免费科研利器!Meta祭出Nougat,PDF格式转换,公式表格精准识别,扫描版文档也可以
做研究的童鞋们简直要狂喜!
近来,Meta AI研究人员推出一款OCR神器Nougat,能够分分钟把PDF转换为MultiMarkdown。
各种复杂数学公式、表格、文字、甚至是扫描版的PDF通通可以提取出来。
真有这么神?不如上图说话。
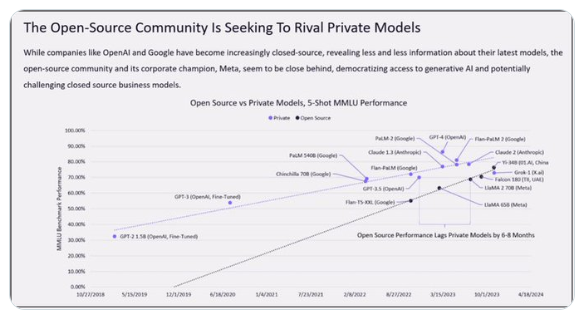
拿出一本很有年代感的书籍,每个公示都可以清晰地识别。


即便文档凹凸不平,也不碍事,公示格式照样重现。

还有PDF中的表格,也能原模原样搬过来。
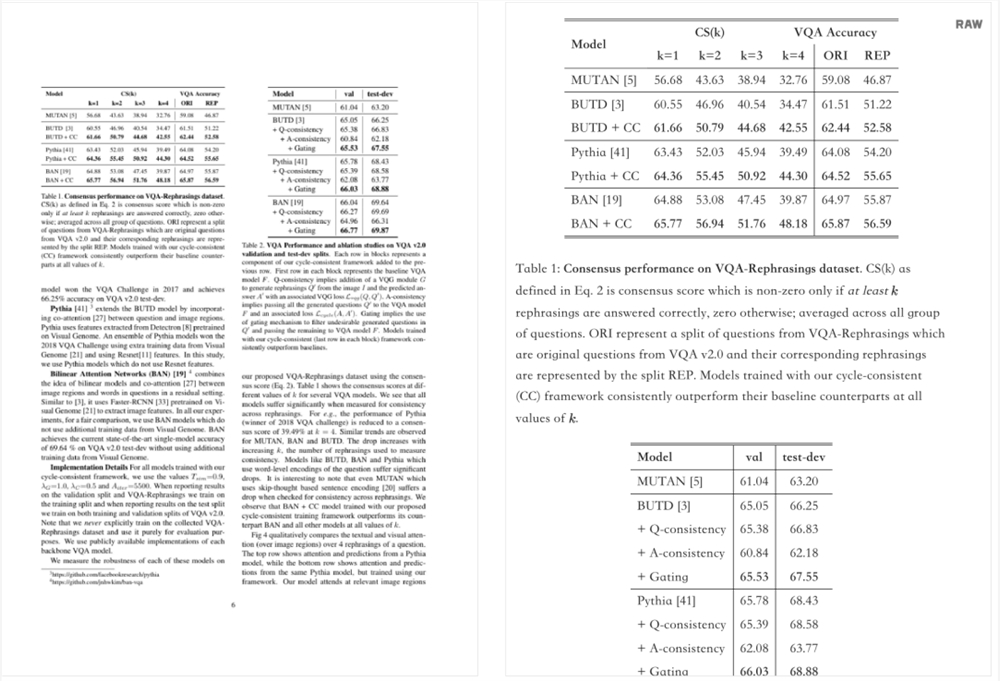
不过有柱状图的文档,Nougat暂时还不能呈现。
这么神的科研利器,究竟是什么来头?
科研OCR神器,怎么来?
要知道,除了HTML之外,PDF是互联网上第二大重要的数据格式,访问量占比为2.4%。
然而,对于科研人员最不便的是,存储在这些文件中的信息很难提取为任何其他格式。
对于高度专业化的文档更是如此,例如科学研究论文中数学表达式的语义信息会丢失。
对此,Meta的研究人员基于Vision Transformer架构,为处理科学文档量身订制定制了一款光学字符识别(OCR)——Nougat。
与传统OCR不同之处在于,Nougat可以处理整个页面,并且输出格式是MultiMarkdown,适合于学术文档写作。
尤其重要的是,它在处理数学公式中的上标和下标等变得非常容易。

