谷歌认真起来,就没 OpenAI 什么事了!创始人亲自组队创建“杀手级”多模态 AI 模型
谷歌正在计划如何利用即将推出的大型语言模型系列 Gemini 来取代 ChatGPT。
截至目前,OpenAI 大语言模型在 AI 竞赛中一直处于领先地位。而强劲优势的背后,离不开微软庞大数据中心基础设施的有力支持。但 ChatGPT 的主导地位恐怕无法长久持续下去,因为新的、更强大的 AI 模型正不断涌现,而其中最具战斗力的挑战者就来自谷歌。
今年4月,Alphabet 首席执行官桑达尔·皮查伊 (Sundar Pichai) 迈出了不寻常的一步:合并两个具有不同文化和代码的大型人工智能团队(谷歌 Brain 和 DeepMind 团队),以赶上并超越 OpenAI 和其他竞争对手。
现在,检验这个团队工作成果的时刻即将到来。有消息称,这支数百人组成的团队将在今年秋天发布一组大型机器学习模型 Gemini,这是该公司有史以来构建的风险最高的产品之一。据参与 Gemini 开发的人士透露,这些模型统称为 Gemini,预计将使谷歌能够制造出竞争对手无法制造的产品。
谷歌 Gemini 于今年5月在 I/O 开发者大会上首度亮相。
当时,谷歌称 Gemini 为其下一代基础模型,它仍在训练中。Gemini 是从一开始就以多模式、高效的工具和 API 集成为目标而创建的,旨在支持未来的创新,例如内存和规划。经过微调和严格的安全测试后,Gemini 将提供各种尺寸和功能,就像 PaLM2一样。
全世界都在关心的 Gemini 到底是个啥?
早在2016年,DeepMind 就因其人工智能程序 AlphaGo 在复杂的围棋游戏中击败了一位冠军选手而成为头条新闻。快进到今天,DeepMind 首席执行官 Demis Hassabis 透露,他的团队正在利用 AlphaGo 的变革性技术来创建 Gemini AI。Demis Hassabis 透露,Gemini AI 的开发成本估计为数亿美元,使用了数万颗谷歌的 TPU AI 芯片进行训练。
据悉,Gemini AI 是一个类似于 ChatGPT 的 GPT-4的大规模语言模型。然而,Hassabis 和他的团队更进一步,为 Gemini AI 注入了源自 AlphaGo 的解决问题能力和战略规划能力。
从根本上讲,Gemini AI 包含下一代 AI 架构,有望取代 Google 当前的 AI 模型 PaLM2。该模型目前支持 Google 的一系列 AI 服务,例如 Workspace 应用程序中广泛使用的 Duet AI 和流行的 Bard 聊天机器人。
谷歌还放出消息,称 Gemini 将为旗下 AI 聊天机器人 Bard,以及 Google Docs、Slides 等企业级应用提供支持。
The Information 报道称,谷歌并不是简单地与 ChatGPT 等产品竞争,而是打算超越一众大模型产品让友商们无法望其项背。消息人士指出,该公司专注于将大型语言模型 (LLM) 的文本功能与人工智能图像生成相结合,以创建多功能产品。这意味着 Gemini 不仅能够像 ChatGPT 那样生成文本,还能够创建上下文图像,但据报道,谷歌也在考虑添加其他功能。例如,用户最终可能能够使用 Gemini 通过语音分析流程图或控制软件。
Gemini 之所以能够成为强大的竞争对手,是因为谷歌同样掌握着雄厚的资源储备,特别是用于训练 AI 模型的宝贵数据。谷歌能够访问 YouTube 视频、谷歌图书、庞大的搜索索引以及 Google Scholar 上的学术资料。其中大部分数据为谷歌所独有,这也使其在构建顶尖 AI 模型方面占据着超越其他厂商的优势。
那么,Gemini 在训练中,具体都用到了哪些数据集?
Gemini 用到了哪些数据集?
