融大模型有工具理解能力。你用自然语言讲清楚它做什么,然后举一些例子,大模型就可以学会将用户意图转换成一系列的 API 调用,完成更加复杂场景下的应用。
蚂蚁长达十年的积累,平台上有完备的数字化金融工具矩阵,蚂蚁金融大模型可通过理解用户语言,精准调用蚂蚁体系内的这些专业工具,给用户提供相应专业服务。理财侧包括理财选品、产品评测、行情解读、资产配置等6大类服务。保险侧包括产品解读、家庭配置、智能核赔、智能理赔等10多个智能服务。

举个栗子。你说「帮我挑一只白酒基金」,大模型会先做一个行业研判(背后调用行业研判的 API)了解白酒行业。接着,它要选择相关的基金(调用条件选基的 API)。金融大模型还会针对用户的个人风险偏好、预期回报,做必要的投教信息输出(投教 API),最后形成一个完整闭环服务:根据用户指令分析相应的基金,将要点信息发给用户,并根据行情给用户一些风险提示。
如果用户后续反馈白酒基金怎么又跌了,金融大模型可能会调用并组合产品研判(API)、图表生成(API)、投教(API)以及持仓诊断(API),给到用户完整的服务。
「这里的核心还是在做 NL2API 的事情,将自然语言翻译为合适的 API 调用。」陈鸿说,大模型有代码生成能力,可以写 Python,SQL,自然也能写 JSON,生成字符串给到下游工具 API。
相比之下,原来的技术做法就很机械,蚂蚁积累多年专业工具无法被逻辑地连贯起来,没有闭环,用户很容易「逸出」预设的逻辑,很难获得想要的服务。
当然,蚂蚁金融大模型给到的这种专业服务,不只是调用某个工具,而是这些工具的有效组合,牵涉到推理、规划能力 —— 它知道如何将这些工具组合起来,如何将不同工具的输出整合起来,变成一个完成、连贯的回答,给到用户。
这就不得不提到大模型的思维链能力。对于这类通常由多个步骤构成的复杂任务(比如数学竞赛、写代码、生成脚本),当大模型大到一定临界点时,就会涌现出思维链能能力,过去基本不能解决的问题,变得能够胜任。思维链就像做「因式分解」,把一个复杂的推理问题进行拆解,逐步解决,自然也就更容易得到高质量答案。
现在训练大语言模型的企业和机构很多,但能够训练出思维链并应用的很少。保险核赔自动化可以很好展现蚂蚁金融大模型的思维链能力。
比如,重疾险的赔付往往需要上传许多发票、病例等资料,系统识别后还需人工判断这些材料是否构成一个完整的核赔证据链。蚂蚁金融大模型通过做思维链推理就能自动判断证据链是否闭合,核赔决策准确率达到98%。过去依靠人工核赔最快也要1-2天,现在仅需几秒。
四、回避不了的「安全力」
「安全力」几乎时所有围绕大模型的讨论无法回避的主题,特别是在金融这样的强监管领域,如何让通用大模型这样一个率性不羁的创作者懂得西装白领世界的中规中矩?
从第一天开始,我们就是奔着工业化上线的目的去做,所以蚂蚁金融大模型的安全力功课做得比较细致。王晓航在大会后接受记者采访时谈道。

与主流通用大模型相比,蚂蚁金融大模型有更强的生成内容安全的能力,主要包括三个方面。除了和通用大模型一样要与社会价值观对齐,金融行业内容生成还要遵循更严苛的金融合规要求。比如,不能有强观点、不能直接去推荐买或者推荐卖、预测涨跌等等。
蚂蚁金融大模型采用了一个关键技术 RLHF。RLHF 使大模型基于巨量数据进行持续反馈与强化学习,更好掌握人类的偏好,结果更符合人类预期,比如风险规避水平、投资习惯,当然也包括安全合规。
「我们也用 RLHF 让大模型对齐这些业务上比较复杂的适当性要求,然后也用后置校验的方式去保障这个底线。」陈鸿解释说。
针对大模型最后输出,会用到 Reward model,它是强化学习中的一个核心概念,可以用来评价 Agent 的一次行动的奖励是多少,并以此为信号指导 Agent 的学习。比如,通过给输出打分,看看是否安全合规,利用打出的 Reward 对生成模型进行迭代。
「合规要求都非常细,我们都是跟业务对出来的,然后也经过 RLHF,和人类去对齐这些标准,所以,合规水位会比通用模型要高。」陈鸿说,在线上实际运行的时候还会有例行的巡检,对各种意外的情况做毫秒级的安全拦截。
第三,金融事实是高度动态的,尤其是一些行情数据(比如收盘价、基金涨跌幅度),我们会通过一些工具,比如检索外部实时更新的金融数据库去确保事实准确性,要求也会比通用大模型更高。
针对大模型的幻觉问题,在大规模产业级应用里(比如核赔),蚂蚁采用了大模型与知识图谱相结合的双轮驱动,确保生成内容的专业和严谨。此外,蚂蚁还让大模型生成思维链,一步一步展开思考过程,用概率图模型来检验这些推理链条的置信度,确保事实性幻觉问题的大幅下降。
