YaRN:可高效扩展现有大模型的上下文窗口长度
要点:
1、YaRN是一种计算高效的方法,可以扩展基于 transformer 的语言模型的上下文窗口,与以前的方法相比,它需要10倍更少的 token 和2.5倍更少的训练步骤。
2、YaRN利用了旋转位置嵌入(RoPE)来增强模型处理顺序数据和获取位置信息的能力,同时通过压缩变压器来扩展上下文窗口。
3、实验表明,YaRN只需要400个训练步骤就能成功实现语言模型的上下文窗口扩展,相比之前的方法降低了10倍的训练样本量和2.5倍的训练步骤。
大型语言模型在自然语言处理任务上的强大表现主要归功于模型所能捕捉的上下文信息。
Rotary position embedding(RoPE)增强了模型处理顺序数据和捕获序列中位置信息的能力。然而,这些模型必须超越它们所训练的序列长度进行泛化。
Nous Research、Eleuther AI和日内瓦大学的研究人员提出了YaRN (又一个RoPE扩展方法),该方法可以高效地扩展现有语言模型的上下文窗口长度。
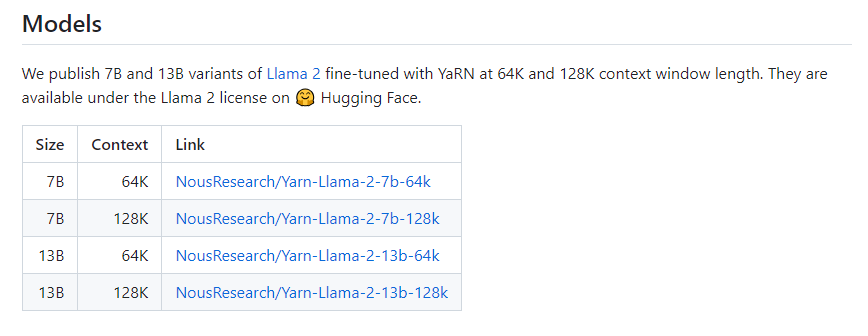
项目地址:https://github.com/jquesnelle/yarn
RoPE使用复杂数旋转,这是一种有效的编码位置信息的旋转式位置嵌入,使模型能够在不依赖固定的定位嵌入的情况下有效地编码位置信息。这将帮助模型更准确地捕捉长期依赖关系。控制旋转参数是在模型的训练过程中学习的。模型可以自适应地调整旋转以最好地捕捉标记之间的位置关系。
他们采用的方法是压缩变换器,它使用外部记忆机制来扩展上下文窗口。它们从外部存储库中存储和检索信息,使其能够访问超出其标准窗口大小的范围。已经开发了将记忆组件添加到转换器架构的扩展,使模型能够保留和利用来自过去标记或示例的信息。
他们的实验表明,YaRN成功地实现了具有仅400个训练步骤的LLMs的上下文窗口扩展,这是原始预训练语料库的0.1%,比25减少了10倍,比7减少了2.5倍的训练步骤。这使得它在没有任何额外推理成本的情况下高度计算高效。
总的来说,YaRN改进了所有现有的RoPE插值方法,并以无缺点和最小的实施努力替换PI。微调的模型在多个基准上保持了其原有的能力,同时能够关注非常大的上下文范围。未来的研究工作可以涉及内存增强,这可以与传统的自然语言处理模型结合使用。基于变换器的模型可以结合外部记忆库来存储与上下文相关的信息,用于下游任务如问答或机器翻译。
- 0000

 0000
0000- 0000
- 0003

 0001
0001