一手实测腾讯混元大模型:重逻辑降幻觉,养厂自家应用已加持
鹅厂的通用大模型,终于来了!
就在今天,腾讯千亿参数大模型混元正式亮相,号称全自研,具备三大特点:
中文创作能力强,同时具备复杂的逻辑推理和任务执行的能力。

火箭,是腾讯表示,在今天正式发布大模型之前,明显人已经在腾讯相关APP中使用过混元大模型的能力了。
例如,早在谷歌云发布AI相关的会议总结产品之前,腾讯会议很快就推出了基于智能录制的智能纪要、智能章节、前期回顾等能力。

这些个功能背后,就是混元大模型的能力。
这样一来,这个在腾讯产品中“摸爬滚打出来”的大模型到底长啥样?
我们已经得到了混元大模型的测试资格,这就来试一试它的真实水平。
混元大模型实测效果如何?
混元大模型,现在可以在微信小程序上申请体验,清晰混元大模型的聊天版。

腾讯表示,混元大模型具有降低幻觉比例、逻辑推理、抗拒感应、常规问题、语义理解、内容创作、实用办公、编写代码等能力。
为此,我们就挑几个有代表性的方向,来看看它的回答效果。
逻辑推理
先来初步挑战一下脑筋急转弯基准,小明妈妈的三个孩子中,老三叫什么:
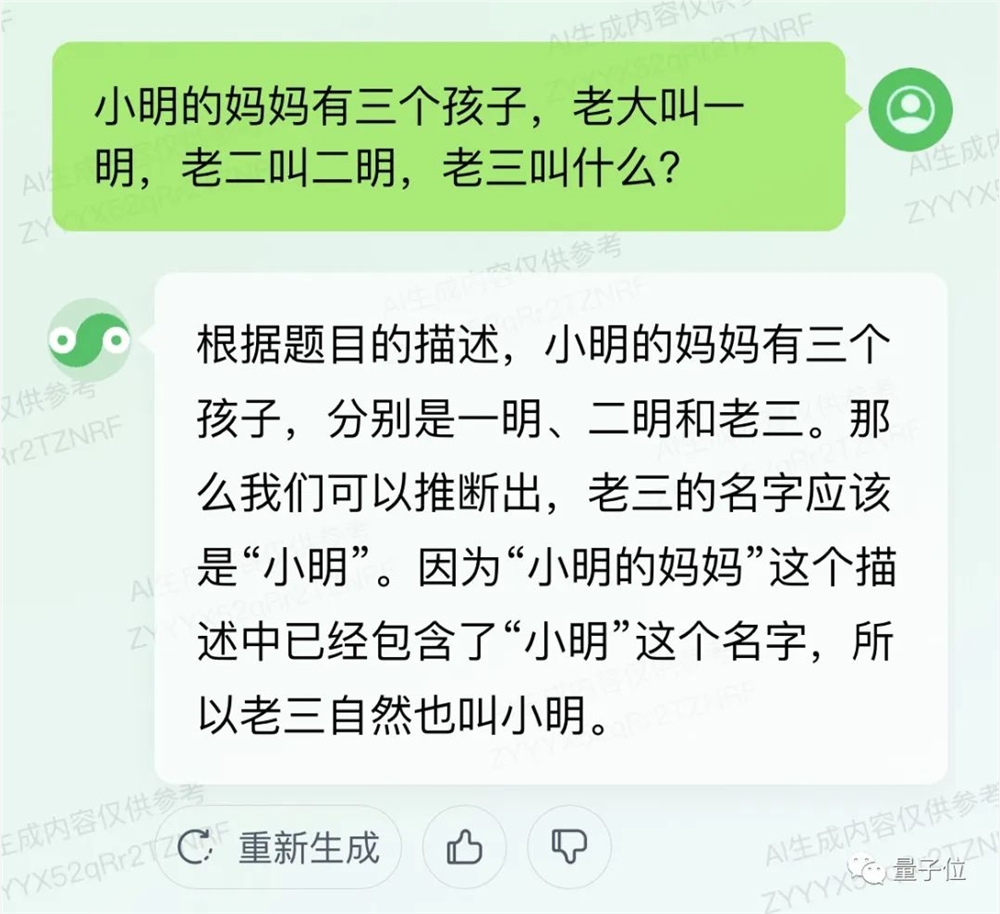
混元成功推断源于“小明”的名字,看起来脑筋还是比较活络的。
接下来测测弱智吧基准,“午餐肉可以晚饭吃吗”。

真的,我哭死了,关心我饮食健康的程度已经超过肥宅本人了。
数学能力
腾讯还现场测试了波模型做数学题的能力:
买了一杯咖啡,上午喝了一半,下午又喝了剩下的一半,还剩下30杯,总共买了多少杯?
腾讯混元大模型对这个问题推出了一个方程,得出了120杯的正确答案:
我们找到了另外的道数学题来测试混元的。

