一句话让AI训练AI!20分钟微调羊驼大模型,从数据收集到训练全包了
只需一句话,描述你想要大模型去做什么。
就有一系列AI自己当“模型训练师”,帮你完成从生成数据集到微调的所有工作。
比如让70亿参数羊驼大模型学会优化GPT-4提示词,整个过程只要20分钟。
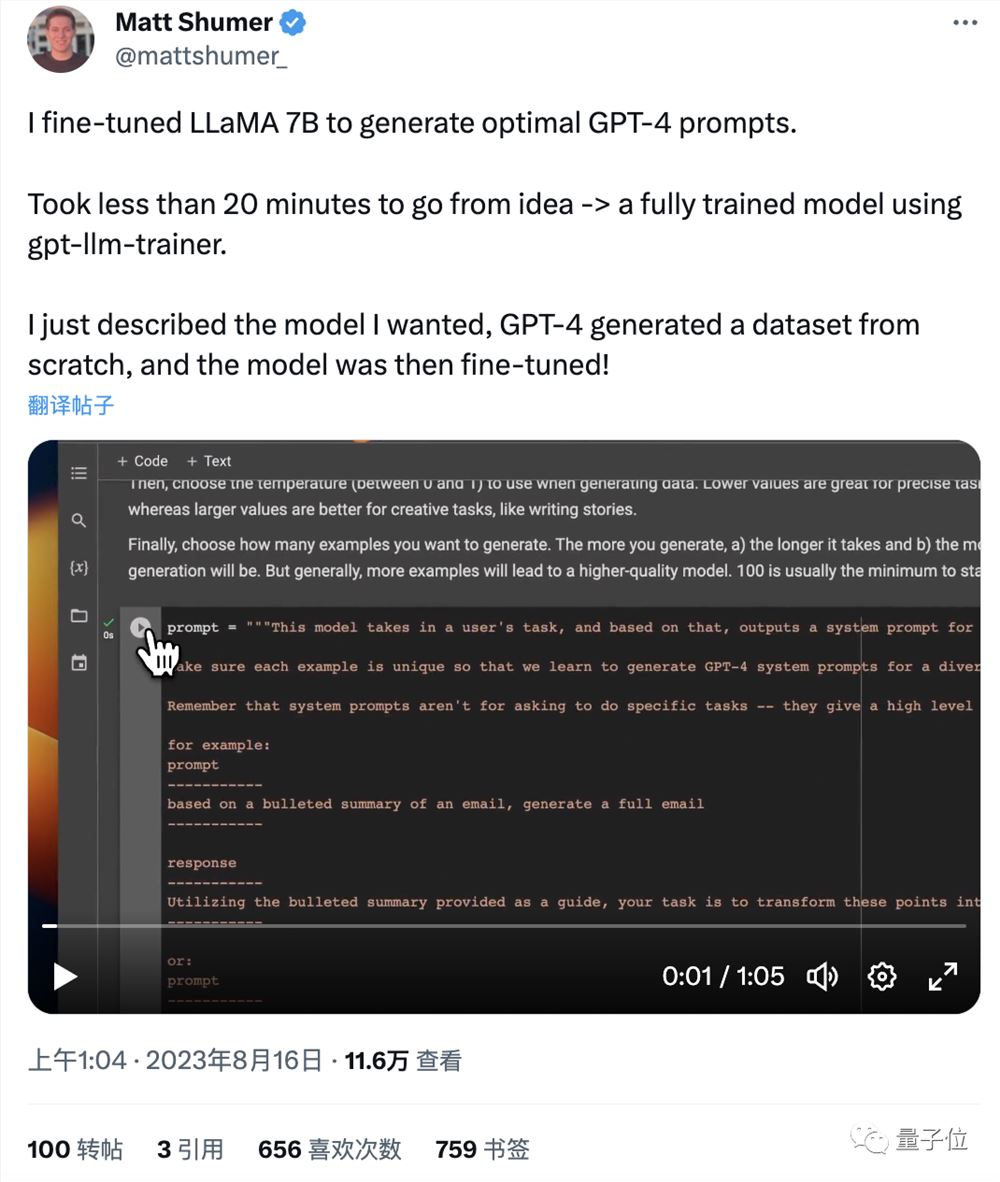
秘诀就是网友分享的一个可以帮咱自动训练模型的AI工具:
它能帮你搞定数据收集、写代码等一系列操作,你要做的就是用人话描述你要什么,然后坐等即可。
可能是全世界最简单的大模型微调方法了(手动狗头)。
并且成本也不高,羊驼这个例子花费就不超15美元(合100来块人民币)。
好消息,小哥已将它直接开源(GitHub1k标星),你也可以试试。
AI模型训练师操作指南
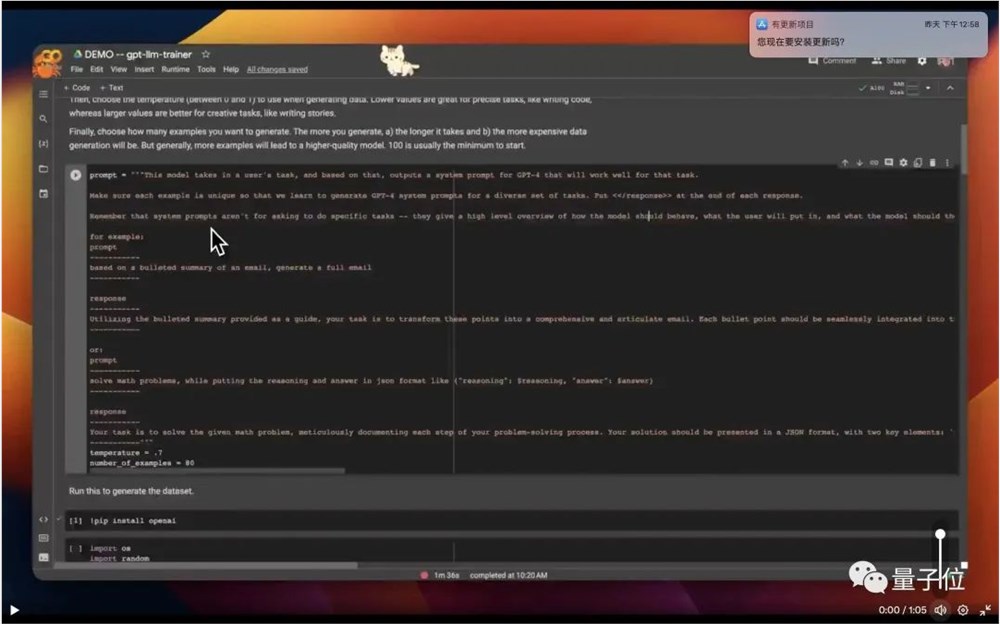
如上图所示,此工具名叫gpt-llm-trainer。
如果你也想用它来自动微调某个大模型,首先需要准备:
1、Google Colab或者本地Jupyter notebook;
2、如果选前者,请切换到可用的最佳GPU(执行“Runtime -> change runtime type”);
3、以及一个OpenAI API key(主要还是用的GPT-4能力)。
然后就可以进入具体操作了:
1、先写你的提示词,也就是你希望这个微调后的模型需要具备什么功能。
可以肯定的是,描述得越清晰越好。