论文地址:https://arxiv.org/pdf/2308.13418.pdf
具体来说,Nougat是一个编码器-解码器的Transformer架构,允许端到端的训练,主要建立在Donut架构之上。
这一模型不需要任何OCR相关的输入或模块,文本由网络隐式识别。
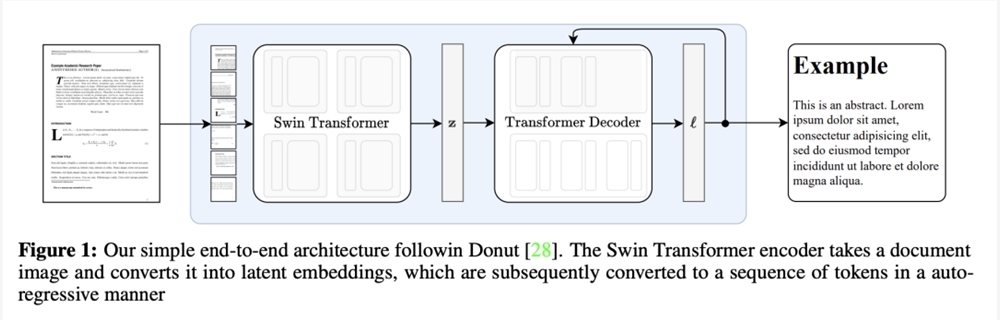
编码器
视觉编码器接收文档图像
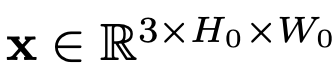
,裁剪边距并调整图像大小,以适合大小(H,W)的固定矩形。
如果图像小于矩形,则会添加额外的填充,以确保每个图像具有相同的维度。
这里,研究人员使用Swin Transformer Swin,可将图像分割成固定大小的非重叠窗口,并应用一系列自注意力层来聚合这些窗口的信息。
该模型输出一个嵌入补丁

的序列,其中d是潜在维度,N是补丁的数量。
解码器
使用具有交叉注意力的Transformer解码器架构将编码图像z解码为token序列。
token以自回归方式生成,使用自注意力和交叉注意力分别关注输入序列R和编码器输出的不同部分。最后,输出被投影到词汇量v的大小,产生对数
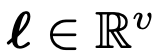
。
数据增强
在图像识别任务中,使用数据增强来提高泛化能力通常是有益的。
由于研究仅使用数字生成的学术研究论文,因此需要采用多种变换来模拟扫描文档的缺陷和可变性。
这些变换包括腐蚀、膨胀、高斯噪声、位图转换、图像压缩、网格畸变和弹性变换。每个都有应用于给定图像的固定概率。这些转换在Albumentations库中实现。

为了训练模型,团队使用了来自arxiv、PubMed Central等平台的科学论文PDF数据集,以及来自作者的相应LaTeX源代码。
这一数据集总共超过800万页组成。
收集到数据后,研究人员进行了数据处理,首先将原文档转换为HTML,然后再转换为Markdown格式。
具体来说,研究人员根据PDF文件中的分页符拆分Markdown文件,并将每个页面栅格化为图像以创建最终的配对数据集。
编译过程中,LaTeX 编译器会自动确定PDF文件的分页符。
实验结果
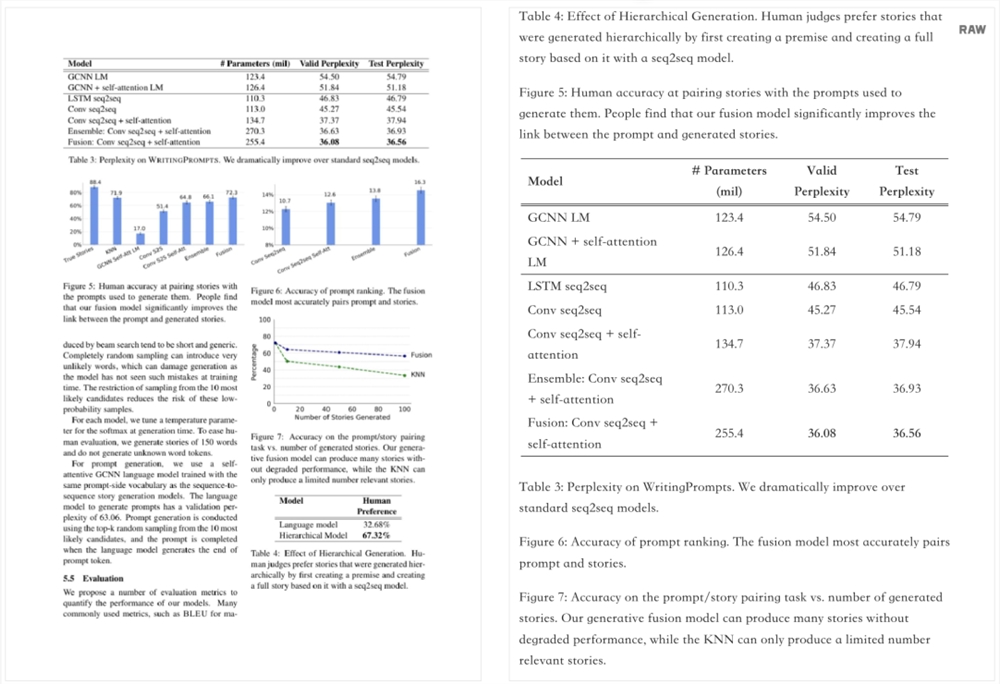
测试中,Nougat从科学论文中提取文本、公式和表格的准确率很高。