蚂蚁集团首席技术官、平台技术事业群总裁何征宇在大会上表示,建设大模型安全能力也是未来蚂蚁持续探索和精进大模型的五大能力方向之一。
五、「四力合一」的上与下:底层支持与产业应用
强大底层算力设施为蚂蚁金融大模型提供了一个好的基础和起点。
之前 AI 应用里,很多训练的任务都是单卡或单机就能完成,但在大模型时代,需要千卡、万卡来完成一个任务。这就需要构建智算集群,能够支持万卡级别的高速互联,并且支持各种异构算力,包括 CPU、GPU 等算力的高速互联。
蚂蚁金融大模型走纯自研的技术路线,全栈布局,在底层基础设施方面,目前已建成万卡 AI 集群,为大模型落地应用提供有力支撑。
不过,高性能 GPU 卡多了,在现有工程条件下保证大量的卡的长时间稳定运行,极有挑战性。因为中间容易出现各种状况,导致重启,拉低训练效率。蚂蚁也历经了许多试错,目前千卡规模训练 MFU 业界平均水平约50% 左右。蚂蚁的千卡规模训练 MFU 可达到40%。另外,集群有效训练时长占比90% 以上。
值得注意的是,蚂蚁金融大模型是直接面向生产的工业级大模型,因此也做了很多推理上的工作。比如,提升系统每秒吐出的 Token 数量。
ChatGPT 推理输出时,都是一个字一个字地出,等它把最后一个字出完了,机器才能执行。系统反应完成大概需要十几秒,在真实应用场景下,这种体验会很差。
目前,蚂蚁金融大模型的「RLHF 训练在同等模型效果下,训练吞吐性能相较于业界方案提升3.59倍,推理性能相较于业界方案提升~2倍,处于业界先进水平。」
离开底层再往上看,金融大模型能否与应用场景结合,解决产业真问题,一直是蚂蚁的关注点。王晓航在大会上表示,销售、服务、风险管理、投研、理赔等,金融业务链条上每一个关键职能,「都值得用大模型技术重做一次。」
具体到消费端,支小宝(2.0)完成从检索式 AI 飞跃到生成式 AI,服务水平趋近于专家水平,能帮助用户深度解读市场信息、并结合用户的财务目标、投资偏好等,提供个性化的配置策略。
这里需要补充一点 —— 支小宝的「情商」也有显著提升。理财市场朝着权益净值化方向发展,更好更专业的陪伴也成为一种必然趋势。陪伴小白用户更理性持有理财产品,「情商」不可或缺。
支小宝(2.0)在回答用户提问后,还会自动「反思」回答准确度,进行自我纠偏。
这种「自省」,主要是指判断自己给到的答案是不是可信。陈鸿解释说。比如,客户问白酒为什么涨,第一步可能是理解他想问什么,接下来可能要调取相应的服务和工具去生成相应回应,最后还会评价自己刚才的生成的结果到底有多可靠。
它知道自己这句话的置信度,然后决定要不要「认怂」,这在小模型时代是很难做到的。
除了支小宝(2.0),蚂蚁也首次推出了面向产业的金融版 Copilot——「支小助1.0」,包含「服务专家版」、「投研专家版」、「理赔专家版」、「保险研判专家版」等六个版本。
以保险行业为例。因为条款、专业术语很多,保险行业招募培训保险代理人员的成本居高不下,核赔等后端服务也是人力密集,人们常说理赔才是服务开始,成本居高不下。
现在,「服务专家版」「支小助1.0」可以为销售提供个性化的话术培训。拥有思维链能力(以及多模态能力)的理赔专家版「支小助1.0」大幅提升了核赔自动化水平:
它不仅将复杂单据的整案提取准确率由80% 提升到98%,也让核赔决策在98% 准确率的前提下,覆盖率从40% 提升至70%,让门诊险理赔和30% 以上的住院医疗险理赔能够完全自动化。
保险研判专家版「支小助1.0」研判观点提取不仅比主流通用模型优秀,甚至超过专家平均水平。
投研版「支小助1.0」对每日事件实现媲美人类专家平均水平的主观分析与决策,将事件解读效率从每周10篇提升到每日400 ,还能帮忙生成金融工程代码。
通用大模型无法在专业严谨的领域直接对外商用,只有走向垂直行业大模型,才能带来产业价值。蚂蚁探索出了一条路:
以行业大模型为认知和交互的中枢,调用领域知识和专业服务,这是一个「大模型 知识 服务」驱动的架构,为消费者和产业应用,提供「四力」的支撑。
不过,金融行业本质是一个关于数字、逻辑、复杂决策的领域,初出茅庐的金融大模型的局限性和它的优点一样明显:对金融长文本的理解能力很差、缺乏数量推理能力和否定判定与生成能力,等等。
金融大模型产业化应用的征程才刚刚开始,选择在外滩发布或许也有这样一种意味:
一个世纪之前,这里中国第一辆汽车上路的地方。从这里出发,科技助力人类越走越远,从上海走向全中国、走向世界,上天入地、一步步走向日常生活……
- 0000
- 0000
- 0000
- 0000
- 0003