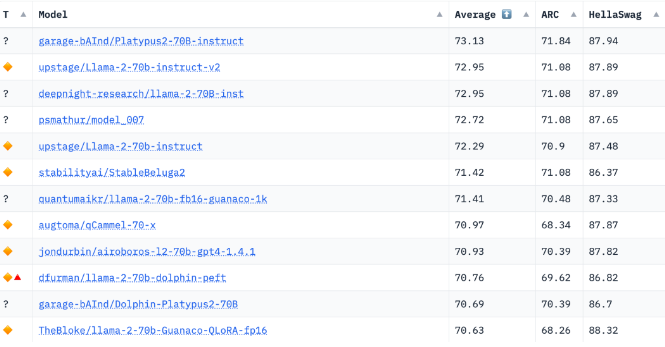
鸭嘴兽-70B登顶HuggingFace开源大模型排行榜
要点:
鸭嘴兽-70B使用优化过的数据集Open-Platypus训练,删除相似和重复问题。
应用LoRA和PEFT对模型进行微调,重点优化非注意力模块。
检查并解决测试数据泄漏和训练数据污染问题。
最近,来自波士顿大学的鸭嘴兽-70B模型登顶了HuggingFace的开源大模型排行榜,成为目前全球开源领域中表现最强的语言模型。鸭嘴兽的变强有以下三个关键原因:
首先,鸭嘴兽使用了一个经过优化的开源数据集Open-Platypus进行训练。该数据集由11个开源数据集组合而成,主要包含人工设计的问题,只有约10%的问题是由语言模型生成。同时,研究人员对数据集进行了处理,删除了相似和重复的问题,最大限度地减少了数据冗余。这有助于模型在更小的数据集上获取更强大的能力。
其次,研究人员使用了低秩逼近(LoRA)和参数高效微调(PEFT)对鸭嘴兽模型进行了微调。与完全微调不同,LoRA只训练转换层中的可训练参数,从而大大降低了计算训练成本。PEFT则主要微调了非注意力模块,如门控单元和上下采样模块,这进一步提升了模型性能。相比仅优化注意力模块,这种方法取得了更好的效果。

论文地址:https://arxiv.org/pdf/2308.07317.pdf
最后,研究人员深入探索了开放式语言模型训练中存在的数据污染问题,并针对鸭嘴兽的数据集进行了严格过滤。他们开发了一套启发式方法,仔细检查训练集中与测试集相似的问题,删除或以任何方式将其标记为潜在的测试数据泄露,避免了测试数据非故意地进入训练集,保证了模型评估的公平性。
通过数据集优化、模型微调技巧以及数据质量控制,鸭嘴兽-70B得以在众多开源大模型中脱颖而出,登上榜首。这为语言模型的训练提供了宝贵经验,也使开源社区对自主研发强大AI模型更具信心。如果社会各界能坚持开放创新、合作共赢的理念,我们离强人工智能的到来就不会太远了。
- 0000

 0000
0000

 0000
0000- 0000
- 0000