AI2发布大语言模型开源数据集Dolma 包含3万亿个token
站长网2023-08-25 10:54:080阅
文章概要:
1. AI2推出开源数据集Dolma,包含3万亿个token,来自各类网络内容、学术出版物等。
2. Dolma主要以英文文本为主,遵循开放许可,免费向研究人员开放。
3. Dolma作为开放语言模型OLMo的基础,OLMo计划2024年初发布。
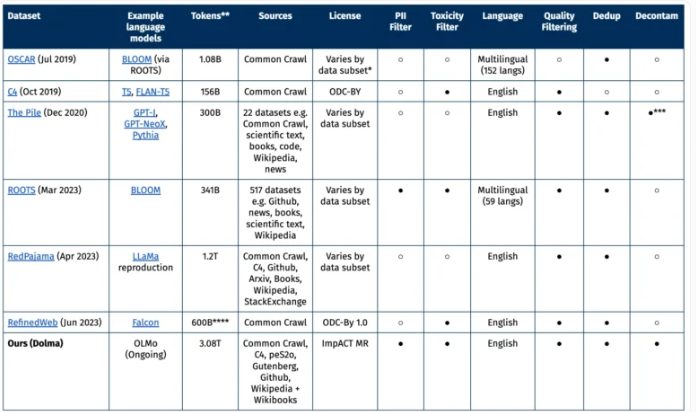
美国艾伦人工智能研究所(AI2)最近发布了一个名为Dolma的开源数据集,其包含了3万亿个token,这些词汇来自包括网络内容、学术出版物、代码和书籍等广泛的来源。Dolma是目前公开可用的同类数据集中最大的一个。

Dolma的数据将为AI2正在开发中的开放语言模型OLMo提供基础。OLMo的目标是成为“最好的开放语言模型”,计划于2024年初发布。为了开发OLMo,AI2构建了庞大的Dolma数据集。
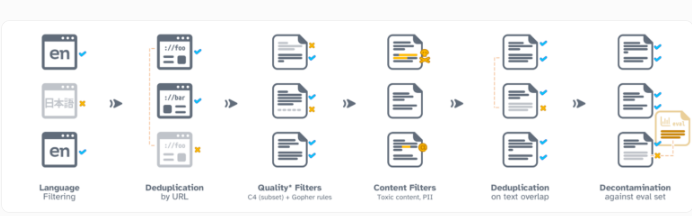
Dolma第一个版本主要以英文文本为主。研究人员使用语言识别模型对数据进行筛选。为弥补少数语言方言的偏差,团队将模型判断为英文置信度50%以上的所有文本都包括在内。未来版本将会包括其他语言。
Dolma以开放许可的形式免费向研究人员开放。研究人员需要提供联系信息并同意Dolma的预期用途。同时建立机制允许根据要求删除个人数据。
Dolma的数据大部分来自非营利的Common Crawl项目收集的网络数据。此外还包含其他网络页面、学术文本、代码示例、书籍等。
在AI2看来,理想的数据集应该满足几个标准:开放性、代表性、规模和再现性。它还应该最大限度地减少风险,尤其是那些可能影响个人的风险。
项目网址:https://huggingface.co/datasets/allenai/dolma
0000
评论列表
共(0)条相关推荐
- 0000
- 0000
 0000
0000- 0000
- 0000