据悉,Gemini 项目汲取了谷歌多个项目的数据集来训练大模型,包括了 Google Piper monorepo、DeepMind MassiveText 以及 YouTube 中的数据。
来自 Google Piper monorepo 的 Gemini 数据集(估计)
Gemini 数据集可能由大量代码组成,以支持最终训练模型中的推理。Google 的内部 monorepo Piper 大小为86TB 。使用 The Pile 的每字节0.4412个令牌的计算,该数据集将约为37.9T 个令牌,或者大约是 GPT-4中下一个最大数据集大小的两倍(估计)。
来自 DeepMind MassiveText 的 Gemini 数据集(估计)
Gemini 数据集可能由 DeepMind 的一些 MassiveText(多语言)5T 令牌数据集组成请注意,下表是关于 Gemini 数据集的猜测(未经 Google DeepMind 确认),并且基于来自最先进的 DeepMind MassiveText(多语言) 1,000B 讨论令牌的可用信息。MassiveText 包括网页、书籍、新闻和代码等文本,包含约23.5亿个文档,10.5TB 的文本量。
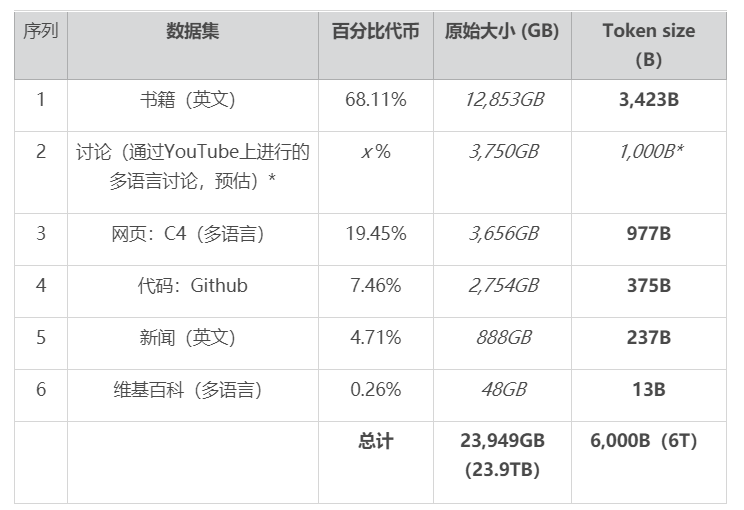
MassiveText 多语言数据集估计。
*四舍五入大概的数据以粗体显示(来自 DeepMind 的 MassiveText 多语言数据集),确定的数据以斜体显示。
来自 YouTube 的 Gemini 数据集(估计)
据一位知情人士透露,谷歌的研究人员一直在使用 YouTube 来开发其下一个大型语言模型 Gemini。
YouTube2023总体统计数据(来自 Wyzowl 和 Statista):
视频总数:8亿。
平均长度:11.7分钟。
总时间:93.6亿分钟。
四舍五入以跟上每小时上传30,000小时的速度:10B 分钟。
YouTube2023文本统计数据:
人类说话速度:每分钟150个单词 (wpm)。
150wpm x10B 分钟 = 总计1.5万亿字。
假设:(1) 说话仅出现在视频的子集中,(2) 质量分类器保留分数位于前80% 的视频,那么我们保留其中的80%。
1.5T 字 x0.8=1.2T 字。
1.2T 单词 x1.3=1.56T 文本标记。
1.5T 文本令牌不足以大幅降低 Gemini 或 GPT-5规模模型的要求:
1T 参数(20T 文本令牌)。
2T 参数(40T 文本标记)。
5T 参数(100T 文本令牌)。
鉴于2023-2024年大型语言模型对多模态的关注,可以假设视觉内容(不仅仅是文本)正在用于训练这些模型。
在将 YouTube 上的音频、视频数据注入 Gemini 数据集中后,Gemini 模型就具有了多模态能力,比如,根据 YouTube 视频训练的模型,可以帮助需要的人根据视频解决一些实际动手问题。
使用 YouTube 内容,还可以帮助谷歌开发更先进的文本转视频软件,根据用户想看的内容描述,自动生成详细的视频。
Google DeepMind 在 Piper(其86TB monorepo)中的迭代代码上训练大模型(DIDACT)。使用 The Pile 的每字节0.4412个令牌的计算,该数据集将约为37.9T 个令牌,大约是 GPT-4中下一个最大数据集大小的两倍(预估)。这意味着训练 Gemini 不会出现传闻中的数据匮乏的情况。
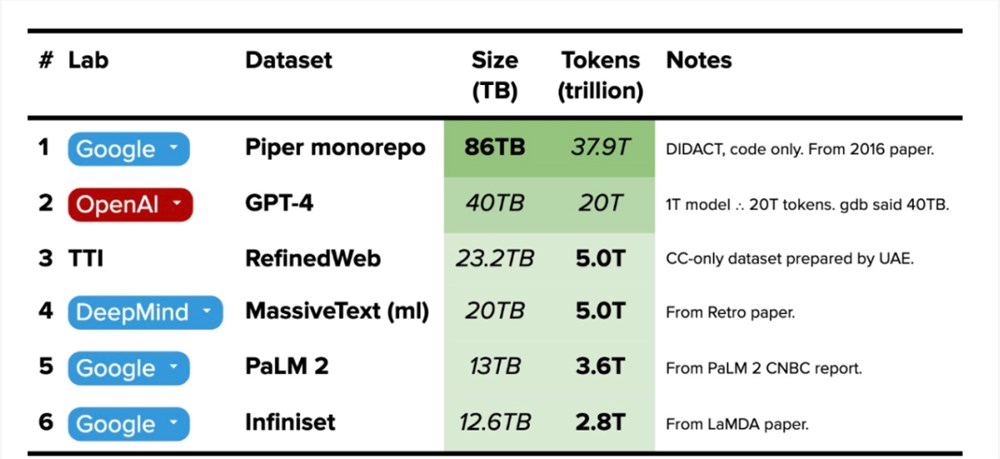
2023年最大数据集列表(截至2023年6月)
四舍五入大概的数据以粗体显示,确定的数据以斜体显示。
据称与 GPT-4不同,Gemini 将是首个能够同时处理视频、文本和图像的多模态模型。有报告表明,Gemini 接受的训练令牌数量是 GPT-4的两倍,是 PaLM2的10倍。
Gemini GPT-4等于 AGI?
