西交大开源SadTalker模型 图片+音频秒变视频!
站长网2023-04-19 15:34:551阅
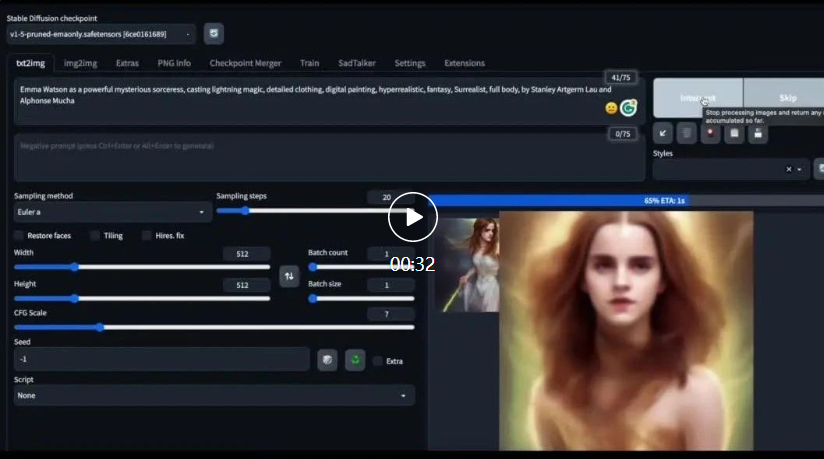
最近,西安交通大学的研究人员提出了SadTalker模型,通过从音频中学习生成3D运动系数,使用全新的3D面部渲染器来生成头部运动,可以实现图片 音频就能生成高质量的视频。

为了实现音频驱动的真实头像视频生成,研究人员将3DMM的运动系数视为中间表征,并将任务分为两个主要部分(表情和姿势),旨在从音频中生成更真实的运动系数(如头部姿势、嘴唇运动和眼睛眨动),并单独学习每个运动以减少不确定性。最后通过一个受face-vid2vid启发设计的3D感知的面部渲染来驱动源图像。
论文链接:https://arxiv.org/pdf/2211.12194.pdf
项目主页:https://sadtalker.github.io/
研究人员使用SadTalker模型从音频中学习生成3D运动系数,使用全新的3D面部渲染器来生成头部运动。该技术可以控制眨眼频率,音频可以是英文、中文、歌曲。
这项技术在数字人创作、视频会议等多个领域都有应用,能够让静态照片动起来,但目前仍然是一项非常有挑战性的任务。SadTalker模型的出现解决了生成视频的质量不自然、面部表情扭曲等问题。该技术可以应用于数字人创作、视频会议等多个领域。
0001
评论列表
共(0)条相关推荐
- 0001


 0000
0000- 0000
- 0000
- 0001