对于连续文本,它在BLEU分数超过91%,准确率超过96%。
公式和表格的性能较低,略高于75%,但仍然比GROBID等替代品可靠得多,后者的数学公式准确率略低于11%。

不过,在管理跨文档一致性和避免生成过程中重复文本循环方面,仍面临一些挑战。

根据实验结果,logits重复检测示例如下:
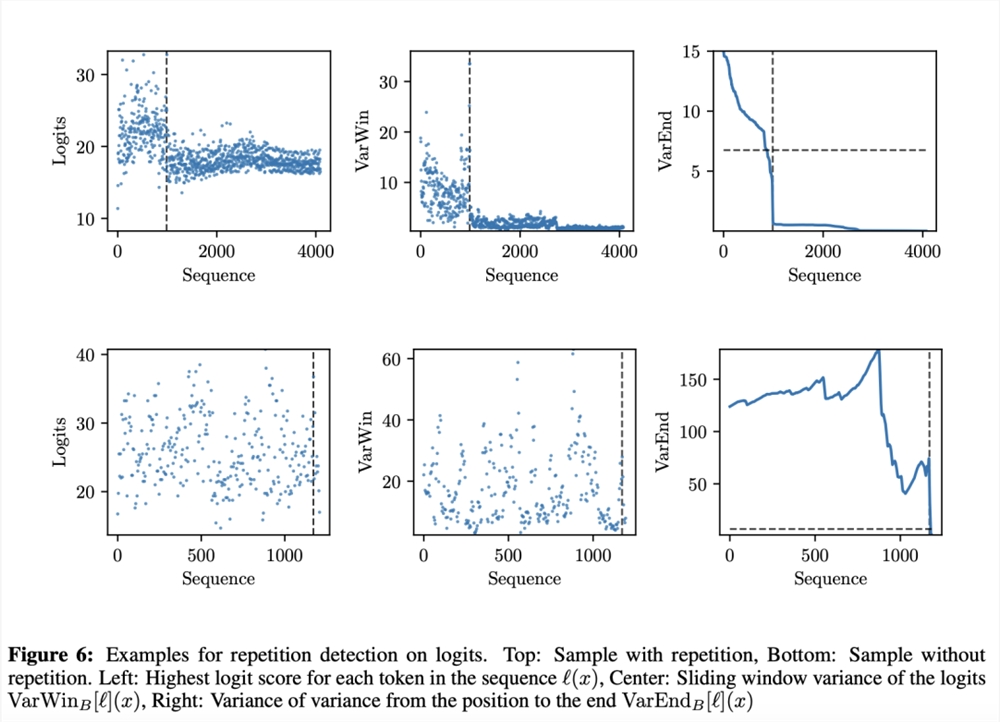
