LLaMA都在用的开源数据集惨遭下架:包含近20万本书,对标OpenAI数据集
开源数据集因侵权问题,惨遭下架。
如LLaMA、GPT-J等,都用它训练过。
如今,托管了它3年的网站,一夜之间删除了所有相关内容。
这就是Books3,一个由将近20万本图书组成的数据集,大小将近37GB。
丹麦一家反盗版组织表示,在该数据集中发现了150本其成员的书籍,构成侵权,所以要求平台下架。
现在该平台上的Books3网页链接已经“404”。
数据集的最初开发者无奈表示,Books3的下架是开源圈的一场悲剧。
Books3是什么?
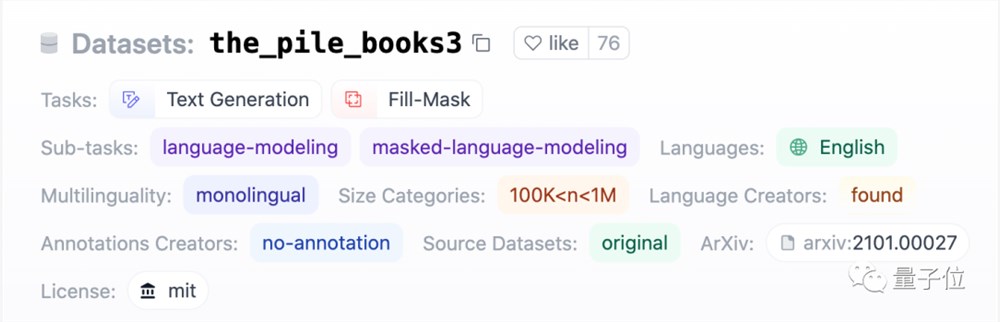
Books3在2020年发布,由AI开发者Shawn Presser上传,被收录在Eleuther AI的开源数据集Pile中。
它总计包含197000本书,包含来自盗版网站Bibliotik的所有书籍,意在对标OpenAI的数据集,但主打开源。
这也是Books3名字的来源之处——
GPT-3发布后,官方披露其训练数据集中15%的内容来自两个名为“Books1”、“Books2”的电子图书语料库,不过具体内容一直没有被透露。

开源的Books3则给更多项目提供了一个和OpenAI竞争的机会。
比如今年爆火的LLaMA、以及Eleuther AI的GPT-J等,都用上了Books3.
要知道,图书数据一直是大模型预训练中核心的语料素材,它能为模型输出高质量长文本提供参考。
很多AI巨头使用的图书数据集都是不开源,甚至是非常神秘的。比如Books1/2,关于其来源、规模的了解,更多都是各界猜测。由此,开源数据集对于AI圈内相当重要。
为了更方便获取,Books3被放到了The Eye上托管。这是一个可以存档信息、提取公开数据的平台。
而这一次惨遭下架,说的也是这一平台。
丹麦反盗版组织权利联盟向The Eye提出了下架请求,并且通过了。
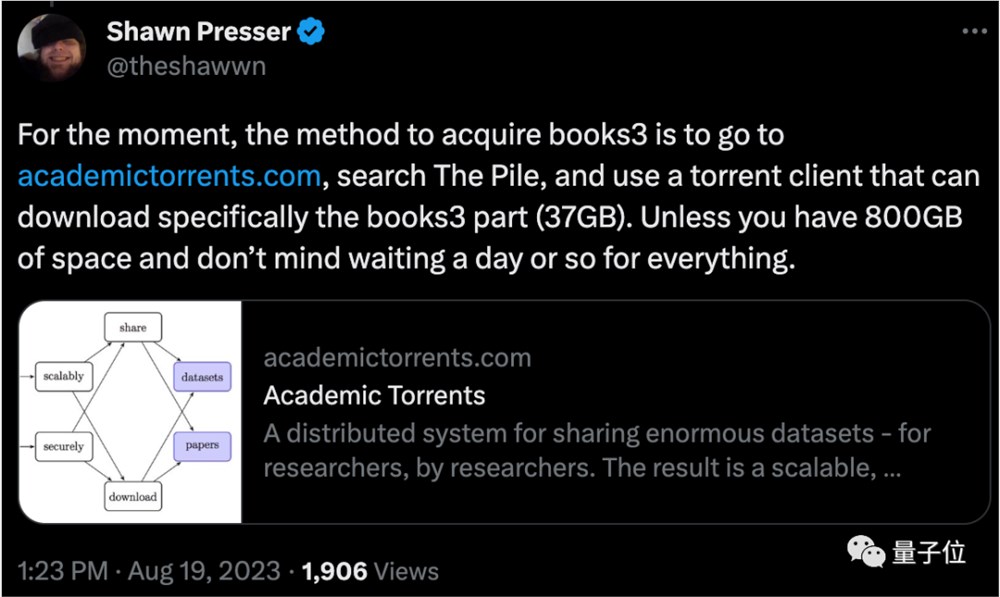
不过好消息是,Books3并没有完全消失,还是有其他办法获取的。
Wayback Machine上还有备份,或者可以从Torrent客户端下载。
作者老哥在推特上给出了多个方法。
“没有Books3就没法做自己的ChatGPT”
实际上,对于这次下架风波,数据集作者老哥有很多话想说。
他谈到,想要做出像ChatGPT一样的模型,唯一的方法就是创建像Books3这样的数据集。
每一个盈利性质的公司都在秘密做数据集,如果没有Books3,就意味着只有OpenAI等科技巨头才能访问这些图书数据,由此你将无法做出自己的ChatGPT。
在作者看来,ChatGPT就像是90年代的个人网站一样,任何人都能做是很关键的。
不过由于Books3很大一部分数据来自于盗版网站,所以作者也表示,希望之后能有人做出来比Books3更好的数据集,不仅提升数据质量,而且尊重书籍版权。
这种类似的情况在OpenAI也有发生。
一个多月以前,两位全职作者以未经允许擅自将作品用来训练ChatGPT,起诉了OpenAI。
而之所以会发生这种情况,很有可能是OpenAI的数据集Books2从影子图书馆(盗版网站)中获取了大量数据。
所以也有声音调侃说,AI不仅带来了新的技术突破,也给反盗版组织带来了新任务。
参考链接:
[1]https://www.theatlantic.com/technology/archive/2023/08/books3-ai-meta-llama-pirated-books/675063/
[2]https://gizmodo.com/anti-piracy-group-takes-ai-training-dataset-books3-off-1850743763
[3]https://interestingengineering.com/innovation/anti-piracy-group-shuts-down-books3-a-popular-dataset-for-ai-models
[4]https://torrentfreak.com/anti-piracy-group-takes-prominent-ai-training-dataset-books3-offline-230816/
—完—
- 0000
- 0000
 0000
0000- 0002
- 0000