视觉语言模型BLIVA:让AI更擅长阅读图像中的文本 懂得看路牌和食品包装
文章概要:
1. BLIVA是一种视觉语言模型,擅长读取图像中的文本。
2. BLIVA结合了InstructBLIP的学习查询嵌入和LLaVA的编码修补嵌入。
3. BLIVA在多个数据集上表现优异,可用于识别路牌、食品包装等场景。
BLIVA 是一种视觉语言模型,擅长读取图像中的文本,使其在许多行业的现实场景和应用中发挥作用。
加州大学圣地亚哥分校的研究人员开发了 BLIVA,这是一种视觉语言模型,旨在更好地处理包含文本的图像。视觉语言模型 (VLM) 通过合并视觉理解功能来扩展大型语言模型 (LLM),以回答有关图像的问题。
这种多模态模型在开放式视觉问答基准方面取得了令人印象深刻的进展。一个例子是 OpenAI 的GPT-4,它的多模式形式可以在用户提示时讨论图像内容,尽管此功能目前仅在“Be my Eyes”应用程序中可用。
然而,当前系统的一个主要限制是处理带有文本的图像的能力,这在现实场景中很常见。
BLIVA 结合了 InstructBLIP 和 LLaVA
视觉语言模型通过合并视觉理解功能来扩展大型语言模型,以回答有关图像的问题。
BLIVA结合了两种互补的视觉嵌入类型。一种是Salesforce InstructBLIP提取的学习查询嵌入,用于关注与文本输入相关的图像区域;另一种是受Microsoft LLaVA启发提取的编码修补嵌入,直接从完整图像的原始像素修补中获得。
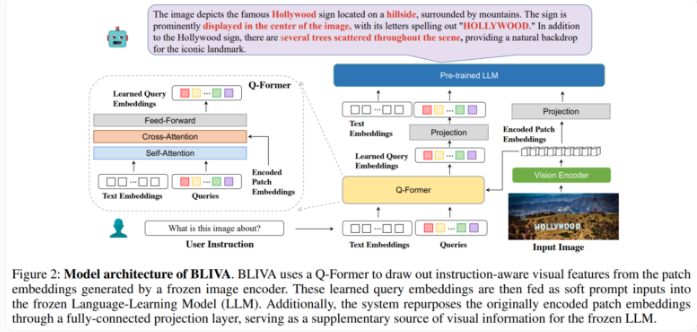
研究人员表示,这种双重方法允许BLIVA同时利用针对文本定制的精炼查询嵌入,以及捕捉更多视觉细节的更丰富的编码修补。
BLIVA 使用大约550,000个图像标题对进行了预训练,并使用150,000个视觉问答示例调整了指令,同时保持视觉编码器和语言模型冻结。
在多个数据集上,BLIVA的表现明显优于InstructBLIP等其他模型。例如,在OCR-VQA数据集上,BLIVA的准确率达到65.38%,而InstructBLIP只有47.62%。

研究人员认为这证明了多嵌入方法对广泛的视觉理解的益处。BLIVA还在YouTube视频缩略图数据集上取得了92%的准确率。BLIVA识读图像文本的能力可应用于许多行业,如识别路牌、食品包装等。BLIVA有望改善现实世界中的多种应用。
项目网址:https://huggingface.co/datasets/mlpc-lab/YTTB-VQA
- 0000
- 0003
- 0000

 0000
0000- 0001