Meta团队表示,Nougat是将PDF研究论文转换为结构化的机器可读文本,从而改善科学知识获取的一种有前途的解决方案。
通过弥合PDF与文本之间的鸿沟,这将使数百万篇科学论文更易于获取。
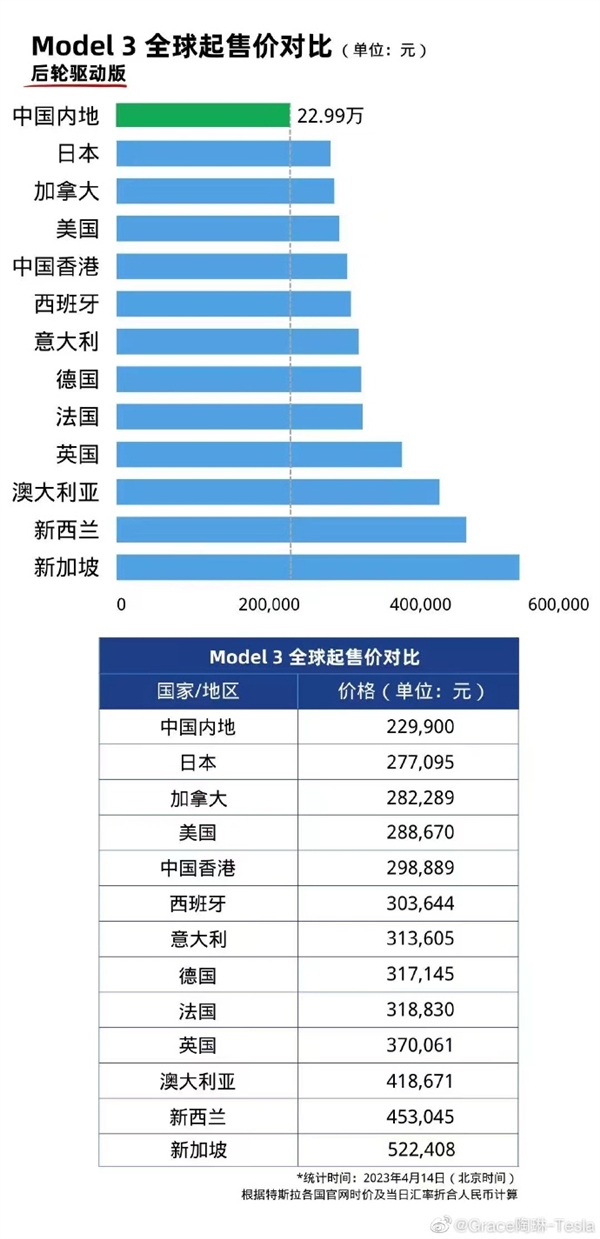
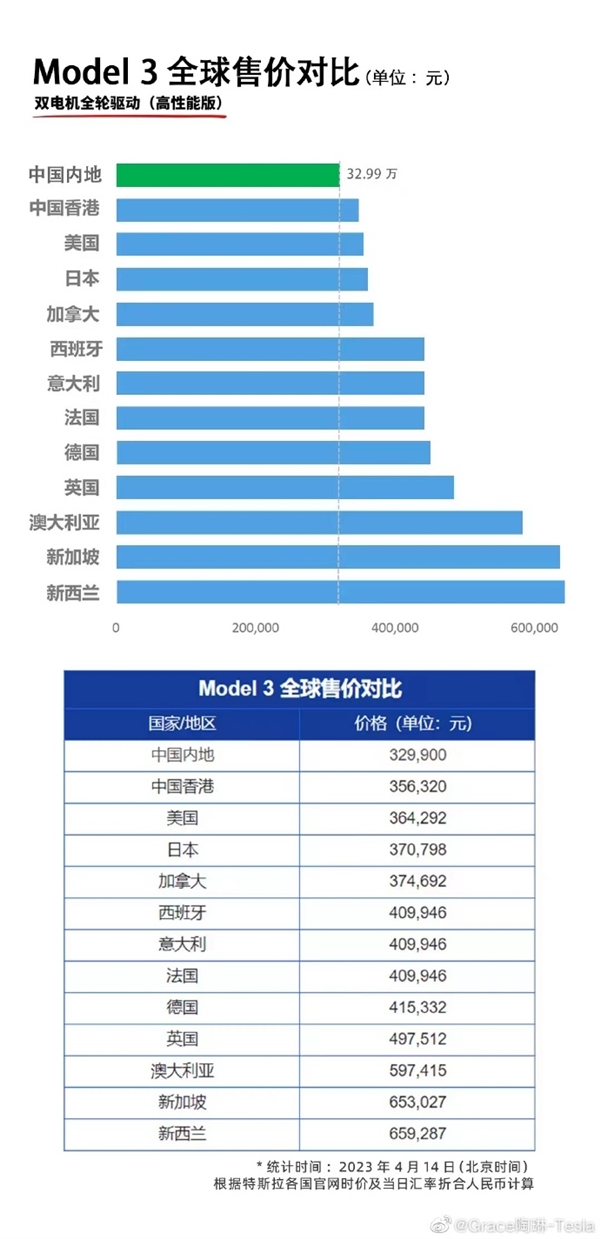 0000
0000- 0000
- 0001
- 0000
- 0000