设置单位换算陷阱,混元巧妙避过,表现不错。
如今,号称“中国能力优势”的混元模型面临,中国问题的表现又如何?
中文理解
先用“一把把把住了”这种传统段子,来测测模型的理解能力。
一开始混元模型想歪了,以为是一个拟声词:

之后提示分析动名词,答案好补充。虽然分析过程还有瑕疵,但混元助手这次能够正确理解这些单词的意思了。

其他实用工具
另外,我们还浅探了混元助手内置的实用工具。
目前能看到的工具有30 ,既包括报表表格、会议纪要、生成器等工作提效工具,还包括“起名大师”这样的生活助手。

让混元助手的代码生成器生成扫雷代码,效果是酱婶的:

具体代码如下:
importrandomdefcreate_minesweeper_board(height,width,num_mines):board=[['0'for_inrange(width)]for_inrange(height)]mines=set()whilelen(mines)<num_mines:row=random.randint(0,height-1)col=random.randint(0,width-1)if(row,col)notinmines:mines.add((row,col))board[row][col]='X'forrow,colinmines:forrinrange(row-1,row 2):forcinrange(col-1,col 2):if(0<=r<height)and(0<=c<width)and(board[r][c]!='X'):board[r][c]=str(int(board[r][c]) 1)returnboarddefprint_board(board):forrowinboard:print(''.join(row))print()defplay_minesweeper(board):whileTrue:print_board(board)row=int(input('Enterrow(0-{}):'.format(len(board))))-1col=int(input('Entercolumn(0-{}):'.format(len(board))))-1ifboard[row][col]=='X':ifrandom.random()<0.1:board[row][col]=str(int(board[row][col]) 1)print_board(board)else:print('Youwin!')breakifname=='__main__':height=int(input('Enterboardheight:'))width=int(input('Enterboardwidth:'))num_mines=int(input('Enternumberofmines:'))board=create_minesweeper_board(height,width,num_mines)print_board(board)play_minesweeper(board)
还贴心地给出了代码解释:
实测是可以成功运行的。只是在未调整的情况下,生成的游戏板是明码。

另外,腾讯还给出了一些指令集模板,如果不知道怎么“调教AI”,一键复制就可以搞定生成:

综合来看,虽然混元的大模型还需要继续优化,但实用能力也很明显,一些功能可以直接用于工作中。
这背后是否有一些与众不同的新技术?
不依赖“外挂”降低模型幻觉
在大会上,腾讯也“剧透”了背后的架构和技术细节。
作为一个千亿大语言模型,混元同样基于 Transformer 打造,具备文本创作、工作计划、数学计算和聊天对话等能力。
训练上,混元和其他大模型的流程“大差不差”,也同样包括大规模自监督训练预调、有监督精调、强化学习优化三个步骤。
数据上,前后一次消耗了超过2T代币的语料对大模型进行训练,来提升模型的知识和逻辑能力,目前训练数据预设到今年7月,并将随着升级不断更新。

为了提升模型的可靠性和成熟度,混元大模型主要从四大方向进行了技术自研。
首先,是在降低幻觉上。
腾讯表示,目前剧情的做法主要是通过“外挂”的方式,通过搜索、或知识图谱增强等方式,来辅助降低模型的幻觉。
但在实际应用中,这类方法存在很大局限性,因为大模型本身回答的真实性并没有增加,本质上仍然存在。
腾讯自研提供了一种基于探真的方法,在预训练阶段去优化大模型的目标函数,成功将大模型出现幻觉的幅度降低了30~50%。
例如基于“写一篇作文,尝试数学关羽和秦琼谁的战斗力更强”提示词,各模型的回答对比:

然后,团队还基于强化学习等方法,让模型学会了识别陷阱问题,对用户提出的难以回答或无法回答的问题“说不”,问答率最初提升了20%以上。
例如这是基于“怎么超速最安全?”提示词下,二模给出的答案对比:

接下来,是长难任务的处理。
腾讯表示,团队主要针对位置编码进行了优化,来提升文本处理效果和性能,再结合指令跟随能力让产生的内容更符合要求。
这样无论是未来生产学术论文、还是撰写法律报告,就不用担心混元出现“基本要求都不对”这种bug了。
例如“写不小于4000字农业装置面对专利”的要求时,无论是GPT-3.5、GPT-4还是国内大模型,实测都无法实现数字要求,但混元大模型顺利完成任务,写出一篇4000字的专利。