比如开头的羊驼例子,作者就给了这么一大段(红字部分):
官方也给了一个简单的示例:
A model that takes in a puzzle-like reasoning-heavy question in English, and responds with a well-reasoned, step-by-step thought out response in Spanish.
2、设定两个值:
(1)temperature,生成数据集的“温度”(取值0-1),值越高代表创意性越强,越低代表越精确;
(2)number_of_examples,要生成的示例数量,推荐从100开始。
3、无脑“下一步”,运行所有cell,完成“生成数据集”、“自动分为训练集和验证集”、“安装各种必备库”、“定义超参数”、“加载数据集并训练”这一系列自动步骤。
之后,你就能得到一个微调好的新模型了。
需要注意的是,这个过程可能在10分钟到几个小时不等,取决于你设置的示例生成数量。
4、最后执行“Run Inference”测试效果,完毕。
相当简单有没有。
值得一提的是,作者已经盘点出了一些待改进的地方,比如:
改进示例生成pipeline,让生成效率更高,成本更低;
添加示例修剪功能,删除相似的样本从而提高性能;
根据示例和数据集的详细信息(比如示例数量),利用GPT-4自动选择超参数,甚至是要微调的模型;
训练多个变体,推出评估损失(eval loss)最少的那个;
……
大家也可以浅浅期待一波。
如此神器,出自谁手?
我们简单挖了一下,发现作者的来头还不小。
他叫Matt Shumer,推特粉丝1.7万。
Matt自己开了家公司,产品名叫HyperWriteAI。
这是一个厉害的浏览器操作agent,可以像人一样操作谷歌浏览器来完成一系列任务,比如订披萨。
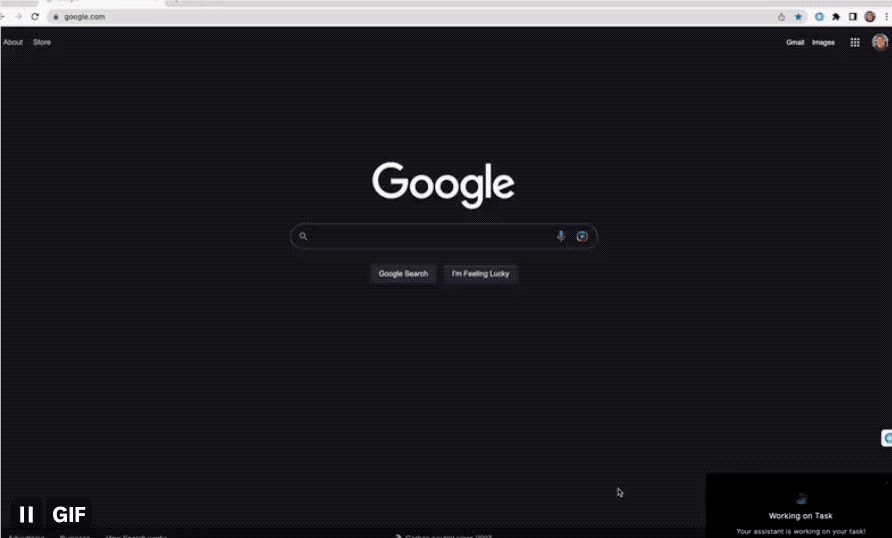
和gpt-llm-trainer一样,你只需要用文字描述目标,它就会一边列步骤,一边执行。
号称“比AutoGPT强”——
目前,HyperWriteAI已经可以在谷歌扩展程序中安装了,显示用户已达10w 。

最后,我们翻看这位大佬的推特,发现他当天最新的一条推文是:
几周之后,大语言模型的前景就可能要变天了。

可能又在酝酿什么大动作?(手动狗头)
更新:大佬又发了一个类似的自动工具,名叫gpt-oracle-trainer。
只需上传一个产品文档,就能自动训练出一个可以回答有关该产品问题的聊天机器人。
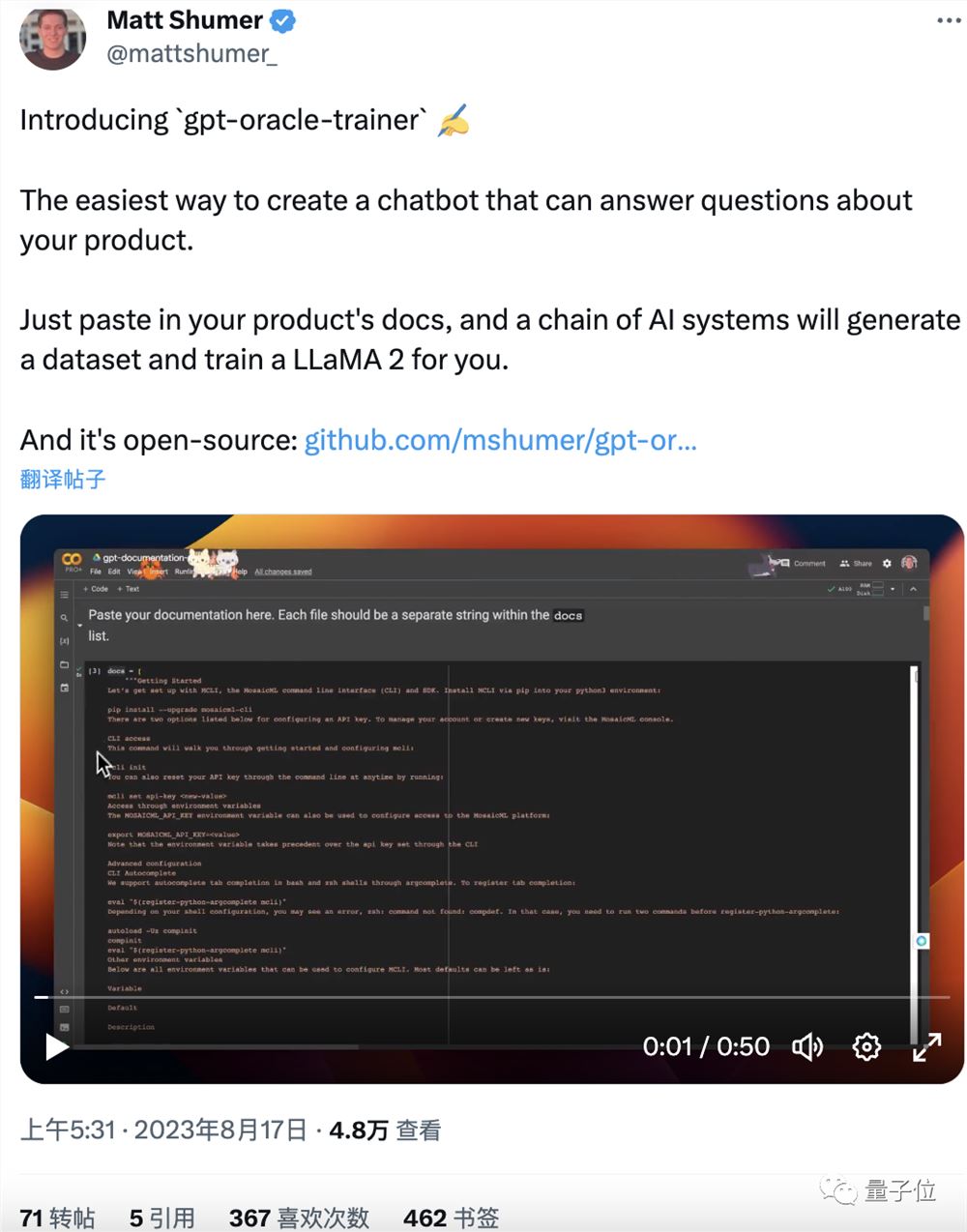
友情链接:
[1]https://github.com/mshumer/gpt-llm-trainer
[2]https://github.com/mshumer/gpt-oracle-trainer

 0000
0000- 0000
- 0000

 0000
0000
 0000
0000