Google Gemini 是一种多模式工具和 API 集成,旨在将 GPT-4等语言模型与 AlphaGo 中使用的技术相结合,以增强其能力,例如规划和解决问题。
比如,目前 GPT-4等大语言模型的缺陷主要体现在两方面:第一,是结果高度依赖训练语料,如果语料存在偏见或错误,那么大语言模型生成的结果也会是错误的;第二,是大语言模型可能会出现幻觉,给出完全不符合常识的错误信息,这主要是因为大语言模型只具备当前训练语料的知识,缺乏对真实世界全面而准确的理解。
Gemini 作为先进的数学定理证明系统,与 GPT4等大型语言模型相结合,有可能解决人工智能模型中搜索和规划的弱点,并生成新的定理。有专家预测,该模型可以在五年内达到 MMLU 基准的100分。
谷歌在构建和训练大语言模型方面还有着深厚的人才池和多年实践经验。除了预计于明年秋季发布的新模型之外,谷歌还有意发布由 Gemin 驱动的新聊天机器人,或者借此升级现有 Bard 聊天机器人。照惯例来看,新模型应该会通过 Google Cloud 对外发布,这无疑会对谷歌的云业务产生深远的积极影响。
Gemini 在上月谷歌开发者大会上首度亮相时曾遭嘲笑,期间谷歌展示的几个 AI 项目也未受认可。
谷歌称,Gemini 项目的下一代 AI 模型最早将于今年秋季推出。
联合创始人谢尔盖·布林躬身入局,组建研发团队
在将谷歌 Brain 和 DeepMind 两大 AI 部门合并时,掌门人皮查伊称是为了提高部门运作效率,将谷歌庞大的计算资源同 DeepMind 的研究技能结合起来。
消息人士指出,谷歌大脑和 DeepMind 团队的几位前成员目前正在研究 Gemini。其中包括 Google 高级研究员 Paul Barham 和 DeepMind 的 Tom Hennigan,后者专注于 Gemini 的基础设施。然而,最引人注目的团队成员可能是谷歌联合创始人谢尔盖·布林 (Sergey Brin)。
据报道,2022年底,布林开始更频繁地进入谷歌办公室。在谷歌于2022年底因 OpenAI 失去研究人员后,人们认为布林正在专注于 Gemini 的招聘流程。现在,消息人士称,他在评估和训练 Gemini 模型方面发挥了重要作用。
在此之前,两大部门也分别对 ChatGPT 做出了自己的回应。DeepMind 这边有 Goodall 项目,使用了一种名为 Chipmunk 的未公开模型,另一部门则拿出基于 Google Brain 模型的 Bard。尽管双方之间存在一定竞争,DeepMind 还是决定放弃 Goodall,转而在 Gemini 上携手合作。
3ChatGPT 的统治将就此终结?
事实上,Google Brain 和 DeepMind 的通力合作必然给 OpenAI 及其他竞争对手带来麻烦。当然,谷歌具体如何打造 Gemini 才是决定性因素。报道表明,Gemini 在多模态能力方面取得了显著进步,切实超越了以往模型。其设计侧重于多模态,意味着它能够理解和处理多种不同形式数据,并在工具与 API 集成方面极为高效。
具体来讲,Gemini 不仅擅长理解和生成会话文本,而且精通处理多种其他输入,例如文本、图像和视频。另有报道表明,Gemini 能够接收的 token 数量可达 GPT-4的两倍,这应该能够支撑起更强的智能度优势。

随着生成式人工智能竞争格局的加剧,谷歌准备通过推出 Gemini AI 来展示其真正的能力。谷歌从匆忙引入 Bard 中汲取了宝贵的经验教训,决心确保无懈可击地进入市场。预计到2030年,生成式人工智能市场将达到1093.7亿美元,投资者和客户热情高涨,加剧了主导地位的争夺。谷歌着眼于彻底改变行业,已准备好释放 Gemini AI 的全部潜力,塑造文本分析人工智能解决方案的未来。
原文链接:
https://indianexpress.com/article/technology/artificial-intelligence/google-gemini-ai-fall-launch-chatgpt-edge-8896455/lite/
https://www.androidpolice.com/google-ai-gemini-chatbot/
https://www.theinformation.com/articles/the-forced-marriage-at-the-heart-of-googles-ai-race?irclickid=XepQ8kzcBxyPURYQqf1uq0VoUkF3jszhq2PuWY0&irgwc=1&utm_source=affiliate&utm_medium=cpa&utm_campaign=10078-Skimbit%20Ltd.&utm_term=androidpolice.com
https://insights.daffodilsw.com/blog/google-gemini-algorithm-the-next-level-ai-model
https://lifearchitect.ai/gemini/
- 0000

 0000
0000- 0000
- 0000
- 0000