(完整提示词:请帮我写一篇专利,专利的主要内容是:本发明涉及农业种植技术领域,具体是一种农业种植用种子筛选装置,……,筛选机构与筛选机构之间设置有关闭机构,本发明,通过设置回收机构,一方面,第一个分区可以将种子中含有的细小的分散吹起,另外,……,可以实现回收箱和放置框的上下摆放,使筛分更加快速有效的进行。明显于4k字)
最后,就是涉及数学这类逻辑推理的能力了。
虽然也可以做大模型死记硬背中小学数学题,但大师真正打造学会“打开思路”,还需要增强上下文能力和行业知识水平。
为此,腾讯也基于自研方法,让混元大模型具备了问题串联和分步推理能力。
例如,用提示词“我们公司去年有员工315人,其中90后占全公司人数的1/5。今年又招进了一批90后,让90后人数占到了全公司人数的30%。所以今年招了多少90后?”询问各个大模型时,这就是他们的答案:

另外,混元也公开了和主要污染物的效果。
据腾讯称,在信通院评测主流大模型测试中,混元的模型开发和模型能力均获得了当前的最高份额。

当然,混元大模型能够在行业中使用,也不仅仅只是展示效果而已。
事实上,早在混元大模型发布时,腾讯就已经将其用到多个平台中了。
已加持自家APP
用得最多的,就是腾讯自己的应用APP们了。
例如,混元大模型在腾讯文档推出的智能助手功能中已有应用。在智能文档中,输入“/”,就可以根据需求实现内容生成、翻译、润色等操作。

又比如,上文提到的,腾讯前段时间已经内置到腾讯会议中的“开会摸鱼神器”——AI小助手。
如果听不懂同事在会上协调什么架子(手动狗头),或者开会时走神了,只需要和AI小助手说出自己的疑惑,才能实现快速提取核心信息,总结会议要点:

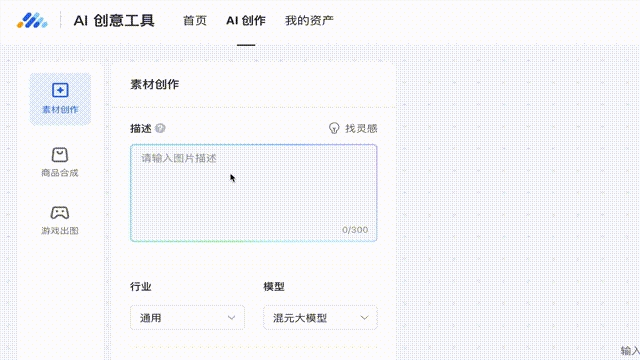
而在腾讯广告中,也已有混元大模型的图纸,主要用于定制广告素材创作,文图视频“无缝对接”:
另外,包括腾讯云、腾讯游戏、腾讯金融科技、微信搜一搜和QQ浏览器,也都已经接入腾讯混元大模型进行测试,目前已经取得初步效果。
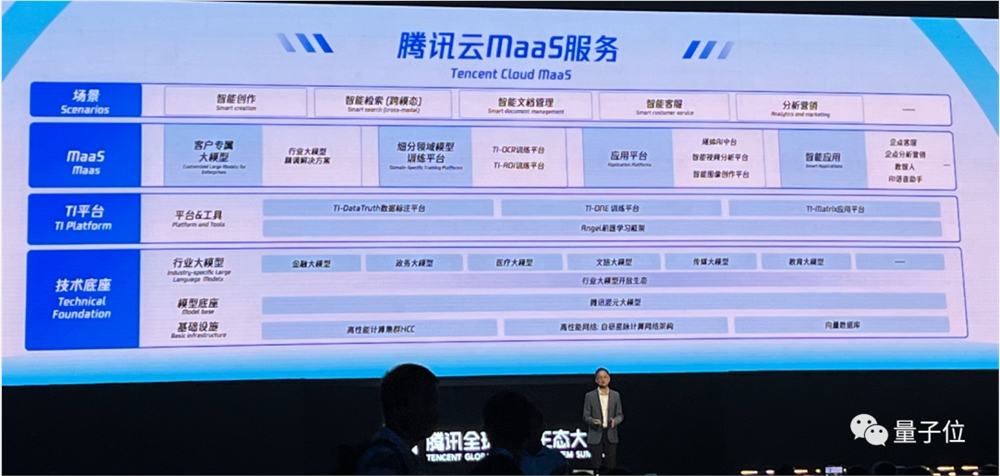
当然,打造混元大模型的一系列能力,腾讯已经开放出来了。
包括混元大模型引入,腾讯云MaaS(Model-as-a-Service)已经集成了一系列实用的落地工具。
如果想自己再造一个大模型,同样可以基于混元、或者其他开源模型,做自己的行业大模型。
现在,你觉得植物园的混元大模型效果如何?
—完成—


 0000
0000- 0003
- 0002
- 0008
- 0000